 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Policy Reuse using Deep Mixture Models
Paper and Code
Feb 29, 2020
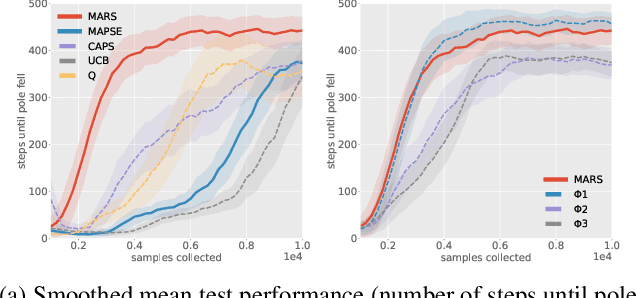
Reinforcement learning methods that consider the context, or current state, when selecting source policies for transfer have been shown to outperform context-free approaches. However, existing work typically tailors the approach to a specific learning algorithm such as Q-learning, and it is often difficult to interpret and validate the knowledge transferred between tasks. In this paper, we assume knowledge of estimated source task dynamics and policies, and common goals between tasks. We introduce a novel deep mixture model formulation for learning a state-dependent prior over source task dynamics that matches the target dynamics using only state trajectories obtained while learning the target policy. The mixture model is easy to train and interpret, is compatible with most reinforcement learning algorithms, and complements existing work by leveraging knowledge of source dynamics rather than Q-values. We then show how the trained mixture model can be incorporated into standard policy reuse frameworks, and demonstrate its effectiveness on benchmarks from OpenAI-Gym.