 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanisms of Generative Image-to-Image Translation Networks
Nov 15, 2024Generative Adversarial Networks (GANs) are a class of neural networks that have been widely used in the field of image-to-image translation. In this paper, we propose a streamlined image-to-image translation network with a simpler architecture compared to existing models. We investigate the relationship between GANs and autoencoders and provide an explanation for the efficacy of employing only the GAN component for tasks involving image translation. We show that adversarial for GAN models yields results comparable to those of existing methods without additional complex loss penalties. Subsequently, we elucidate the rationale behind this phenomenon. We also incorporate experimental results to demonstrate the validity of our findings.
Shape-Preserving Generation of Food Images for Automatic Dietary Assessment
Aug 23, 2024



Traditional dietary assessment methods heavily rely on self-reporting, which is time-consuming and prone to bias. Recent advancements in Artificial Intelligence (AI) have revealed new possibilities for dietary assessment, particularly through analysis of food images. Recognizing foods and estimating food volumes from images are known as the key procedures for automatic dietary assessment. However, both procedures required large amounts of training images labeled with food names and volumes, which are currently unavailable. Alternatively, recent studies have indicated that training images can be artificially generated using Generative Adversarial Networks (GANs). Nonetheless, convenient generation of large amounts of food images with known volumes remain a challenge with the existing techniques. In this work, we present a simple GAN-based neural network architecture for conditional food image generation. The shapes of the food and container in the generated images closely resemble those in the reference input image. Our experiments demonstrate the realism of the generated images and shape-preserving capabilities of the proposed framework.
Clustering Egocentric Images in Passive Dietary Monitoring with Self-Supervised Learning
Aug 25, 2022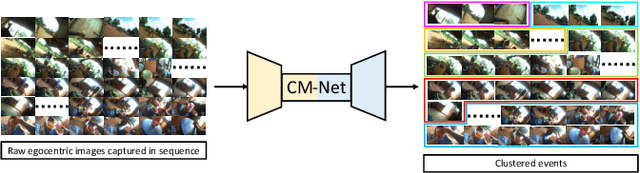
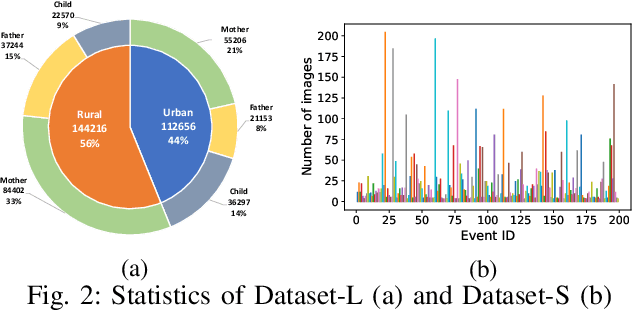
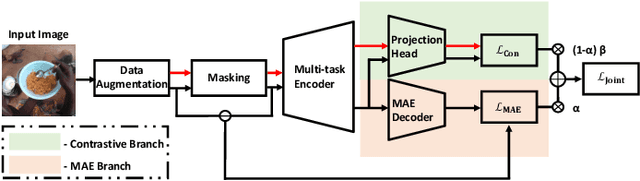
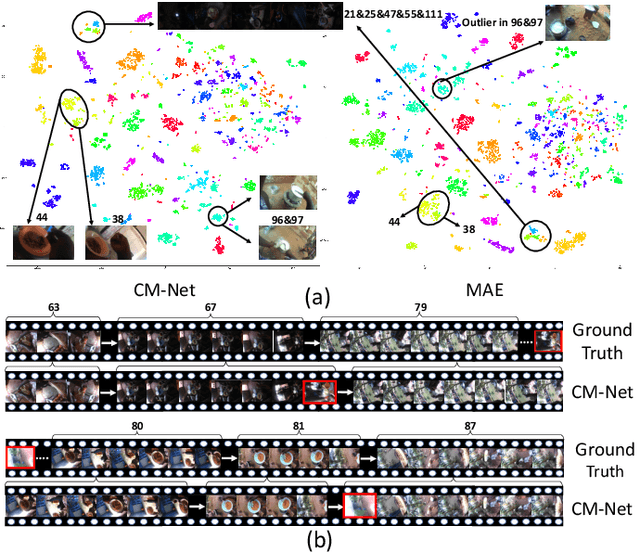
In our recent dietary assessment field studies on passive dietary monitoring in Ghana, we have collected over 250k in-the-wild images. The dataset is an ongoing effort to facilitate accurate measurement of individual food and nutrient intake in low and middle income countries with passive monitoring camera technologies. The current dataset involves 20 households (74 subjects) from both the rural and urban regions of Ghana, and two different types of wearable cameras were used in the studies. Once initiated, wearable cameras continuously capture subjects' activities, which yield massive amounts of data to be cleaned and annotated before analysis is conducted. To ease the data post-processing and annotation tasks, we propose a novel self-supervised learning framework to cluster the large volume of egocentric images into separate events. Each event consists of a sequence of temporally continuous and contextually similar images. By clustering images into separate events, annotators and dietitians can examine and analyze the data more efficiently and facilitate the subsequent dietary assessment processes. Validated on a held-out test set with ground truth labels, the proposed framework outperforms baselines in terms of clustering quality and classification accuracy.
Egocentric Image Captioning for Privacy-Preserved Passive Dietary Intake Monitoring
Jul 01, 2021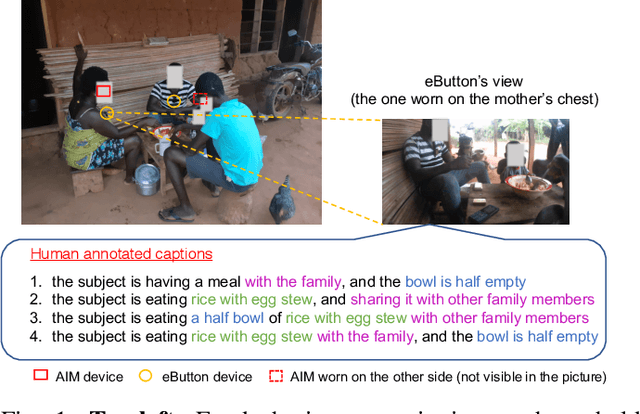
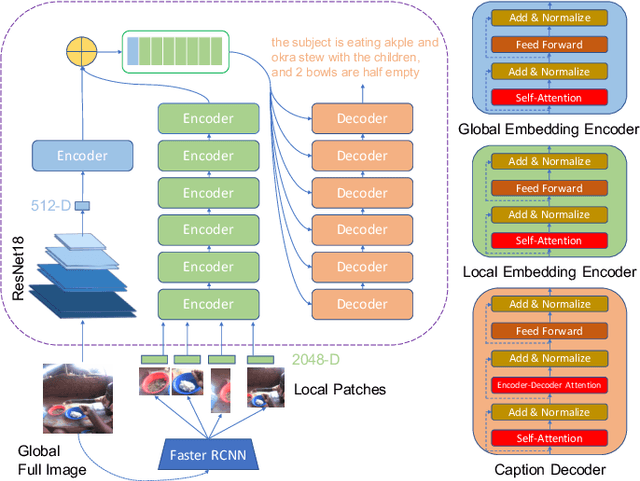
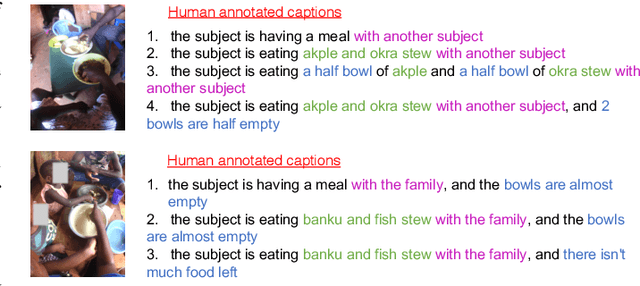
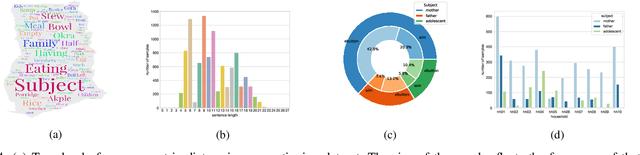
Camera-based passive dietary intake monitoring is able to continuously capture the eating episodes of a subject, recording rich visual information, such as the type and volume of food being consumed, as well as the eating behaviours of the subject. However, there currently is no method that is able to incorporate these visual clues and provide a comprehensive context of dietary intake from passive recording (e.g., is the subject sharing food with others, what food the subject is eating, and how much food is left in the bowl). On the other hand, privacy is a major concern while egocentric wearable cameras are used for capturing. In this paper, we propose a privacy-preserved secure solution (i.e., egocentric image captioning) for dietary assessment with passive monitoring, which unifies food recognition, volume estimation, and scene understanding. By converting images into rich text descriptions, nutritionists can assess individual dietary intake based on the captions instead of the original images, reducing the risk of privacy leakage from images. To this end, an egocentric dietary image captioning dataset has been built, which consists of in-the-wild images captured by head-worn and chest-worn cameras in field studies in Ghana. A novel transformer-based architecture is designed to caption egocentric dietary images. Comprehensive experiments have been conducted to evaluate the effectiveness and to justify the design of the proposed architecture for egocentric dietary image captioning. To the best of our knowledge, this is the first work that applies image captioning to dietary intake assessment in real life settings.
Real time backbone for semantic segmentation
Mar 16, 2019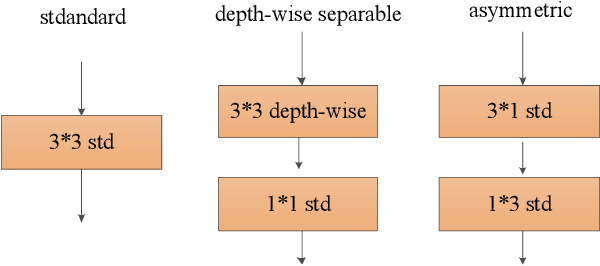
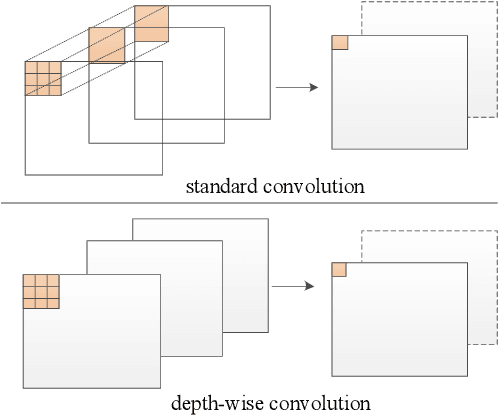

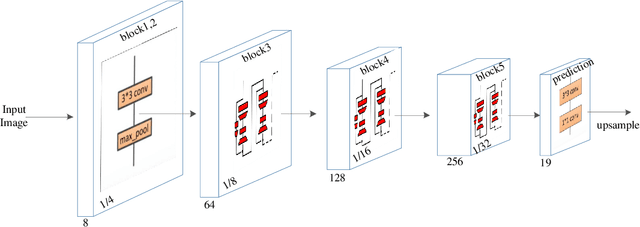
The rapid development of autonomous driving in recent years presents lots of challenges for scene understanding. As an essential step towards scene understanding, semantic segmentation thus received lots of attention in past few years. Although deep learning based state-of-the-arts have achieved great success in improving the segmentation accuracy, most of them suffer from an inefficiency problem and can hardly applied to practical applications. In this paper, we systematically analyze the computation cost of Convolutional Neural Network(CNN) and found that the inefficiency of CNN is mainly caused by its wide structure rather than the deep structure. In addition, the success of pruning based model compression methods proved that there are many redundant channels in CNN. Thus, we designed a very narrow while deep backbone network to improve the efficiency of semantic segmentation. By casting our network to FCN32 segmentation architecture, the basic structure of most segmentation methods, we achieved 60.6\% mIoU on Cityscape val dataset with 54 frame per seconds(FPS) on $1024\times2048$ inputs, which already outperforms one of the earliest real time deep learning based segmentation methods: ENet.