 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATERPILLAR: Coarse Grain Reconfigurable Architecture for Accelerating the Training of Deep Neural Networks
Paper and Code
Jun 08, 2017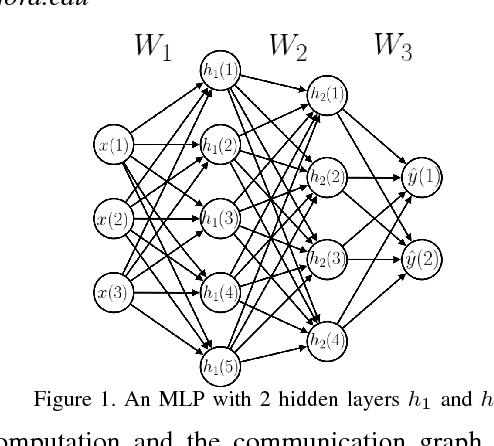
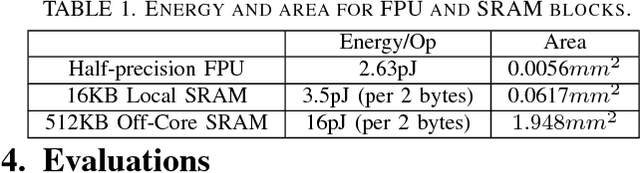
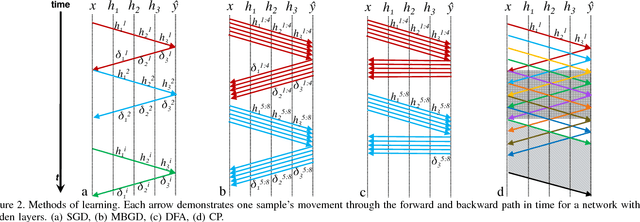
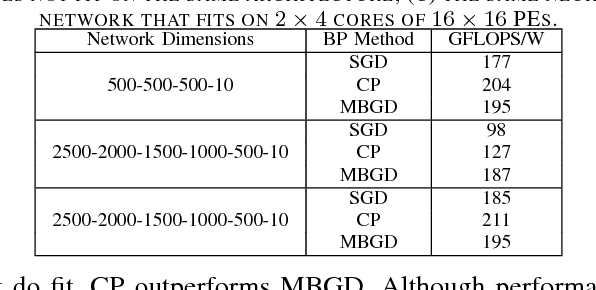
Accelerating the inference of a trained DNN is a well studied subject. In this paper we switch the focus to the training of DNNs. The training phase is compute intensive, demands complicated data communication, and contains multiple levels of data dependencies and parallelism. This paper presents an algorithm/architecture space exploration of efficient accelerators to achieve better network convergence rates and higher energy efficiency for training DNNs. We further demonstrate that an architecture with hierarchical support for collective communication semantics provides flexibility in training various networks performing both stochastic and batched gradient descent based techniques. Our results suggest that smaller networks favor non-batched techniques while performance for larger networks is higher using batched operations. At 45nm technology, CATERPILLAR achieves performance efficiencies of 177 GFLOPS/W at over 80% utilization for SGD training on small networks and 211 GFLOPS/W at over 90% utilization for pipelined SGD/CP training on larger networks using a total area of 103.2 mm$^2$ and 178.9 mm$^2$ respectively.