 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unifying Framework for Robust and Efficient Inference with Unstructured Data
May 01, 2025This paper presents a general framework for conducting efficient and robust inference on parameters derived from unstructured data, which include text, images, audio, and video. Economists have long incorporated data extracted from texts and images into their analyses, a practice that has accelerated with advancements in deep neural networks. However, neural networks do not generically produce unbiased predictions, potentially propagating bias to estimators that use their outputs. To address this challenge, we reframe inference with unstructured data as a missing structured data problem, where structured data are imputed from unstructured inputs using deep neural networks. This perspective allows us to apply classic results from semiparametric inference, yielding valid, efficient, and robust estimators based on unstructured data. We formalize this approach with MARS (Missing At Random Structured Data), a unifying framework that integrates and extends existing methods for debiased inference using machine learning predictions, linking them to a variety of older, familiar problems such as causal inference. We develop robust and efficient estimators for both descriptive and causal estimands and address challenges such as inference using aggregated and transformed predictions from unstructured data. Importantly, MARS applies to common empirical settings that have received limited attention in the existing literature. Finally, we reanalyze prominent studies that use unstructured data, demonstrating the practical value of MARS.
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024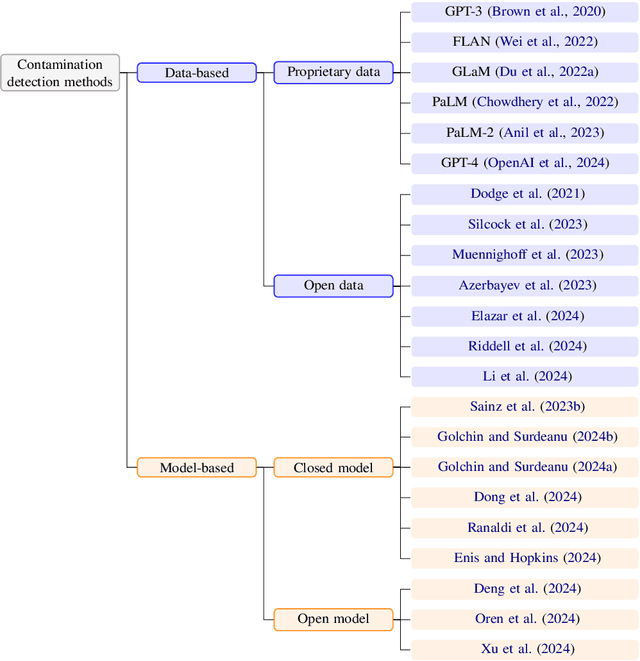
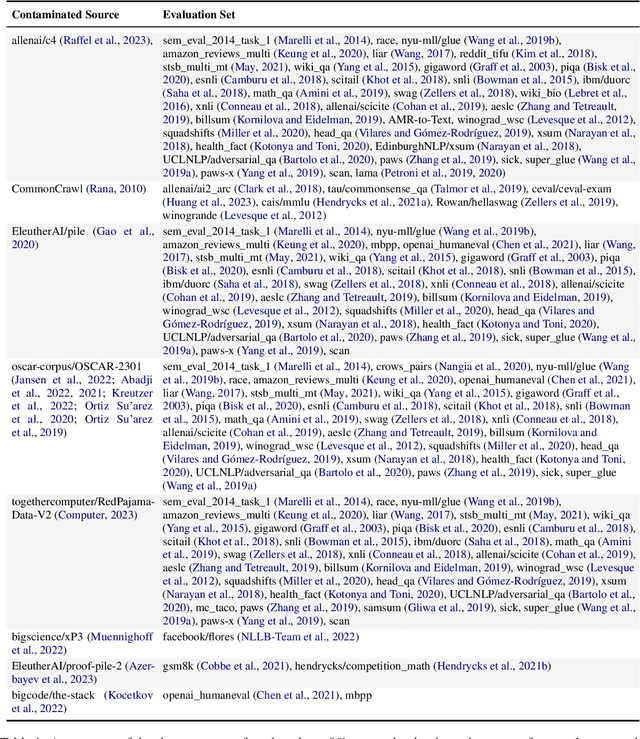
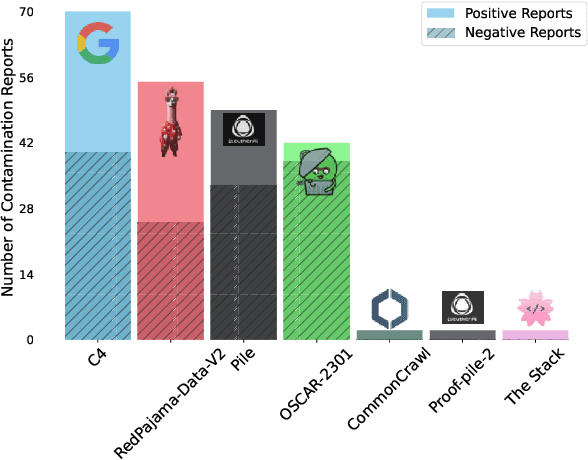
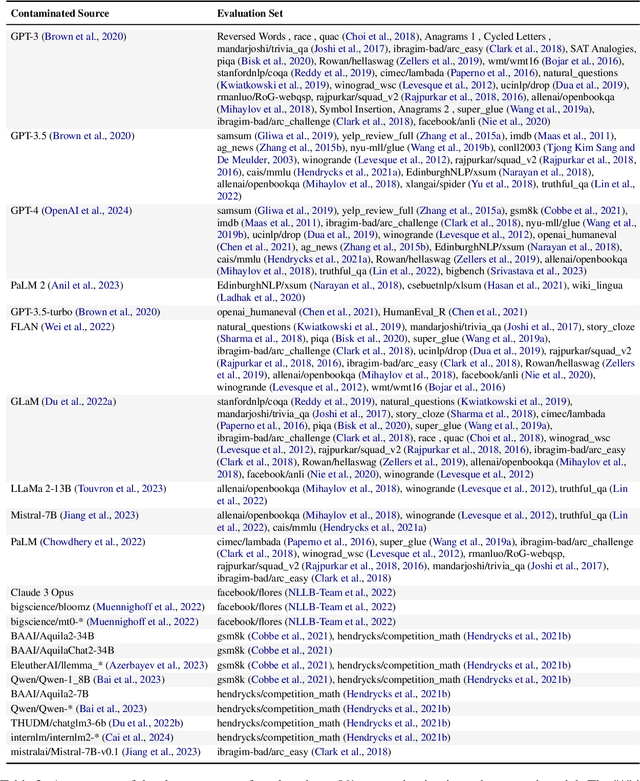
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
Deep Learning for Economists
Jul 22, 2024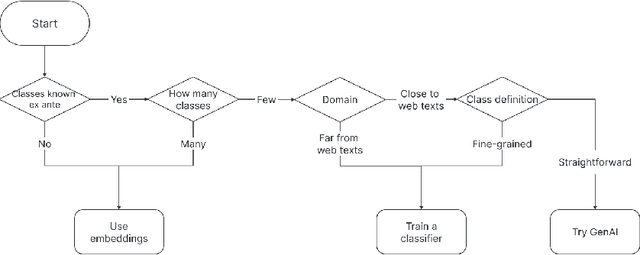
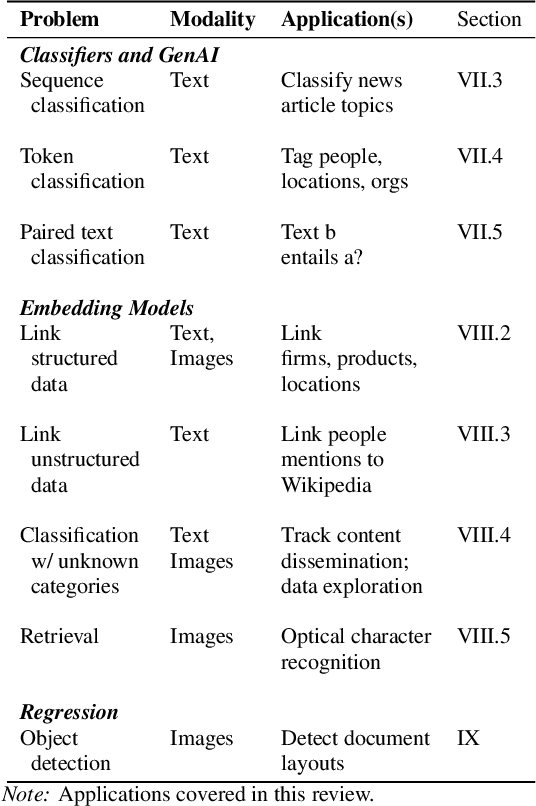
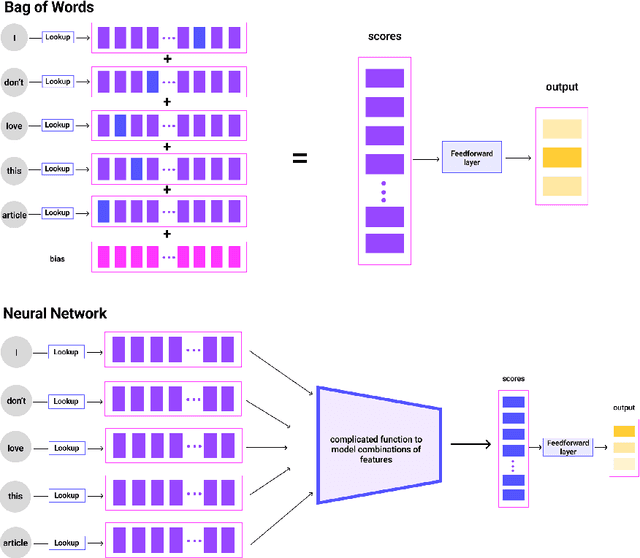
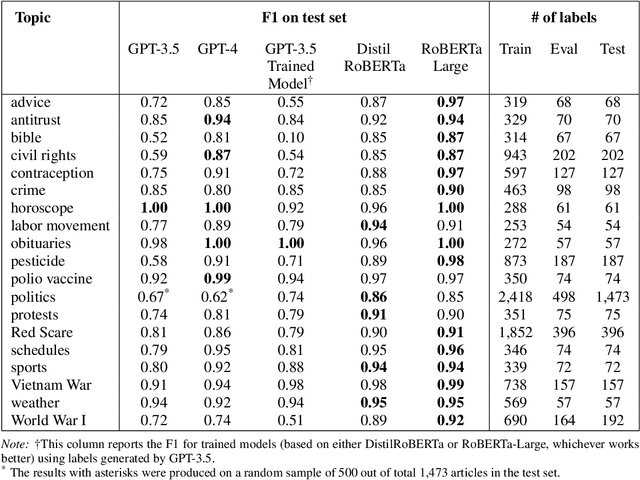
Deep learning provides powerful methods to impute structured information from large-scale, unstructured text and image datasets. For example, economists might wish to detect the presence of economic activity in satellite images, or to measure the topics or entities mentioned in social media, the congressional record, or firm filings. This review introduces deep neural networks, covering methods such as classifiers, regression models, generative AI, and embedding models. Applications include classification, document digitization, record linkage, and methods for data exploration in massive scale text and image corpora. When suitable methods are used, deep learning models can be cheap to tune and can scale affordably to problems involving millions or billions of data points.. The review is accompanied by a companion website, EconDL, with user-friendly demo notebooks, software resources, and a knowledge base that provides technical details and additional applications.
News Deja Vu: Connecting Past and Present with Semantic Search
Jun 21, 2024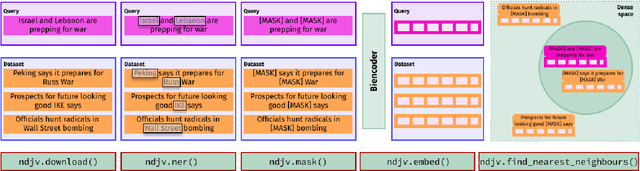


Social scientists and the general public often analyze contemporary events by drawing parallels with the past, a process complicated by the vast, noisy, and unstructured nature of historical texts. For example, hundreds of millions of page scans from historical newspapers have been noisily transcribed. Traditional sparse methods for searching for relevant material in these vast corpora, e.g., with keywords, can be brittle given complex vocabularies and OCR noise. This study introduces News Deja Vu, a novel semantic search tool that leverages transformer large language models and a bi-encoder approach to identify historical news articles that are most similar to modern news queries. News Deja Vu first recognizes and masks entities, in order to focus on broader parallels rather than the specific named entities being discussed. Then, a contrastively trained, lightweight bi-encoder retrieves historical articles that are most similar semantically to a modern query, illustrating how phenomena that might seem unique to the present have varied historical precedents. Aimed at social scientists, the user-friendly News Deja Vu package is designed to be accessible for those who lack extensive familiarity with deep learning. It works with large text datasets, and we show how it can be deployed to a massive scale corpus of historical, open-source news articles. While human expertise remains important for drawing deeper insights, News Deja Vu provides a powerful tool for exploring parallels in how people have perceived past and present.
Contrastive Entity Coreference and Disambiguation for Historical Texts
Jun 21, 2024
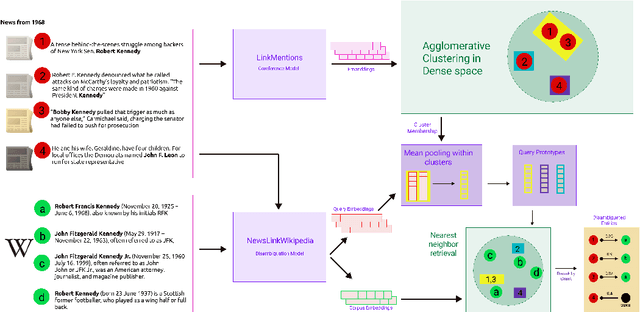
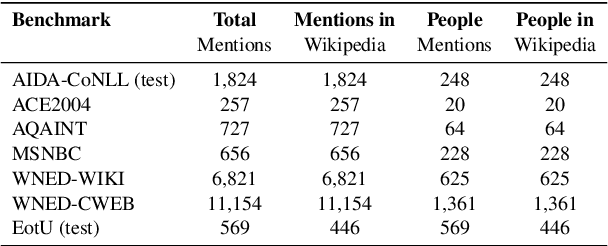

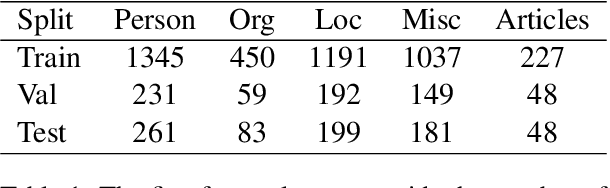
Massive-scale historical document collections are crucial for social science research. Despite increasing digitization, these documents typically lack unique cross-document identifiers for individuals mentioned within the texts, as well as individual identifiers from external knowledgebases like Wikipedia/Wikidata. Existing entity disambiguation methods often fall short in accuracy for historical documents, which are replete with individuals not remembered in contemporary knowledgebases. This study makes three key contributions to improve cross-document coreference resolution and disambiguation in historical texts: a massive-scale training dataset replete with hard negatives - that sources over 190 million entity pairs from Wikipedia contexts and disambiguation pages - high-quality evaluation data from hand-labeled historical newswire articles, and trained models evaluated on this historical benchmark. We contrastively train bi-encoder models for coreferencing and disambiguating individuals in historical texts, achieving accurate, scalable performance that identifies out-of-knowledgebase individuals. Our approach significantly surpasses other entity disambiguation models on our historical newswire benchmark. Our models also demonstrate competitive performance on modern entity disambiguation benchmarks, particularly certain news disambiguation datasets.
Newswire: A Large-Scale Structured Database of a Century of Historical News
Jun 13, 2024
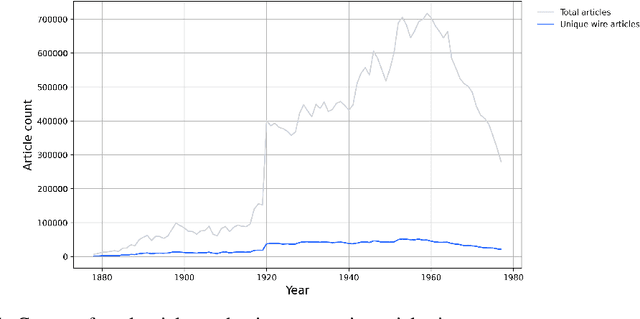
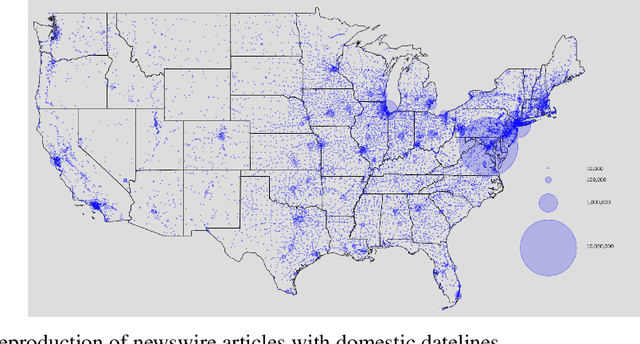
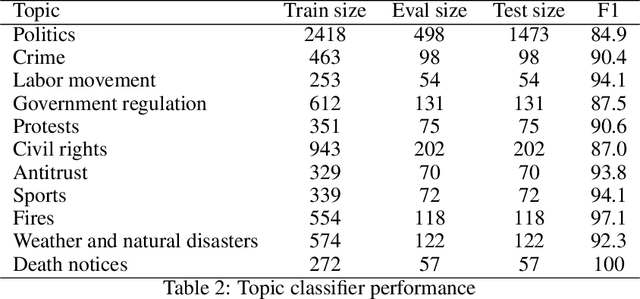
In the U.S. historically, local newspapers drew their content largely from newswires like the Associated Press. Historians argue that newswires played a pivotal role in creating a national identity and shared understanding of the world, but there is no comprehensive archive of the content sent over newswires. We reconstruct such an archive by applying a customized deep learning pipeline to hundreds of terabytes of raw image scans from thousands of local newspapers. The resulting dataset contains 2.7 million unique public domain U.S. newswire articles, written between 1878 and 1977. Locations in these articles are georeferenced, topics are tagged using customized neural topic classification, named entities are recognized, and individuals are disambiguated to Wikipedia using a novel entity disambiguation model. To construct the Newswire dataset, we first recognize newspaper layouts and transcribe around 138 millions structured article texts from raw image scans. We then use a customized neural bi-encoder model to de-duplicate reproduced articles, in the presence of considerable abridgement and noise, quantifying how widely each article was reproduced. A text classifier is used to ensure that we only include newswire articles, which historically are in the public domain. The structured data that accompany the texts provide rich information about the who (disambiguated individuals), what (topics), and where (georeferencing) of the news that millions of Americans read over the course of a century. We also include Library of Congress metadata information about the newspapers that ran the articles on their front pages. The Newswire dataset is useful both for large language modeling - expanding training data beyond what is available from modern web texts - and for studying a diversity of questions in computational linguistics, social science, and the digital humanities.
EfficientOCR: An Extensible, Open-Source Package for Efficiently Digitizing World Knowledge
Oct 16, 2023
Billions of public domain documents remain trapped in hard copy or lack an accurate digitization. Modern natural language processing methods cannot be used to index, retrieve, and summarize their texts; conduct computational textual analyses; or extract information for statistical analyses, and these texts cannot be incorporated into language model training. Given the diversity and sheer quantity of public domain texts, liberating them at scale requires optical character recognition (OCR) that is accurate, extremely cheap to deploy, and sample-efficient to customize to novel collections, languages, and character sets. Existing OCR engines, largely designed for small-scale commercial applications in high resource languages, often fall short of these requirements. EffOCR (EfficientOCR), a novel open-source OCR package, meets both the computational and sample efficiency requirements for liberating texts at scale by abandoning the sequence-to-sequence architecture typically used for OCR, which takes representations from a learned vision model as inputs to a learned language model. Instead, EffOCR models OCR as a character or word-level image retrieval problem. EffOCR is cheap and sample efficient to train, as the model only needs to learn characters' visual appearance and not how they are used in sequence to form language. Models in the EffOCR model zoo can be deployed off-the-shelf with only a few lines of code. Importantly, EffOCR also allows for easy, sample efficient customization with a simple model training interface and minimal labeling requirements due to its sample efficiency. We illustrate the utility of EffOCR by cheaply and accurately digitizing 20 million historical U.S. newspaper scans, evaluating zero-shot performance on randomly selected documents from the U.S. National Archives, and accurately digitizing Japanese documents for which all other OCR solutions failed.
LinkTransformer: A Unified Package for Record Linkage with Transformer Language Models
Sep 02, 2023
Linking information across sources is fundamental to a variety of analyses in social science, business, and government. While large language models (LLMs) offer enormous promise for improving record linkage in noisy datasets, in many domains approximate string matching packages in popular softwares such as R and Stata remain predominant. These packages have clean, simple interfaces and can be easily extended to a diversity of languages. Our open-source package LinkTransformer aims to extend the familiarity and ease-of-use of popular string matching methods to deep learning. It is a general purpose package for record linkage with transformer LLMs that treats record linkage as a text retrieval problem. At its core is an off-the-shelf toolkit for applying transformer models to record linkage with four lines of code. LinkTransformer contains a rich repository of pre-trained transformer semantic similarity models for multiple languages and supports easy integration of any transformer language model from Hugging Face or OpenAI. It supports standard functionality such as blocking and linking on multiple noisy fields. LinkTransformer APIs also perform other common text data processing tasks, e.g., aggregation, noisy de-duplication, and translation-free cross-lingual linkage. Importantly, LinkTransformer also contains comprehensive tools for efficient model tuning, to facilitate different levels of customization when off-the-shelf models do not provide the required accuracy. Finally, to promote reusability, reproducibility, and extensibility, LinkTransformer makes it easy for users to contribute their custom-trained models to its model hub. By combining transformer language models with intuitive APIs that will be familiar to many users of popular string matching packages, LinkTransformer aims to democratize the benefits of LLMs among those who may be less familiar with deep learning frameworks.
American Stories: A Large-Scale Structured Text Dataset of Historical U.S. Newspapers
Aug 24, 2023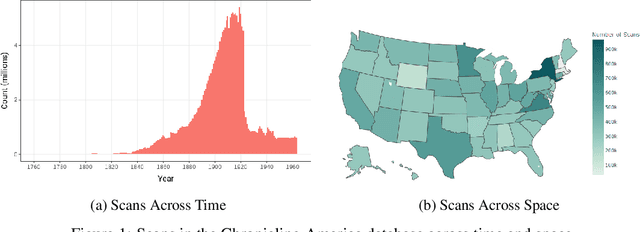
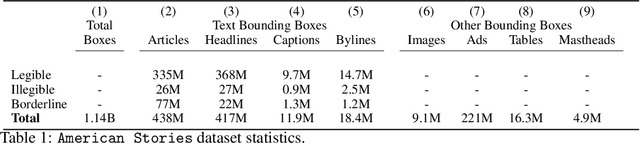

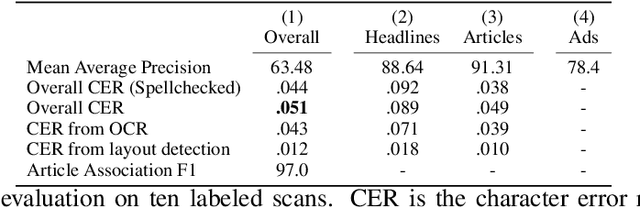
Existing full text datasets of U.S. public domain newspapers do not recognize the often complex layouts of newspaper scans, and as a result the digitized content scrambles texts from articles, headlines, captions, advertisements, and other layout regions. OCR quality can also be low. This study develops a novel, deep learning pipeline for extracting full article texts from newspaper images and applies it to the nearly 20 million scans in Library of Congress's public domain Chronicling America collection. The pipeline includes layout detection, legibility classification, custom OCR, and association of article texts spanning multiple bounding boxes. To achieve high scalability, it is built with efficient architectures designed for mobile phones. The resulting American Stories dataset provides high quality data that could be used for pre-training a large language model to achieve better understanding of historical English and historical world knowledge. The dataset could also be added to the external database of a retrieval-augmented language model to make historical information - ranging from interpretations of political events to minutiae about the lives of people's ancestors - more widely accessible. Furthermore, structured article texts facilitate using transformer-based methods for popular social science applications like topic classification, detection of reproduced content, and news story clustering. Finally, American Stories provides a massive silver quality dataset for innovating multimodal layout analysis models and other multimodal applications.
A Massive Scale Semantic Similarity Dataset of Historical English
Jun 30, 2023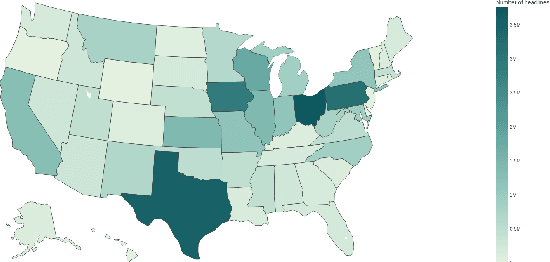
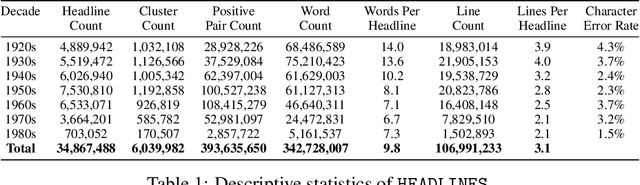


A diversity of tasks use language models trained on semantic similarity data. While there are a variety of datasets that capture semantic similarity, they are either constructed from modern web data or are relatively small datasets created in the past decade by human annotators. This study utilizes a novel source, newly digitized articles from off-copyright, local U.S. newspapers, to assemble a massive-scale semantic similarity dataset spanning 70 years from 1920 to 1989 and containing nearly 400M positive semantic similarity pairs. Historically, around half of articles in U.S. local newspapers came from newswires like the Associated Press. While local papers reproduced articles from the newswire, they wrote their own headlines, which form abstractive summaries of the associated articles. We associate articles and their headlines by exploiting document layouts and language understanding. We then use deep neural methods to detect which articles are from the same underlying source, in the presence of substantial noise and abridgement. The headlines of reproduced articles form positive semantic similarity pairs. The resulting publicly available HEADLINES dataset is significantly larger than most existing semantic similarity datasets and covers a much longer span of time. It will facilitate the application of contrastively trained semantic similarity models to a variety of tasks, including the study of semantic change across space and time.