 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Explanation Game -- Rekindled (Extended Version)
Jan 20, 2025

Recent work demonstrated the existence of critical flaws in the current use of Shapley values in explainable AI (XAI), i.e. the so-called SHAP scores. These flaws are significant in that the scores provided to a human decision-maker can be misleading. Although these negative results might appear to indicate that Shapley values ought not be used in XAI, this paper argues otherwise. Concretely, this paper proposes a novel definition of SHAP scores that overcomes existing flaws. Furthermore, the paper outlines a practically efficient solution for the rigorous estimation of the novel SHAP scores. Preliminary experimental results confirm our claims, and further underscore the flaws of the current SHAP scores.
SHAP scores fail pervasively even when Lipschitz succeeds
Dec 18, 2024The ubiquitous use of Shapley values in eXplainable AI (XAI) has been triggered by the tool SHAP, and as a result are commonly referred to as SHAP scores. Recent work devised examples of machine learning (ML) classifiers for which the computed SHAP scores are thoroughly unsatisfactory, by allowing human decision-makers to be misled. Nevertheless, such examples could be perceived as somewhat artificial, since the selected classes must be interpreted as numeric. Furthermore, it was unclear how general were the issues identified with SHAP scores. This paper answers these criticisms. First, the paper shows that for Boolean classifiers there are arbitrarily many examples for which the SHAP scores must be deemed unsatisfactory. Second, the paper shows that the issues with SHAP scores are also observed in the case of regression models. In addition, the paper studies the class of regression models that respect Lipschitz continuity, a measure of a function's rate of change that finds important recent uses in ML, including model robustness. Concretely, the paper shows that the issues with SHAP scores occur even for regression models that respect Lipschitz continuity. Finally, the paper shows that the same issues are guaranteed to exist for arbitrarily differentiable regression models.
From SHAP Scores to Feature Importance Scores
May 20, 2024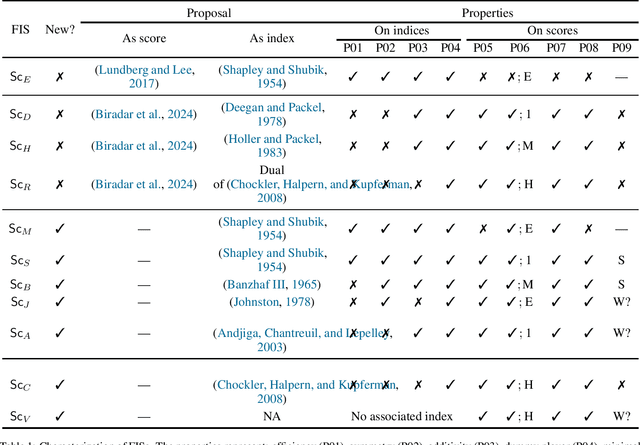
A central goal of eXplainable Artificial Intelligence (XAI) is to assign relative importance to the features of a Machine Learning (ML) model given some prediction. The importance of this task of explainability by feature attribution is illustrated by the ubiquitous recent use of tools such as SHAP and LIME. Unfortunately, the exact computation of feature attributions, using the game-theoretical foundation underlying SHAP and LIME, can yield manifestly unsatisfactory results, that tantamount to reporting misleading relative feature importance. Recent work targeted rigorous feature attribution, by studying axiomatic aggregations of features based on logic-based definitions of explanations by feature selection. This paper shows that there is an essential relationship between feature attribution and a priori voting power, and that those recently proposed axiomatic aggregations represent a few instantiations of the range of power indices studied in the past. Furthermore, it remains unclear how some of the most widely used power indices might be exploited as feature importance scores (FISs), i.e. the use of power indices in XAI, and which of these indices would be the best suited for the purposes of XAI by feature attribution, namely in terms of not producing results that could be deemed as unsatisfactory. This paper proposes novel desirable properties that FISs should exhibit. In addition, the paper also proposes novel FISs exhibiting the proposed properties. Finally, the paper conducts a rigorous analysis of the best-known power indices in terms of the proposed properties.
On Correcting SHAP Scores
Apr 30, 2024Recent work uncovered examples of classifiers for which SHAP scores yield misleading feature attributions. While such examples might be perceived as suggesting the inadequacy of Shapley values for explainability, this paper shows that the source of the identified shortcomings of SHAP scores resides elsewhere. Concretely, the paper makes the case that the failings of SHAP scores result from the characteristic functions used in earlier works. Furthermore, the paper identifies a number of properties that characteristic functions ought to respect, and proposes several novel characteristic functions, each exhibiting one or more of the desired properties. More importantly, some of the characteristic functions proposed in this paper are guaranteed not to exhibit any of the shortcomings uncovered by earlier work. The paper also investigates the impact of the new characteristic functions on the complexity of computing SHAP scores. Finally, the paper proposes modifications to the tool SHAP to use instead one of our novel characteristic functions, thereby eliminating some of the limitations reported for SHAP scores.