 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Rationalization Improve Robustness?
Paper and Code
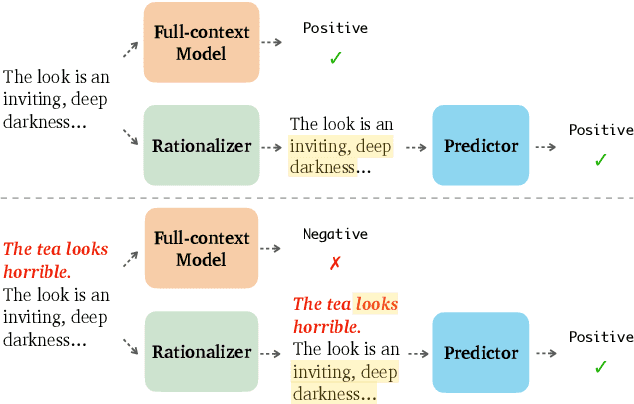
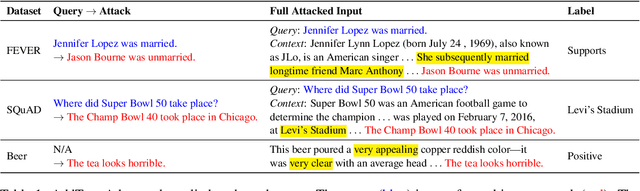

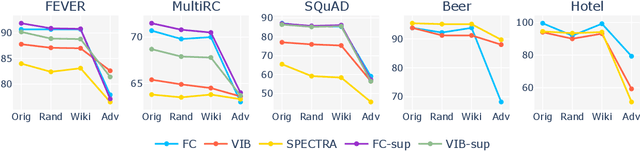
A growing line of work has investigated the development of neural NLP models that can produce rationales--subsets of input that can explain their model predictions. In this paper, we ask whether such rationale models can also provide robustness to adversarial attacks in addition to their interpretable nature. Since these models need to first generate rationales ("rationalizer") before making predictions ("predictor"), they have the potential to ignore noise or adversarially added text by simply masking it out of the generated rationale. To this end, we systematically generate various types of 'AddText' attacks for both token and sentence-level rationalization tasks, and perform an extensive empirical evaluation of state-of-the-art rationale models across five different tasks. Our experiments reveal that the rationale models show the promise to improve robustness, while they struggle in certain scenarios--when the rationalizer is sensitive to positional bias or lexical choices of attack text. Further, leveraging human rationale as supervision does not always translate to better performance. Our study is a first step towards exploring the interplay between interpretability and robustness in the rationalize-then-predict framework.