 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Diverse Perspectives: A Multi-Agent Framework for Enhanced Error Detection in Knowledge Graphs
Jan 27, 2025



Knowledge graphs are widely used in industrial applications, making error detection crucial for ensuring the reliability of downstream applications. Existing error detection methods often fail to effectively leverage fine-grained subgraph information and rely solely on fixed graph structures, while also lacking transparency in their decision-making processes, which results in suboptimal detection performance. In this paper, we propose a novel Multi-Agent framework for Knowledge Graph Error Detection (MAKGED) that utilizes multiple large language models (LLMs) in a collaborative setting. By concatenating fine-grained, bidirectional subgraph embeddings with LLM-based query embeddings during training, our framework integrates these representations to produce four specialized agents. These agents utilize subgraph information from different dimensions to engage in multi-round discussions, thereby improving error detection accuracy and ensuring a transparent decision-making process. Extensive experiments on FB15K and WN18RR demonstrate that MAKGED outperforms state-of-the-art methods, enhancing the accuracy and robustness of KG evaluation. For specific industrial scenarios, our framework can facilitate the training of specialized agents using domain-specific knowledge graphs for error detection, which highlights the potential industrial application value of our framework. Our code and datasets are available at https://github.com/kse-ElEvEn/MAKGED.
Can Large Language Models Understand DL-Lite Ontologies? An Empirical Study
Jun 25, 2024Large language models (LLMs) have shown significant achievements in solving a wide range of tasks. Recently, LLMs' capability to store, retrieve and infer with symbolic knowledge has drawn a great deal of attention, showing their potential to understand structured information. However, it is not yet known whether LLMs can understand Description Logic (DL) ontologies. In this work, we empirically analyze the LLMs' capability of understanding DL-Lite ontologies covering 6 representative tasks from syntactic and semantic aspects. With extensive experiments, we demonstrate both the effectiveness and limitations of LLMs in understanding DL-Lite ontologies. We find that LLMs can understand formal syntax and model-theoretic semantics of concepts and roles. However, LLMs struggle with understanding TBox NI transitivity and handling ontologies with large ABoxes. We hope that our experiments and analyses provide more insights into LLMs and inspire to build more faithful knowledge engineering solutions.
DNG: Taxonomy Expansion by Exploring the Intrinsic Directed Structure on Non-Gaussian Space
Feb 22, 2023Taxonomy expansion is the process of incorporating a large number of additional nodes (i.e., "queries") into an existing taxonomy (i.e., "seed"), with the most important step being the selection of appropriate positions for each query. Enormous efforts have been made by exploring the seed's structure. However, existing approaches are deficient in their mining of structural information in two ways: poor modeling of the hierarchical semantics and failure to capture directionality of is-a relation. This paper seeks to address these issues by explicitly denoting each node as the combination of inherited feature (i.e., structural part) and incremental feature (i.e., supplementary part). Specifically, the inherited feature originates from "parent" nodes and is weighted by an inheritance factor. With this node representation, the hierarchy of semantics in taxonomies (i.e., the inheritance and accumulation of features from "parent" to "child") could be embodied. Additionally, based on this representation, the directionality of is-a relation could be easily translated into the irreversible inheritance of features. Inspired by the Darmois-Skitovich Theorem, we implement this irreversibility by a non-Gaussian constraint on the supplementary feature. A log-likelihood learning objective is further utilized to optimize the proposed model (dubbed DNG), whereby the required non-Gaussianity is also theoretically ensured. Extensive experimental results on two real-world datasets verify the superiority of DNG relative to several strong baselines.
VSE-ens: Visual-Semantic Embeddings with Efficient Negative Sampling
Aug 11, 2018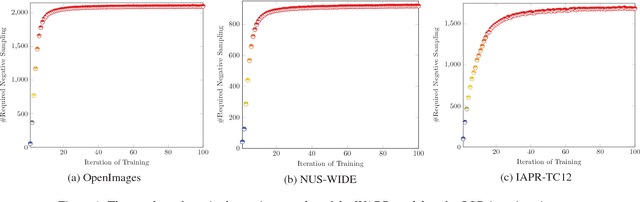
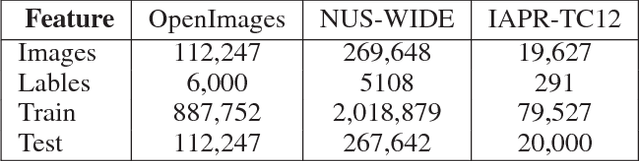
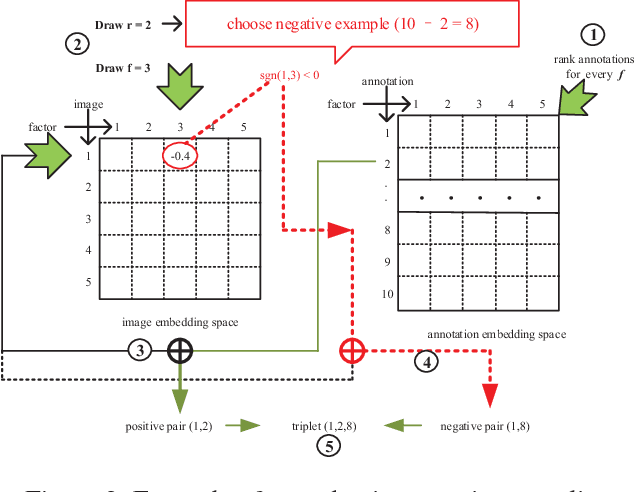
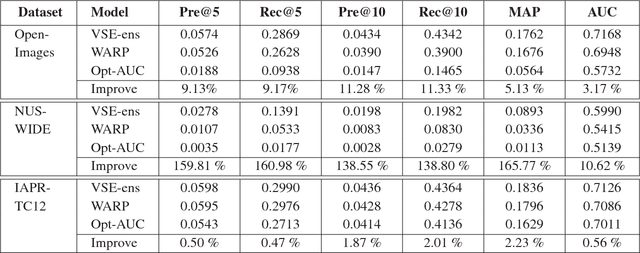
Jointing visual-semantic embeddings (VSE) have become a research hotpot for the task of image annotation, which suffers from the issue of semantic gap, i.e., the gap between images' visual features (low-level) and labels' semantic features (high-level). This issue will be even more challenging if visual features cannot be retrieved from images, that is, when images are only denoted by numerical IDs as given in some real datasets. The typical way of existing VSE methods is to perform a uniform sampling method for negative examples that violate the ranking order against positive examples, which requires a time-consuming search in the whole label space. In this paper, we propose a fast adaptive negative sampler that can work well in the settings of no figure pixels available. Our sampling strategy is to choose the negative examples that are most likely to meet the requirements of violation according to the latent factors of images. In this way, our approach can linearly scale up to large datasets. The experiments demonstrate that our approach converges 5.02x faster than the state-of-the-art approaches on OpenImages, 2.5x on IAPR-TCI2 and 2.06x on NUS-WIDE datasets, as well as better ranking accuracy across datasets.