 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Data Can Lead Us Astray: Active Data Acquisition in the Presence of Label Bias
Paper and Code
Jul 15, 2022

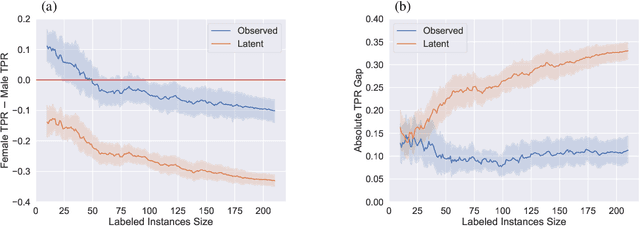
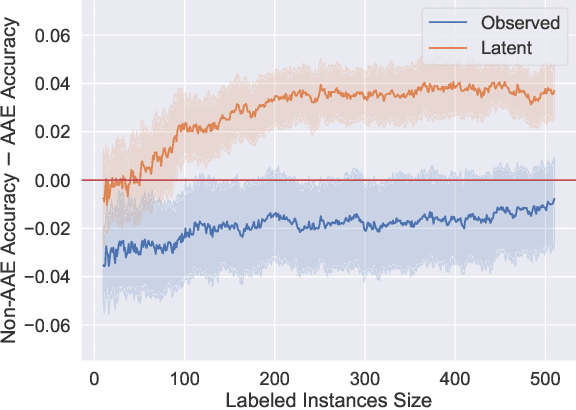
An increased awareness concerning risks of algorithmic bias has driven a surge of efforts around bias mitigation strategies. A vast majority of the proposed approaches fall under one of two categories: (1) imposing algorithmic fairness constraints on predictive models, and (2) collecting additional training samples. Most recently and at the intersection of these two categories, methods that propose active learning under fairness constraints have been developed. However, proposed bias mitigation strategies typically overlook the bias presented in the observed labels. In this work, we study fairness considerations of active data collection strategies in the presence of label bias. We first present an overview of different types of label bias in the context of supervised learning systems. We then empirically show that, when overlooking label bias, collecting more data can aggravate bias, and imposing fairness constraints that rely on the observed labels in the data collection process may not address the problem. Our results illustrate the unintended consequences of deploying a model that attempts to mitigate a single type of bias while neglecting others, emphasizing the importance of explicitly differentiating between the types of bias that fairness-aware algorithms aim to address, and highlighting the risks of neglecting label bias during data collection.