 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLALA: Object-Level Active Learning Based Layout Annotation
Paper and Code


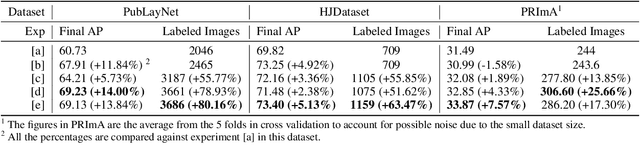
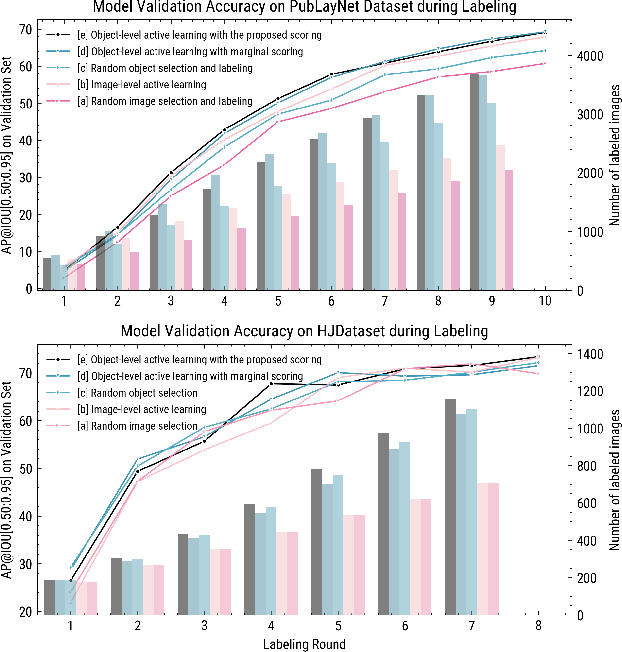
In layout object detection problems, the ground-truth datasets are constructed by annotating object instances individually. Yet active learning for object detection is typically conducted at the image level, not at the object level. Because objects appear with different frequencies across images, image-level active learning may be subject to over-exposure to common objects. This reduces the efficiency of human labeling. This work introduces an Object-Level Active Learning based Layout Annotation framework, OLALA, which includes an object scoring method and a prediction correction algorithm. The object scoring method estimates the object prediction informativeness considering both the object category and the location. It selects only the most ambiguous object prediction regions within an image for annotators to label, optimizing the use of the annotation budget. For the unselected model predictions, we propose a correction algorithm to rectify two types of potential errors with minor supervision from ground-truths. The human annotated and model predicted objects are then merged as new image annotations for training the object detection models. In simulated labeling experiments, we show that OLALA helps to create the dataset more efficiently and report strong accuracy improvements of the trained models compared to image-level active learning baselines. The code is available at https://github.com/lolipopshock/Detectron2_AL.