 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Model Predictive Control
Feb 23, 2021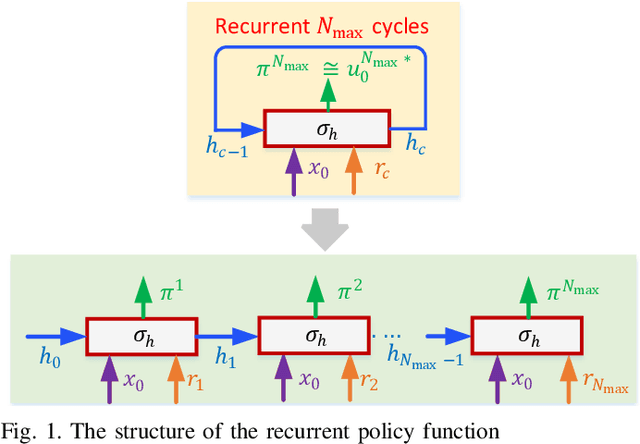



This paper proposes an off-line algorithm, called Recurrent Model Predictive Control (RMPC), to solve general nonlinear finite-horizon optimal control problems. Unlike traditional Model Predictive Control (MPC) algorithms, it can make full use of the current computing resources and adaptively select the longest model prediction horizon. Our algorithm employs a recurrent function to approximate the optimal policy, which maps the system states and reference values directly to the control inputs. The number of prediction steps is equal to the number of recurrent cycles of the learned policy function. With an arbitrary initial policy function, the proposed RMPC algorithm can converge to the optimal policy by directly minimizing the designed loss function. We further prove the convergence and optimality of the RMPC algorithm thorough Bellman optimality principle, and demonstrate its generality and efficiency using two numerical examples.
Deep adaptive dynamic programming for nonaffine nonlinear optimal control problem with state constraints
Nov 26, 2019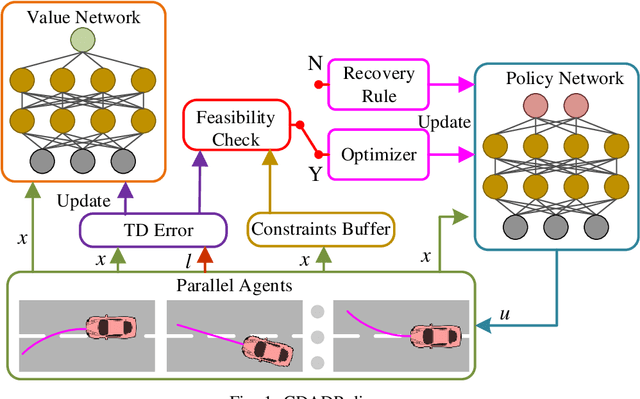


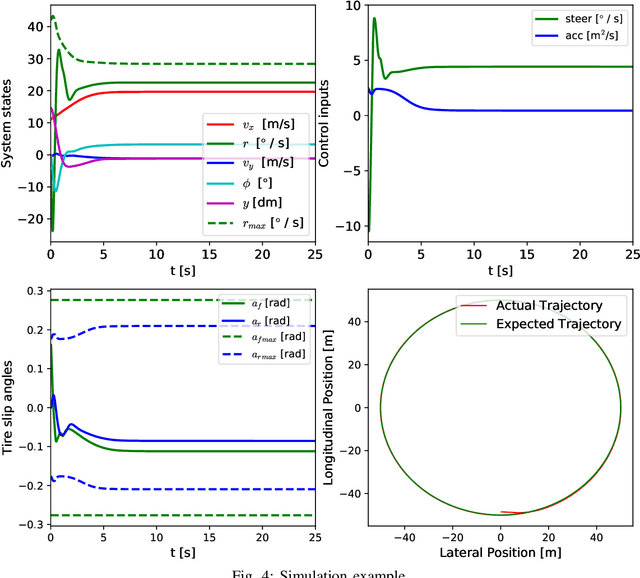
This paper presents a constrained deep adaptive dynamic programming (CDADP) algorithm to solve general nonlinear optimal control problems with known dynamics. Unlike previous ADP algorithms, it can directly deal with problems with state constraints. Both the policy and value function are approximated by deep neural networks (NNs), which directly map the system state to action and value function respectively without needing to use hand-crafted basis function. The proposed algorithm considers the state constraints by transforming the policy improvement process to a constrained optimization problem. Meanwhile, a trust region constraint is added to prevent excessive policy update. We first linearize this constrained optimization problem locally into a quadratically-constrained quadratic programming problem, and then obtain the optimal update of policy network parameters by solving its dual problem. We also propose a series of recovery rules to update the policy in case the primal problem is infeasible. In addition, parallel learners are employed to explore different state spaces and then stabilize and accelerate the learning speed. The vehicle control problem in path-tracking task is used to demonstrate the effectiveness of this proposed method.
Generalized Policy Iteration for Optimal Control in Continuous Time
Sep 11, 2019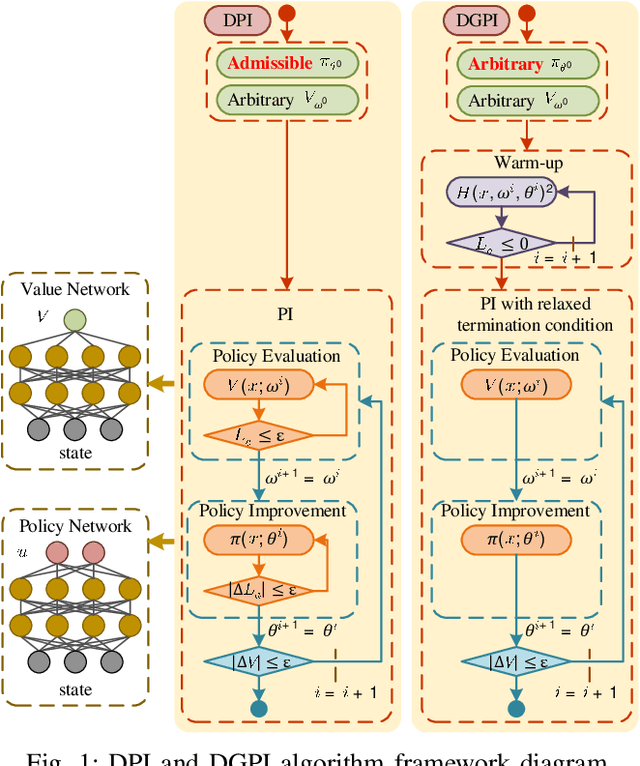
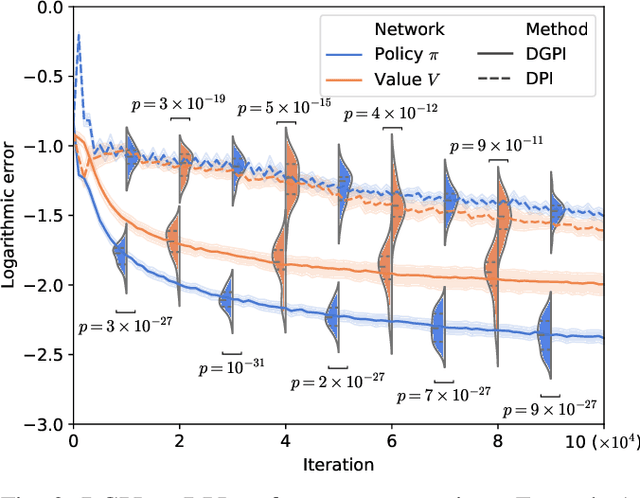
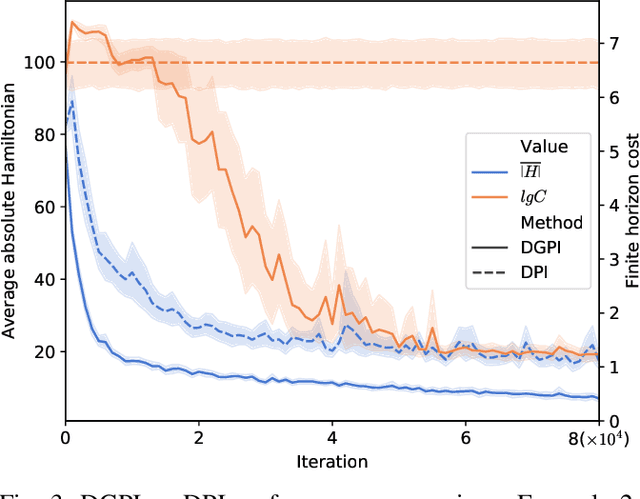
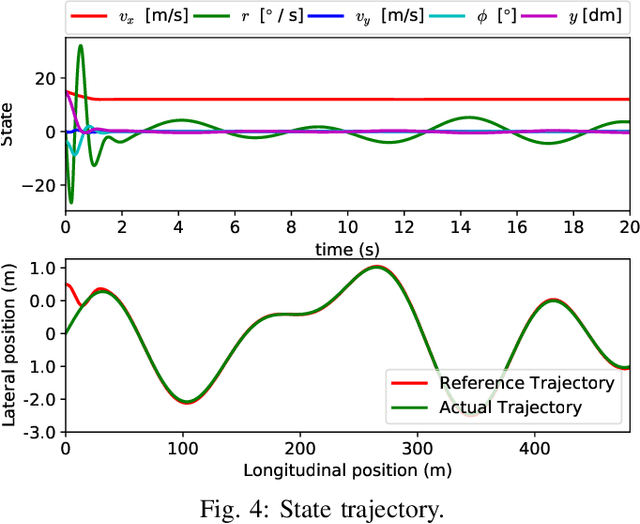
This paper proposes the Deep Generalized Policy Iteration (DGPI) algorithm to find the infinite horizon optimal control policy for general nonlinear continuous-time systems with known dynamics. Unlike existing adaptive dynamic programming algorithms for continuous time systems, DGPI does not require the admissibility of initialized policy, and input-affine nature of controlled systems for convergence. Our algorithm employs the actor-critic architecture to approximate both policy and value functions with the purpose of iteratively solving the Hamilton-Jacobi-Bellman equation. Both the policy and value functions are approximated by deep neural networks. Given any arbitrary initial policy, the proposed DGPI algorithm can eventually converge to an admissible, and subsequently an optimal policy for an arbitrary nonlinear system. We also relax the update termination conditions of both the policy evaluation and improvement processes, which leads to a faster convergence speed than conventional Policy Iteration (PI) methods, for the same architecture of function approximators. We further prove the convergence and optimality of the algorithm with thorough Lyapunov analysis, and demonstrate its generality and efficacy using two detailed numerical examples.