 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMSkills: Towards Multimodal Skills for General Visual Agents
May 14, 2026Reusable skills have become a core substrate for improving agent capabilities, yet most existing skill packages encode reusable behavior primarily as textual prompts, executable code, or learned routines. For visual agents, however, procedural knowledge is inherently multimodal: reuse depends not only on what operation to perform, but also on recognizing the relevant state, interpreting visual evidence of progress or failure, and deciding what to do next. We formalize this requirement as multimodal procedural knowledge and address three practical challenges: (I) what a multimodal skill package should contain; (II) where such packages can be derived from public interaction experience; and (III) how agents can consult multimodal evidence at inference time without excessive image context or over-anchoring to reference screenshots. We introduce MMSkills, a framework for representing, generating, and using reusable multimodal procedures for runtime visual decision making. Each MMSkill is a compact, state-conditioned package that couples a textual procedure with runtime state cards and multi-view keyframes. To construct these packages, we develop an agentic trajectory-to-skill Generator that transforms public non-evaluation trajectories into reusable multimodal skills through workflow grouping, procedure induction, visual grounding, and meta-skill-guided auditing. To use them, we introduce a branch-loaded multimodal skill agent: selected state cards and keyframes are inspected in a temporary branch, aligned with the live environment, and distilled into structured guidance for the main agent. Experiments across GUI and game-based visual-agent benchmarks show that MMSkills consistently improve both frontier and smaller multimodal agents, suggesting that external multimodal procedural knowledge complements model-internal priors.
Plan-MCTS: Plan Exploration for Action Exploitation in Web Navigation
Feb 15, 2026Large Language Models (LLMs) have empowered autonomous agents to handle complex web navigation tasks. While recent studies integrate tree search to enhance long-horizon reasoning, applying these algorithms in web navigation faces two critical challenges: sparse valid paths that lead to inefficient exploration, and a noisy context that dilutes accurate state perception. To address this, we introduce Plan-MCTS, a framework that reformulates web navigation by shifting exploration to a semantic Plan Space. By decoupling strategic planning from execution grounding, it transforms sparse action space into a Dense Plan Tree for efficient exploration, and distills noisy contexts into an Abstracted Semantic History for precise state awareness. To ensure efficiency and robustness, Plan-MCTS incorporates a Dual-Gating Reward to strictly validate both physical executability and strategic alignment and Structural Refinement for on-policy repair of failed subplans. Extensive experiments on WebArena demonstrate that Plan-MCTS achieves state-of-the-art performance, surpassing current approaches with higher task effectiveness and search efficiency.
NL-Debugging: Exploiting Natural Language as an Intermediate Representation for Code Debugging
May 21, 2025Debugging is a critical aspect of LLM's coding ability. Early debugging efforts primarily focused on code-level analysis, which often falls short when addressing complex programming errors that require a deeper understanding of algorithmic logic. Recent advancements in large language models (LLMs) have shifted attention toward leveraging natural language reasoning to enhance code-related tasks. However, two fundamental questions remain unanswered: What type of natural language format is most effective for debugging tasks? And what specific benefits does natural language reasoning bring to the debugging process? In this paper, we introduce NL-DEBUGGING, a novel framework that employs natural language as an intermediate representation to improve code debugging. By debugging at a natural language level, we demonstrate that NL-DEBUGGING outperforms traditional debugging methods and enables a broader modification space through direct refinement guided by execution feedback. Our findings highlight the potential of natural language reasoning to advance automated code debugging and address complex programming challenges.
RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation
Sep 15, 2024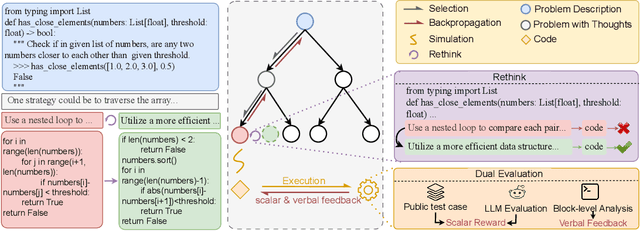

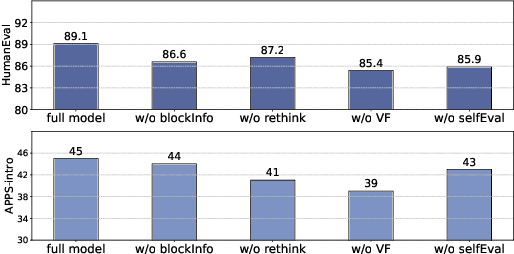

LLM agents enhanced by tree search algorithms have yielded notable performances in code generation. However, current search algorithms in this domain suffer from low search quality due to several reasons: 1) Ineffective design of the search space for the high-reasoning demands of code generation tasks, 2) Inadequate integration of code feedback with the search algorithm, and 3) Poor handling of negative feedback during the search, leading to reduced search efficiency and quality. To address these challenges, we propose to search for the reasoning process of the code and use the detailed feedback of code execution to refine erroneous thoughts during the search. In this paper, we introduce RethinkMCTS, which employs the Monte Carlo Tree Search (MCTS) algorithm to conduct thought-level searches before generating code, thereby exploring a wider range of strategies. More importantly, we construct verbal feedback from fine-grained code execution feedback to refine erroneous thoughts during the search. This ensures that the search progresses along the correct reasoning paths, thus improving the overall search quality of the tree by leveraging execution feedback. Through extensive experiments, we demonstrate that RethinkMCTS outperforms previous search-based and feedback-based code generation baselines. On the HumanEval dataset, it improves the pass@1 of GPT-3.5-turbo from 70.12 to 89.02 and GPT-4o-mini from 87.20 to 94.51. It effectively conducts more thorough exploration through thought-level searches and enhances the search quality of the entire tree by incorporating rethink operation.
Learning Structure and Knowledge Aware Representation with Large Language Models for Concept Recommendation
May 21, 2024



Concept recommendation aims to suggest the next concept for learners to study based on their knowledge states and the human knowledge system. While knowledge states can be predicted using knowledge tracing models, previous approaches have not effectively integrated the human knowledge system into the process of designing these educational models. In the era of rapidly evolving Large Language Models (LLMs), many fields have begun using LLMs to generate and encode text, introducing external knowledge. However, integrating LLMs into concept recommendation presents two urgent challenges: 1) How to construct text for concepts that effectively incorporate the human knowledge system? 2) How to adapt non-smooth, anisotropic text encodings effectively for concept recommendation? In this paper, we propose a novel Structure and Knowledge Aware Representation learning framework for concept Recommendation (SKarREC). We leverage factual knowledge from LLMs as well as the precedence and succession relationships between concepts obtained from the knowledge graph to construct textual representations of concepts. Furthermore, we propose a graph-based adapter to adapt anisotropic text embeddings to the concept recommendation task. This adapter is pre-trained through contrastive learning on the knowledge graph to get a smooth and structure-aware concept representation. Then, it's fine-tuned through the recommendation task, forming a text-to-knowledge-to-recommendation adaptation pipeline, which effectively constructs a structure and knowledge-aware concept representation. Our method does a better job than previous adapters in transforming text encodings for application in concept recommendation. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed approach.
Symbol Rate and Carries Estimation in OFDM Framework: A high Accuracy Technique under Low SNR
Jul 27, 2022
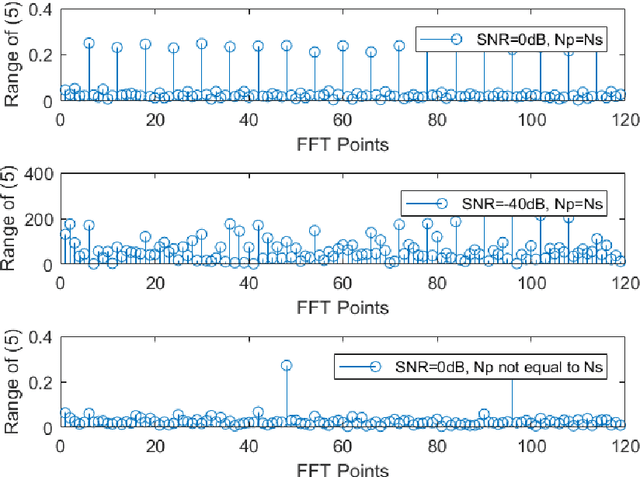

Under a low Signal-to-Noise Ratio (SNR), the Orthogonal Frequency-Division Multiplexing (OFDM) signal symbol rate is limited. Existing carrier number estimation algorithms lack adequate methods to deal with low SNR. This paper proposes an algorithm with a low error rate under low SNR by correlating the signal and applying a Fast Fourier Transform (FFT) operation. By improving existing algorithms, we improve the performance of the OFDM carrier count algorithm. The performance of the OFDM's useful symbol time estimation algorithm is improved by estimating the number of carriers and symbol rate.
I-WKNN: Fast-Speed and High-Accuracy WIFI Positioning for Intelligent Stadiums
Dec 03, 2021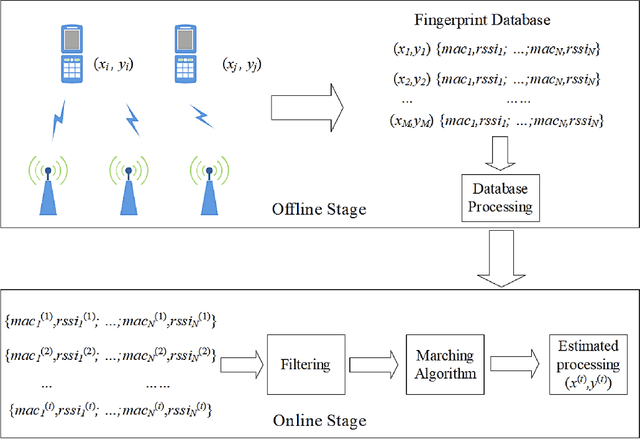
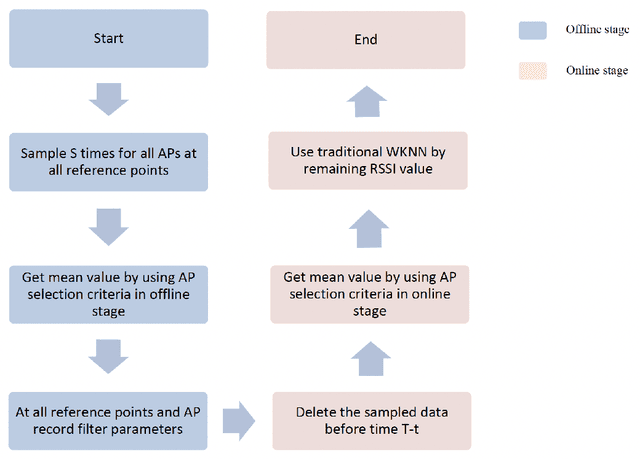

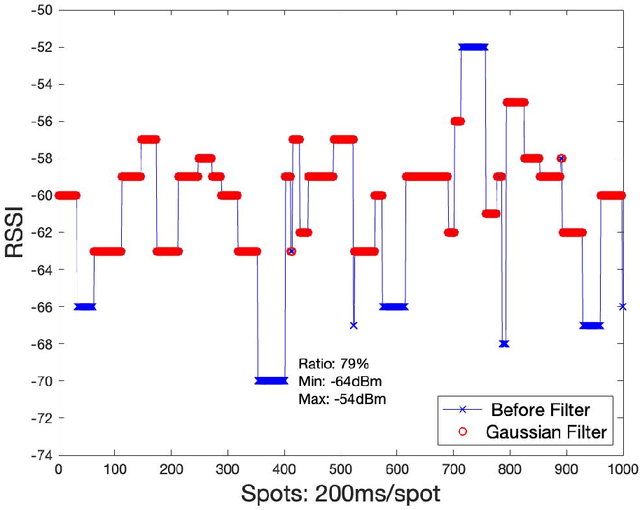
Based on various existing wireless fingerprint location algorithms in intelligent sports venues, a high-precision and fast indoor location algorithm improved weighted k-nearest neighbor (I-WKNN) is proposed. In order to meet the complex environment of sports venues and the demand of high-speed sampling, this paper proposes an AP selection algorithm for offline and online stages. Based on the characteristics of the signal intensity distribution in intelligent venues, an asymmetric Gaussian filter algorithm is proposed. This paper introduces the application of the positioning algorithm in the intelligent stadium system, and completes the data acquisition and real-time positioning of the stadium. Compared with traditional WKNN and KNN algorithms, the I-WKNN algorithm has advantages in fingerprint positioning database processing, environmental noise adaptability, real-time positioning accuracy and positioning speed, etc. The experimental results show that the I-WKNN algorithm has obvious advantages in positioning accuracy and positioning time in a complex noise environment and has obvious application potential in a smart stadium.
Knowledge Graph Augmented Political Perspective Detection in News Media
Sep 07, 2021
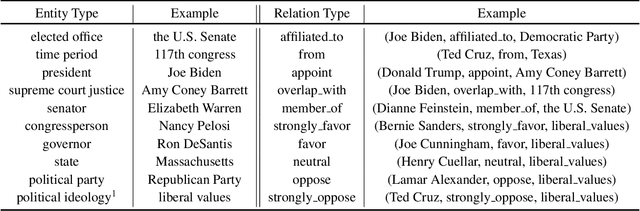
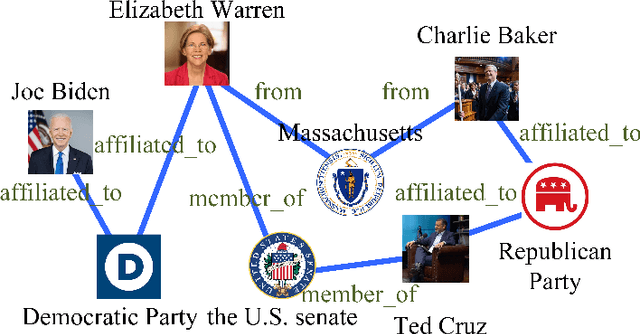
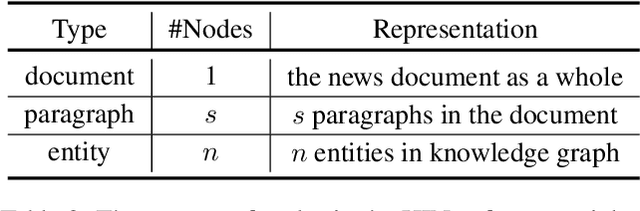
Identifying political perspective in news media has become an important task due to the rapid growth of political commentary and the increasingly polarized ideologies. Previous approaches only focus on leveraging the semantic information and leaves out the rich social and political context that helps individuals understand political stances. In this paper, we propose a perspective detection method that incorporates external knowledge of real-world politics. Specifically, we construct a contemporary political knowledge graph with 1,071 entities and 10,703 triples. We then build a heterogeneous information network for each news document that jointly models article semantics and external knowledge in knowledge graphs. Finally, we apply gated relational graph convolutional networks and conduct political perspective detection as graph-level classification. Extensive experiments show that our method achieves the best performance and outperforms state-of-the-art methods by 5.49%. Numerous ablation studies further bear out the necessity of external knowledge and the effectiveness of our graph-based approach.