 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Complexity of the Bipartite Polarization Problem: from Neutral to Highly Polarized Discussions
Jul 21, 2023
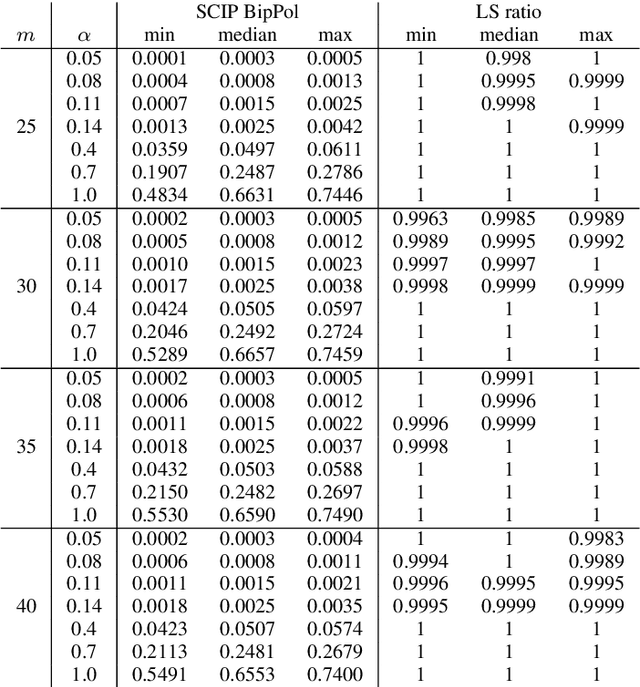
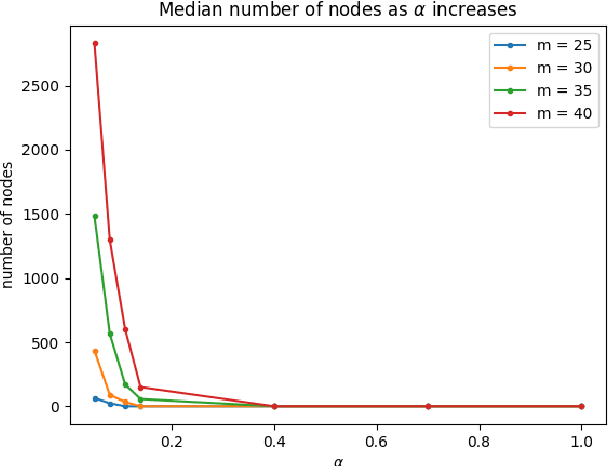
The Bipartite Polarization Problem is an optimization problem where the goal is to find the highest polarized bipartition on a weighted and labelled graph that represents a debate developed through some social network, where nodes represent user's opinions and edges agreement or disagreement between users. This problem can be seen as a generalization of the maxcut problem, and in previous work approximate solutions and exact solutions have been obtained for real instances obtained from Reddit discussions, showing that such real instances seem to be very easy to solve. In this paper, we investigate further the complexity of this problem, by introducing an instance generation model where a single parameter controls the polarization of the instances in such a way that this correlates with the average complexity to solve those instances. The average complexity results we obtain are consistent with our hypothesis: the higher the polarization of the instance, the easier is to find the corresponding polarized bipartition.
On Logic-Based Explainability with Partially Specified Inputs
Jun 27, 2023



In the practical deployment of machine learning (ML) models, missing data represents a recurring challenge. Missing data is often addressed when training ML models. But missing data also needs to be addressed when deciding predictions and when explaining those predictions. Missing data represents an opportunity to partially specify the inputs of the prediction to be explained. This paper studies the computation of logic-based explanations in the presence of partially specified inputs. The paper shows that most of the algorithms proposed in recent years for computing logic-based explanations can be generalized for computing explanations given the partially specified inputs. One related result is that the complexity of computing logic-based explanations remains unchanged. A similar result is proved in the case of logic-based explainability subject to input constraints. Furthermore, the proposed solution for computing explanations given partially specified inputs is applied to classifiers obtained from well-known public datasets, thereby illustrating a number of novel explainability use cases.