 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Creating Backgrounds Then Rendering Texts: A New Paradigm for Visual Text Blending
Paper and Code
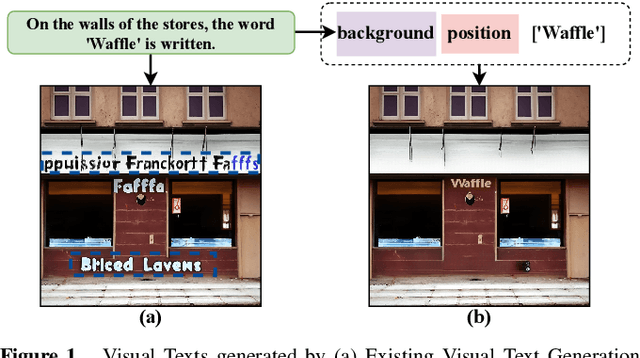

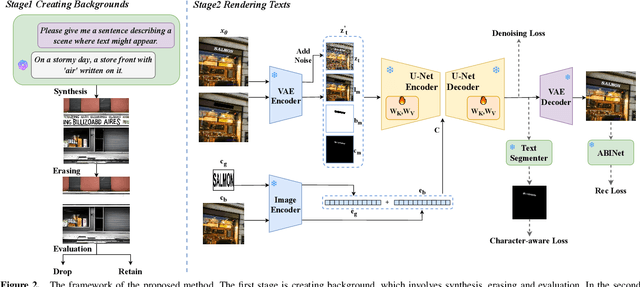
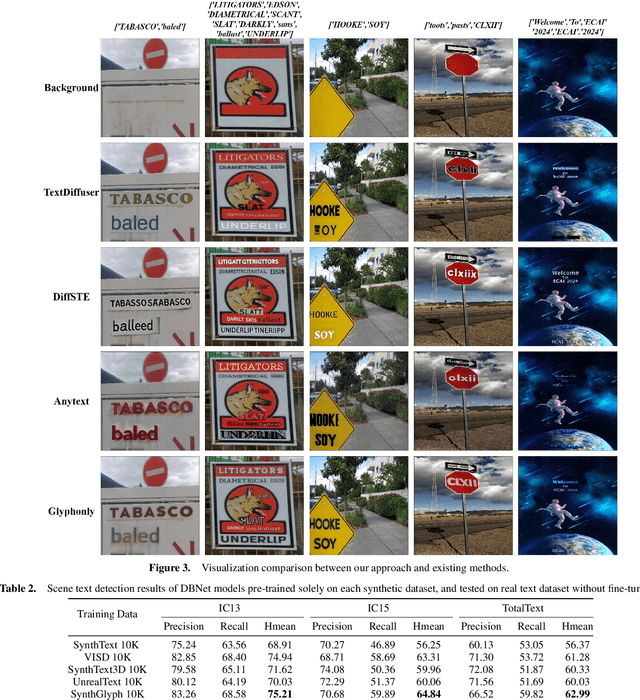
Diffusion models, known for their impressive image generation abilities, have played a pivotal role in the rise of visual text generation. Nevertheless, existing visual text generation methods often focus on generating entire images with text prompts, leading to imprecise control and limited practicality. A more promising direction is visual text blending, which focuses on seamlessly merging texts onto text-free backgrounds. However, existing visual text blending methods often struggle to generate high-fidelity and diverse images due to a shortage of backgrounds for synthesis and limited generalization capabilities. To overcome these challenges, we propose a new visual text blending paradigm including both creating backgrounds and rendering texts. Specifically, a background generator is developed to produce high-fidelity and text-free natural images. Moreover, a text renderer named GlyphOnly is designed for achieving visually plausible text-background integration. GlyphOnly, built on a Stable Diffusion framework, utilizes glyphs and backgrounds as conditions for accurate rendering and consistency control, as well as equipped with an adaptive text block exploration strategy for small-scale text rendering. We also explore several downstream applications based on our method, including scene text dataset synthesis for boosting scene text detectors, as well as text image customization and editing. Code and model will be available at \url{https://github.com/Zhenhang-Li/GlyphOnly}.