 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-hop Upstream Preemptive Traffic Signal Control with Deep Reinforcement Learning
Nov 10, 2024

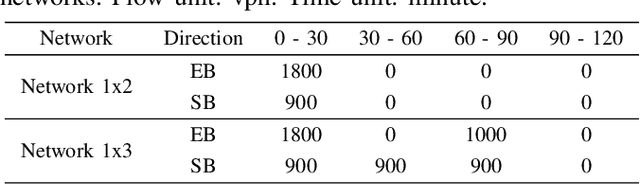
Traffic signal control is crucial for managing congestion in urban networks. Existing myopic pressure-based control methods focus only on immediate upstream links, leading to suboptimal green time allocation and increased network delays. Effective signal control, however, inherently requires a broader spatial scope, as traffic conditions further upstream can significantly impact traffic at the current location. This paper introduces a novel concept based on the Markov chain theory, namely multi-hop upstream pressure, that generalizes the conventional pressure to account for traffic conditions beyond the immediate upstream links. This farsighted and compact metric informs the deep reinforcement learning agent to preemptively clear the present queues, guiding the agent to optimize signal timings with a broader spatial awareness. Simulations on synthetic and realistic (Toronto) scenarios demonstrate controllers utilizing multi-hop upstream pressure significantly reduce overall network delay by prioritizing traffic movements based on a broader understanding of upstream congestion.
Generalized Multi-hop Traffic Pressure for Heterogeneous Traffic Perimeter Control
Sep 01, 2024



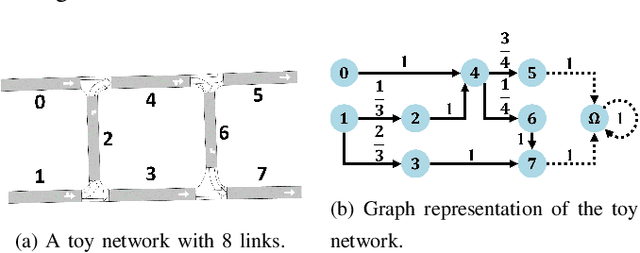
Perimeter control prevents loss of traffic network capacity due to congestion in urban areas. Homogeneous perimeter control allows all access points to a protected region to have the same maximal permitted inflow. However, homogeneous perimeter control performs poorly when the congestion in the protected region is heterogeneous (e.g., imbalanced demand) since the homogeneous perimeter control does not consider location-specific traffic conditions around the perimeter. When the protected region has spatially heterogeneous congestion, it can often make sense to modulate the perimeter inflow rate to be higher near low-density regions and vice versa for high-density regions. To assist with this modulation, we can leverage the concept of 1-hop traffic pressure to measure intersection-level traffic congestion. However, as we show, 1-hop pressure turns out to be too spatially myopic for perimeter control and hence we formulate multi-hop generalizations of pressure that look ``deeper'' inside the perimeter beyond the entry intersection. In addition, we formulate a simple heterogeneous perimeter control methodology that can leverage this novel multi-hop pressure to redistribute the total permitted inflow provided by the homogeneous perimeter controller. Experimental results show that our heterogeneous perimeter control policies leveraging multi-hop pressure significantly outperform homogeneous perimeter control in scenarios where the origin-destination flows are highly imbalanced with high spatial heterogeneity.
SECRM-2D: RL-Based Efficient and Comfortable Route-Following Autonomous Driving with Analytic Safety Guarantees
Jul 23, 2024



Over the last decade, there has been increasing interest in autonomous driving systems. Reinforcement Learning (RL) shows great promise for training autonomous driving controllers, being able to directly optimize a combination of criteria such as efficiency comfort, and stability. However, RL- based controllers typically offer no safety guarantees, making their readiness for real deployment questionable. In this paper, we propose SECRM-2D (the Safe, Efficient and Comfortable RL- based driving Model with Lane-Changing), an RL autonomous driving controller (both longitudinal and lateral) that balances optimization of efficiency and comfort and follows a fixed route, while being subject to hard analytic safety constraints. The aforementioned safety constraints are derived from the criterion that the follower vehicle must have sufficient headway to be able to avoid a crash if the leader vehicle brakes suddenly. We evaluate SECRM-2D against several learning and non-learning baselines in simulated test scenarios, including freeway driving, exiting, merging, and emergency braking. Our results confirm that representative previously-published RL AV controllers may crash in both training and testing, even if they are optimizing a safety objective. By contrast, our controller SECRM-2D is successful in avoiding crashes during both training and testing, improves over the baselines in measures of efficiency and comfort, and is more faithful in following the prescribed route. In addition, we achieve a good theoretical understanding of the longitudinal steady-state of a collection of SECRM-2D vehicles.