 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmoEarth: Stable Latent Image Modeling for Multimodal Earth Observation
Nov 17, 2025Earth observation data presents a unique challenge: it is spatial like images, sequential like video or text, and highly multimodal. We present OlmoEarth: a multimodal, spatio-temporal foundation model that employs a novel self-supervised learning formulation, masking strategy, and loss all designed for the Earth observation domain. OlmoEarth achieves state-of-the-art performance compared to 12 other foundation models across a variety of research benchmarks and real-world tasks from external partners. When evaluating embeddings OlmoEarth achieves the best performance on 15 out of 24 tasks, and with full fine-tuning it is the best on 19 of 29 tasks. We deploy OlmoEarth as the backbone of an end-to-end platform for data collection, labeling, training, and inference of Earth observation models. The OlmoEarth Platform puts frontier foundation models and powerful data management tools into the hands of non-profits and NGOs working to solve the world's biggest problems. OlmoEarth source code, training data, and pre-trained weights are available at $\href{https://github.com/allenai/olmoearth_pretrain}{\text{https://github.com/allenai/olmoearth_pretrain}}$.
Inferring Short-Sightedness in Dynamic Noncooperative Games
Dec 02, 2024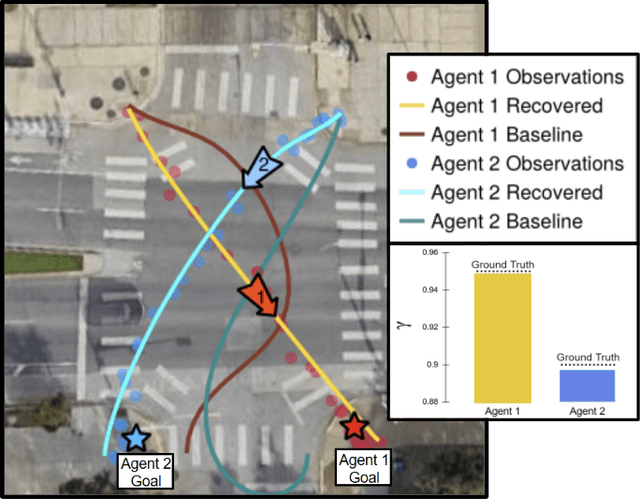
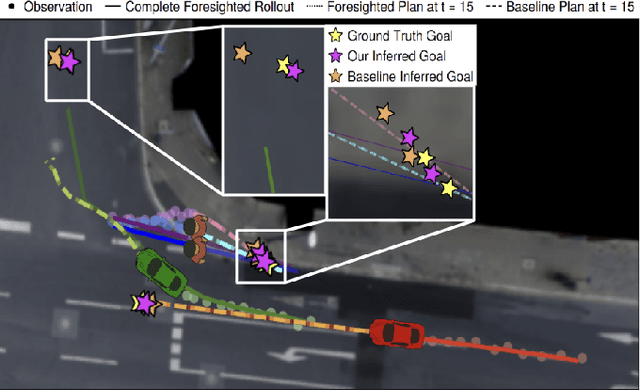
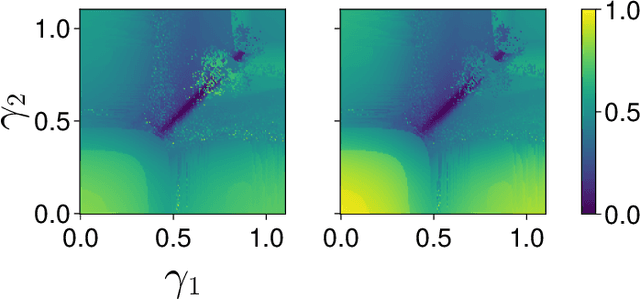
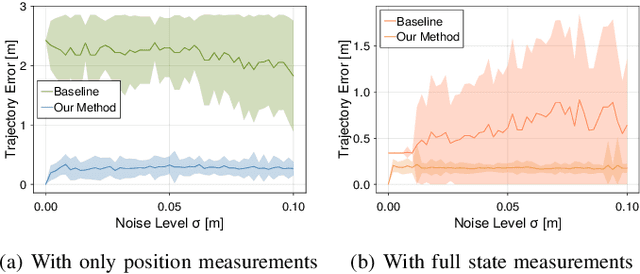
Dynamic game theory is an increasingly popular tool for modeling multi-agent, e.g. human-robot, interactions. Game-theoretic models presume that each agent wishes to minimize a private cost function that depends on others' actions. These games typically evolve over a fixed time horizon, which specifies the degree to which all agents care about the distant future. In practical settings, however, decision-makers may vary in their degree of short-sightedness. We conjecture that quantifying and estimating each agent's short-sightedness from online data will enable safer and more efficient interactions with other agents. To this end, we frame this inference problem as an inverse dynamic game. We consider a specific parametrization of each agent's objective function that smoothly interpolates myopic and farsighted planning. Games of this form are readily transformed into parametric mixed complementarity problems; we exploit the directional differentiability of solutions to these problems with respect to their hidden parameters in order to solve for agents' short-sightedness. We conduct several experiments simulating human behavior at a real-world crosswalk. The results of these experiments clearly demonstrate that by explicitly inferring agents' short-sightedness, we can recover more accurate game-theoretic models, which ultimately allow us to make better predictions of agents' behavior. Specifically, our results show up to a 30% more accurate prediction of myopic behavior compared to the baseline.
Improving Inverse Folding for Peptide Design with Diversity-regularized Direct Preference Optimization
Oct 25, 2024Inverse folding models play an important role in structure-based design by predicting amino acid sequences that fold into desired reference structures. Models like ProteinMPNN, a message-passing encoder-decoder model, are trained to reliably produce new sequences from a reference structure. However, when applied to peptides, these models are prone to generating repetitive sequences that do not fold into the reference structure. To address this, we fine-tune ProteinMPNN to produce diverse and structurally consistent peptide sequences via Direct Preference Optimization (DPO). We derive two enhancements to DPO: online diversity regularization and domain-specific priors. Additionally, we develop a new understanding on improving diversity in decoder models. When conditioned on OpenFold generated structures, our fine-tuned models achieve state-of-the-art structural similarity scores, improving base ProteinMPNN by at least 8%. Compared to standard DPO, our regularized method achieves up to 20% higher sequence diversity with no loss in structural similarity score.
From $r$ to $Q^*$: Your Language Model is Secretly a Q-Function
Apr 18, 2024Reinforcement Learning From Human Feedback (RLHF) has been a critical to the success of the latest generation of generative AI models. In response to the complex nature of the classical RLHF pipeline, direct alignment algorithms such as Direct Preference Optimization (DPO) have emerged as an alternative approach. Although DPO solves the same objective as the standard RLHF setup, there is a mismatch between the two approaches. Standard RLHF deploys reinforcement learning in a specific token-level MDP, while DPO is derived as a bandit problem in which the whole response of the model is treated as a single arm. In this work we rectify this difference, first we theoretically show that we can derive DPO in the token-level MDP as a general inverse Q-learning algorithm, which satisfies the Bellman equation. Using our theoretical results, we provide three concrete empirical insights. First, we show that because of its token level interpretation, DPO is able to perform some type of credit assignment. Next, we prove that under the token level formulation, classical search-based algorithms, such as MCTS, which have recently been applied to the language generation space, are equivalent to likelihood-based search on a DPO policy. Empirically we show that a simple beam search yields meaningful improvement over the base DPO policy. Finally, we show how the choice of reference policy causes implicit rewards to decline during training. We conclude by discussing applications of our work, including information elicitation in multi-tun dialogue, reasoning, agentic applications and end-to-end training of multi-model systems.
Disentangling Length from Quality in Direct Preference Optimization
Mar 28, 2024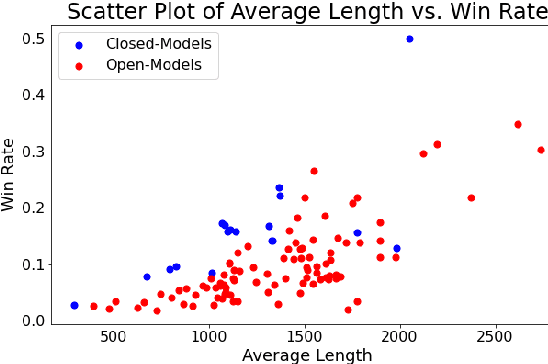
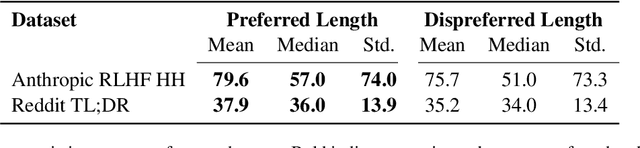
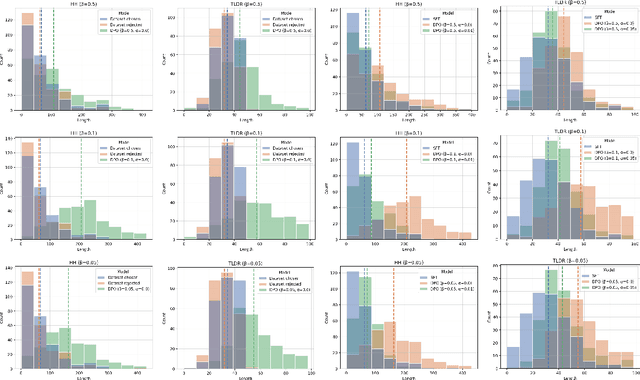
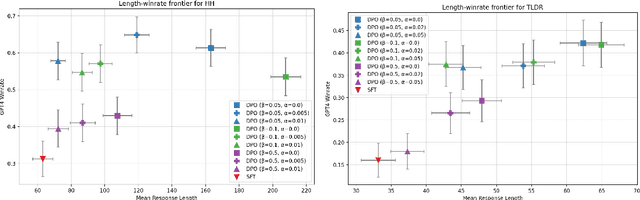
Reinforcement Learning from Human Feedback (RLHF) has been a crucial component in the recent success of Large Language Models. However, RLHF is know to exploit biases in human preferences, such as verbosity. A well-formatted and eloquent answer is often more highly rated by users, even when it is less helpful and objective. A number of approaches have been developed to control those biases in the classical RLHF literature, but the problem remains relatively under-explored for Direct Alignment Algorithms such as Direct Preference Optimization (DPO). Unlike classical RLHF, DPO does not train a separate reward model or use reinforcement learning directly, so previous approaches developed to control verbosity cannot be directly applied to this setting. Our work makes several contributions. For the first time, we study the length problem in the DPO setting, showing significant exploitation in DPO and linking it to out-of-distribution bootstrapping. We then develop a principled but simple regularization strategy that prevents length exploitation, while still maintaining improvements in model quality. We demonstrate these effects across datasets on summarization and dialogue, where we achieve up to 20\% improvement in win rates when controlling for length, despite the GPT4 judge's well-known verbosity bias.
Preference Optimization for Molecular Language Models
Oct 18, 2023Molecular language modeling is an effective approach to generating novel chemical structures. However, these models do not \emph{a priori} encode certain preferences a chemist may desire. We investigate the use of fine-tuning using Direct Preference Optimization to better align generated molecules with chemist preferences. Our findings suggest that this approach is simple, efficient, and highly effective.
EchoVest: Real-Time Sound Classification and Depth Perception Expressed through Transcutaneous Electrical Nerve Stimulation
Jul 10, 2023Over 1.5 billion people worldwide live with hearing impairment. Despite various technologies that have been created for individuals with such disabilities, most of these technologies are either extremely expensive or inaccessible for everyday use in low-medium income countries. In order to combat this issue, we have developed a new assistive device, EchoVest, for blind/deaf people to intuitively become more aware of their environment. EchoVest transmits vibrations to the user's body by utilizing transcutaneous electric nerve stimulation (TENS) based on the source of the sounds. EchoVest also provides various features, including sound localization, sound classification, noise reduction, and depth perception. We aimed to outperform CNN-based machine-learning models, the most commonly used machine learning model for classification tasks, in accuracy and computational costs. To do so, we developed and employed a novel audio pipeline that adapts the Audio Spectrogram Transformer (AST) model, an attention-based model, for our sound classification purposes, and Fast Fourier Transforms for noise reduction. The application of Otsu's Method helped us find the optimal thresholds for background noise sound filtering and gave us much greater accuracy. In order to calculate direction and depth accurately, we applied Complex Time Difference of Arrival algorithms and SOTA localization. Our last improvement was to use blind source separation to make our algorithms applicable to multiple microphone inputs. The final algorithm achieved state-of-the-art results on numerous checkpoints, including a 95.7\% accuracy on the ESC-50 dataset for environmental sound classification.