 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Entity Coreference and Disambiguation for Historical Texts
Paper and Code
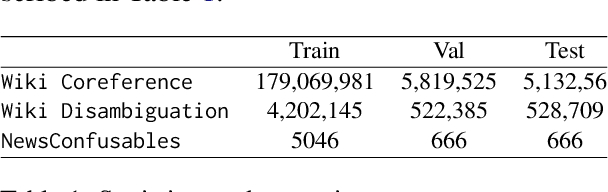
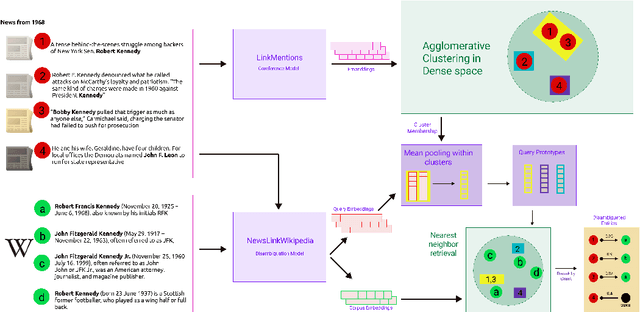
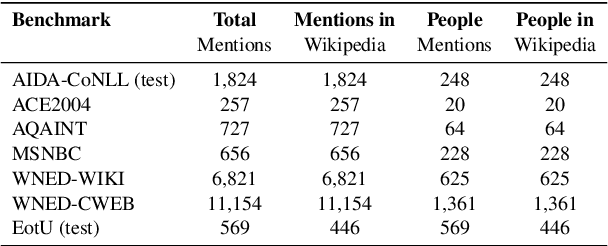

Massive-scale historical document collections are crucial for social science research. Despite increasing digitization, these documents typically lack unique cross-document identifiers for individuals mentioned within the texts, as well as individual identifiers from external knowledgebases like Wikipedia/Wikidata. Existing entity disambiguation methods often fall short in accuracy for historical documents, which are replete with individuals not remembered in contemporary knowledgebases. This study makes three key contributions to improve cross-document coreference resolution and disambiguation in historical texts: a massive-scale training dataset replete with hard negatives - that sources over 190 million entity pairs from Wikipedia contexts and disambiguation pages - high-quality evaluation data from hand-labeled historical newswire articles, and trained models evaluated on this historical benchmark. We contrastively train bi-encoder models for coreferencing and disambiguating individuals in historical texts, achieving accurate, scalable performance that identifies out-of-knowledgebase individuals. Our approach significantly surpasses other entity disambiguation models on our historical newswire benchmark. Our models also demonstrate competitive performance on modern entity disambiguation benchmarks, particularly certain news disambiguation datasets.