 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal time backbone for semantic segmentation
Paper and Code
Mar 16, 2019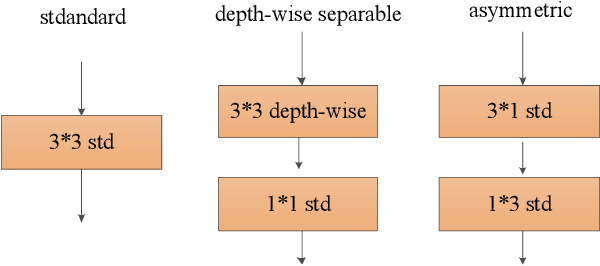
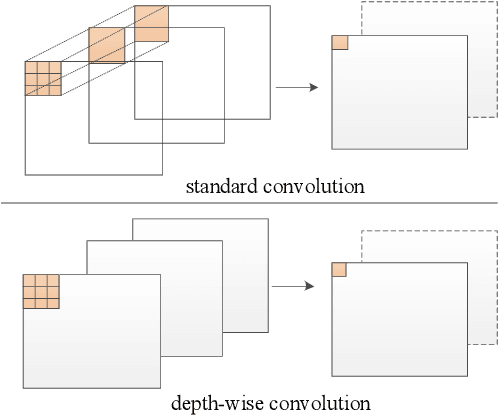

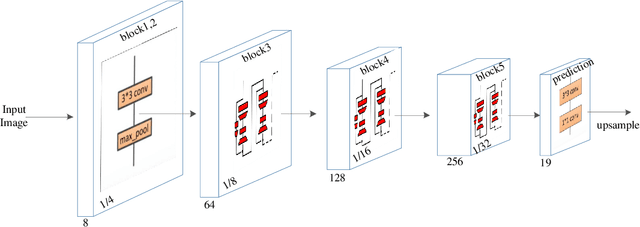
The rapid development of autonomous driving in recent years presents lots of challenges for scene understanding. As an essential step towards scene understanding, semantic segmentation thus received lots of attention in past few years. Although deep learning based state-of-the-arts have achieved great success in improving the segmentation accuracy, most of them suffer from an inefficiency problem and can hardly applied to practical applications. In this paper, we systematically analyze the computation cost of Convolutional Neural Network(CNN) and found that the inefficiency of CNN is mainly caused by its wide structure rather than the deep structure. In addition, the success of pruning based model compression methods proved that there are many redundant channels in CNN. Thus, we designed a very narrow while deep backbone network to improve the efficiency of semantic segmentation. By casting our network to FCN32 segmentation architecture, the basic structure of most segmentation methods, we achieved 60.6\% mIoU on Cityscape val dataset with 54 frame per seconds(FPS) on $1024\times2048$ inputs, which already outperforms one of the earliest real time deep learning based segmentation methods: ENet.