 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTELL-TALE: Task Efficient LLMs with Task Aware Layer Elimination
Oct 26, 2025In this paper we introduce Tale, Task-Aware Layer Elimination, an inference-time algorithm that prunes entire transformer layers in an LLM by directly optimizing task-specific validation performance. We evaluate TALE on 9 tasks and 5 models, including LLaMA 3.1 8B, Qwen 2.5 7B, Qwen 2.5 0.5B, Mistral 7B, and Lucie 7B, under both zero-shot and few-shot settings. Unlike prior approaches, TALE requires no retraining and consistently improves accuracy while reducing computational cost across all benchmarks. Furthermore, applying TALE during finetuning leads to additional performance gains. Finally, TALE provides flexible user control over trade-offs between accuracy and efficiency. Mutual information analysis shows that certain layers act as bottlenecks, degrading task-relevant representations. Tale's selective layer removal remedies this problem, producing smaller, faster, and more accurate models that are also faster to fine-tune while offering new insights into transformer interpretability.
Improving in-context learning with a better scoring function
Aug 20, 2025Large language models (LLMs) exhibit a remarkable capacity to learn by analogy, known as in-context learning (ICL). However, recent studies have revealed limitations in this ability. In this paper, we examine these limitations on tasks involving first-order quantifiers such as {\em all} and {\em some}, as well as on ICL with linear functions. We identify Softmax, the scoring function in attention mechanism, as a contributing factor to these constraints. To address this, we propose \textbf{scaled signed averaging (SSA)}, a novel alternative to Softmax. Empirical results show that SSA dramatically improves performance on our target tasks. Furthermore, we evaluate both encoder-only and decoder-only transformers models with SSA, demonstrating that they match or exceed their Softmax-based counterparts across a variety of linguistic probing tasks.
Two in context learning tasks with complex functions
Feb 05, 2025We examine two in context learning (ICL) tasks with mathematical functions in several train and test settings for transformer models. Our study generalizes work on linear functions by showing that small transformers, even models with attention layers only, can approximate arbitrary polynomial functions and hence continuous functions under certain conditions. Our models also can approximate previously unseen classes of polynomial functions, as well as the zeros of complex functions. Our models perform far better on this task than LLMs like GPT4 and involve complex reasoning when provided with suitable training data and methods. Our models also have important limitations; they fail to generalize outside of training distributions and so don't learn class forms of functions. We explain why this is so.
Re-examining learning linear functions in context
Nov 18, 2024In context learning (ICL) is an attractive method of solving a wide range of problems. Inspired by Garg et al. (2022), we look closely at ICL in a variety of train and test settings for several transformer models of different sizes trained from scratch. Our study complements prior work by pointing out several systematic failures of these models to generalize to data not in the training distribution, thereby showing some limitations of ICL. We find that models adopt a strategy for this task that is very different from standard solutions.
On Explaining with Attention Matrices
Oct 24, 2024

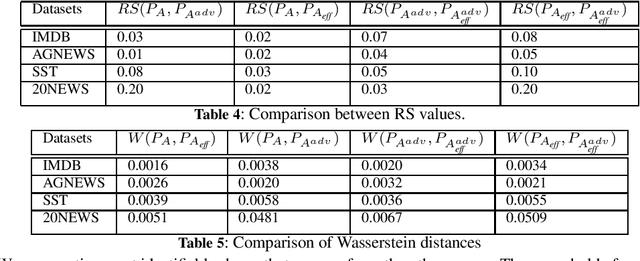

This paper explores the much discussed, possible explanatory link between attention weights (AW) in transformer models and predicted output. Contrary to intuition and early research on attention, more recent prior research has provided formal arguments and empirical evidence that AW are not explanatorily relevant. We show that the formal arguments are incorrect. We introduce and effectively compute efficient attention, which isolates the effective components of attention matrices in tasks and models in which AW play an explanatory role. We show that efficient attention has a causal role (provides minimally necessary and sufficient conditions) for predicting model output in NLP tasks requiring contextual information, and we show, contrary to [7], that efficient attention matrices are probability distributions and are effectively calculable. Thus, they should play an important part in the explanation of attention based model behavior. We offer empirical experiments in support of our method illustrating various properties of efficient attention with various metrics on four datasets.