 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNG: Taxonomy Expansion by Exploring the Intrinsic Directed Structure on Non-Gaussian Space
Feb 22, 2023Taxonomy expansion is the process of incorporating a large number of additional nodes (i.e., "queries") into an existing taxonomy (i.e., "seed"), with the most important step being the selection of appropriate positions for each query. Enormous efforts have been made by exploring the seed's structure. However, existing approaches are deficient in their mining of structural information in two ways: poor modeling of the hierarchical semantics and failure to capture directionality of is-a relation. This paper seeks to address these issues by explicitly denoting each node as the combination of inherited feature (i.e., structural part) and incremental feature (i.e., supplementary part). Specifically, the inherited feature originates from "parent" nodes and is weighted by an inheritance factor. With this node representation, the hierarchy of semantics in taxonomies (i.e., the inheritance and accumulation of features from "parent" to "child") could be embodied. Additionally, based on this representation, the directionality of is-a relation could be easily translated into the irreversible inheritance of features. Inspired by the Darmois-Skitovich Theorem, we implement this irreversibility by a non-Gaussian constraint on the supplementary feature. A log-likelihood learning objective is further utilized to optimize the proposed model (dubbed DNG), whereby the required non-Gaussianity is also theoretically ensured. Extensive experimental results on two real-world datasets verify the superiority of DNG relative to several strong baselines.
CATERPILLAR: Coarse Grain Reconfigurable Architecture for Accelerating the Training of Deep Neural Networks
Jun 08, 2017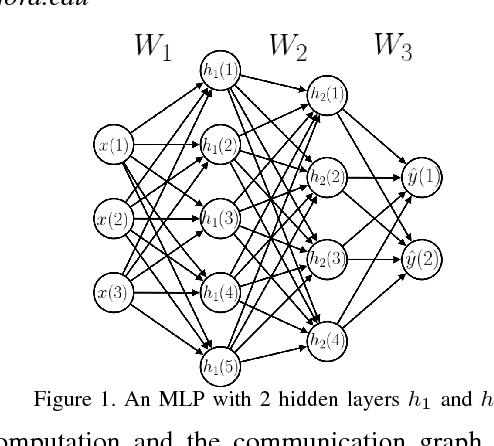
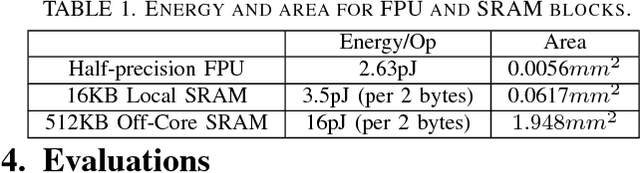
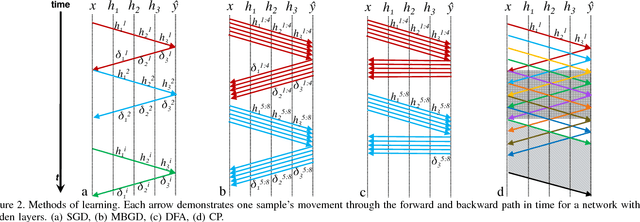
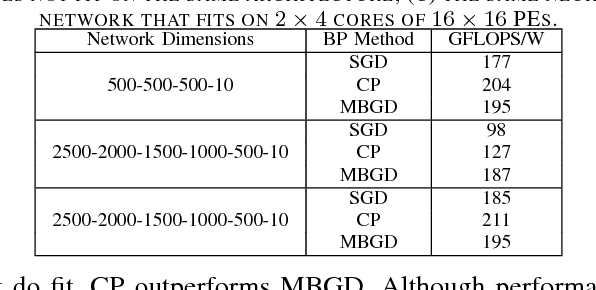
Accelerating the inference of a trained DNN is a well studied subject. In this paper we switch the focus to the training of DNNs. The training phase is compute intensive, demands complicated data communication, and contains multiple levels of data dependencies and parallelism. This paper presents an algorithm/architecture space exploration of efficient accelerators to achieve better network convergence rates and higher energy efficiency for training DNNs. We further demonstrate that an architecture with hierarchical support for collective communication semantics provides flexibility in training various networks performing both stochastic and batched gradient descent based techniques. Our results suggest that smaller networks favor non-batched techniques while performance for larger networks is higher using batched operations. At 45nm technology, CATERPILLAR achieves performance efficiencies of 177 GFLOPS/W at over 80% utilization for SGD training on small networks and 211 GFLOPS/W at over 90% utilization for pipelined SGD/CP training on larger networks using a total area of 103.2 mm$^2$ and 178.9 mm$^2$ respectively.