 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis
Mar 29, 2021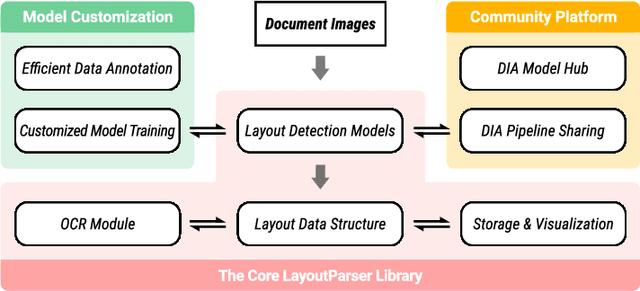
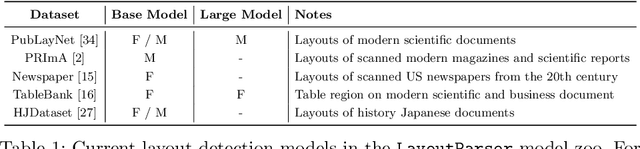

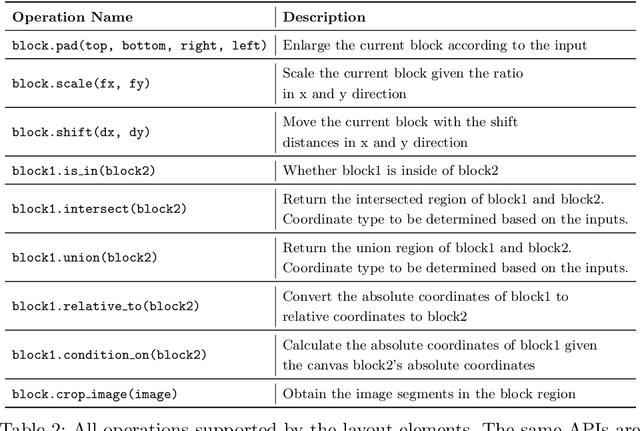
Recent advances in document image analysis (DIA) have been primarily driven by the application of neural networks. Ideally, research outcomes could be easily deployed in production and extended for further investigation. However, various factors like loosely organized codebases and sophisticated model configurations complicate the easy reuse of important innovations by a wide audience. Though there have been on-going efforts to improve reusability and simplify deep learning (DL) model development in disciplines like natural language processing and computer vision, none of them are optimized for challenges in the domain of DIA. This represents a major gap in the existing toolkit, as DIA is central to academic research across a wide range of disciplines in the social sciences and humanities. This paper introduces layoutparser, an open-source library for streamlining the usage of DL in DIA research and applications. The core layoutparser library comes with a set of simple and intuitive interfaces for applying and customizing DL models for layout detection, character recognition, and many other document processing tasks. To promote extensibility, layoutparser also incorporates a community platform for sharing both pre-trained models and full document digitization pipelines. We demonstrate that layoutparser is helpful for both lightweight and large-scale digitization pipelines in real-word use cases. The library is publicly available at https://layout-parser.github.io/.
OLALA: Object-Level Active Learning Based Layout Annotation
Oct 14, 2020

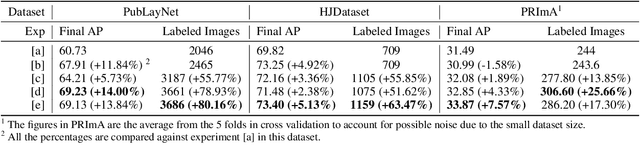
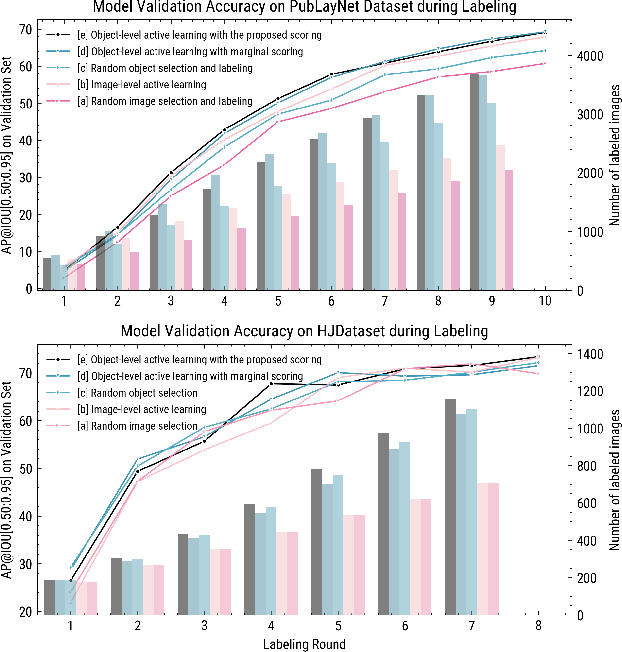
In layout object detection problems, the ground-truth datasets are constructed by annotating object instances individually. Yet active learning for object detection is typically conducted at the image level, not at the object level. Because objects appear with different frequencies across images, image-level active learning may be subject to over-exposure to common objects. This reduces the efficiency of human labeling. This work introduces an Object-Level Active Learning based Layout Annotation framework, OLALA, which includes an object scoring method and a prediction correction algorithm. The object scoring method estimates the object prediction informativeness considering both the object category and the location. It selects only the most ambiguous object prediction regions within an image for annotators to label, optimizing the use of the annotation budget. For the unselected model predictions, we propose a correction algorithm to rectify two types of potential errors with minor supervision from ground-truths. The human annotated and model predicted objects are then merged as new image annotations for training the object detection models. In simulated labeling experiments, we show that OLALA helps to create the dataset more efficiently and report strong accuracy improvements of the trained models compared to image-level active learning baselines. The code is available at https://github.com/lolipopshock/Detectron2_AL.