 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKisMATH: Do LLMs Have Knowledge of Implicit Structures in Mathematical Reasoning?
Jul 15, 2025



Chain-of-thought traces have been shown to improve performance of large language models in a plethora of reasoning tasks, yet there is no consensus on the mechanism through which this performance boost is achieved. To shed more light on this, we introduce Causal CoT Graphs (CCGs), which are directed acyclic graphs automatically extracted from reasoning traces that model fine-grained causal dependencies in the language model output. A collection of $1671$ mathematical reasoning problems from MATH500, GSM8K and AIME, and their associated CCGs are compiled into our dataset -- \textbf{KisMATH}. Our detailed empirical analysis with 15 open-weight LLMs shows that (i) reasoning nodes in the CCG are mediators for the final answer, a condition necessary for reasoning; and (ii) LLMs emphasise reasoning paths given by the CCG, indicating that models internally realise structures akin to our graphs. KisMATH enables controlled, graph-aligned interventions and opens up avenues for further investigation into the role of chain-of-thought in LLM reasoning.
sudoLLM : On Multi-role Alignment of Language Models
May 20, 2025



User authorization-based access privileges are a key feature in many safety-critical systems, but have thus far been absent from the large language model (LLM) realm. In this work, drawing inspiration from such access control systems, we introduce sudoLLM, a novel framework that results in multi-role aligned LLMs, i.e., LLMs that account for, and behave in accordance with, user access rights. sudoLLM injects subtle user-based biases into queries and trains an LLM to utilize this bias signal in order to produce sensitive information if and only if the user is authorized. We present empirical results demonstrating that this approach shows substantially improved alignment, generalization, and resistance to prompt-based jailbreaking attacks. The persistent tension between the language modeling objective and safety alignment, which is often exploited to jailbreak LLMs, is somewhat resolved with the aid of the injected bias signal. Our framework is meant as an additional security layer, and complements existing guardrail mechanisms for enhanced end-to-end safety with LLMs.
On Measuring Intrinsic Causal Attributions in Deep Neural Networks
May 14, 2025Quantifying the causal influence of input features within neural networks has become a topic of increasing interest. Existing approaches typically assess direct, indirect, and total causal effects. This work treats NNs as structural causal models (SCMs) and extends our focus to include intrinsic causal contributions (ICC). We propose an identifiable generative post-hoc framework for quantifying ICC. We also draw a relationship between ICC and Sobol' indices. Our experiments on synthetic and real-world datasets demonstrate that ICC generates more intuitive and reliable explanations compared to existing global explanation techniques.
Deep Learning Based Recalibration of SDSS and DESI BAO Alleviates Hubble and Clustering Tensions
Dec 19, 2024Conventional calibration of Baryon Acoustic Oscillations (BAO) data relies on estimation of the sound horizon at drag epoch $r_d$ from early universe observations by assuming a cosmological model. We present a recalibration of two independent BAO datasets, SDSS and DESI, by employing deep learning techniques for model-independent estimation of $r_d$, and explore the impacts on $\Lambda$CDM cosmological parameters. Significant reductions in both Hubble ($H_0$) and clustering ($S_8$) tensions are observed for both the recalibrated datasets. Moderate shifts in some other parameters hint towards further exploration of such data-driven approaches.
Language Models are Crossword Solvers
Jun 14, 2024



Crosswords are a form of word puzzle that require a solver to demonstrate a high degree of proficiency in natural language understanding, wordplay, reasoning, and world knowledge, along with adherence to character and length constraints. In this paper we tackle the challenge of solving crosswords with Large Language Models (LLMs). We demonstrate that the current generation of state-of-the art (SoTA) language models show significant competence at deciphering cryptic crossword clues, and outperform previously reported SoTA results by a factor of 2-3 in relevant benchmarks. We also develop a search algorithm that builds off this performance to tackle the problem of solving full crossword grids with LLMs for the very first time, achieving an accuracy of 93\% on New York Times crossword puzzles. Contrary to previous work in this area which concluded that LLMs lag human expert performance significantly, our research suggests this gap is a lot narrower.
LADDER: Revisiting the Cosmic Distance Ladder with Deep Learning Approaches and Exploring its Applications
Jan 30, 2024We investigate the prospect of reconstructing the ``cosmic distance ladder'' of the Universe using a novel deep learning framework called LADDER - Learning Algorithm for Deep Distance Estimation and Reconstruction. LADDER is trained on the apparent magnitude data from the Pantheon Type Ia supernovae compilation, incorporating the full covariance information among data points, to produce predictions along with corresponding errors. After employing several validation tests with a number of deep learning models, we pick LADDER as the best performing one. We then demonstrate applications of our method in the cosmological context, that include serving as a model-independent tool for consistency checks for other datasets like baryon acoustic oscillations, calibration of high-redshift datasets such as gamma ray bursts, use as a model-independent mock catalog generator for future probes, etc. Our analysis advocates for interesting yet cautious consideration of machine learning applications in these contexts.
ChessVision -- A Dataset for Logically Coherent Multi-label Classification
Nov 21, 2023
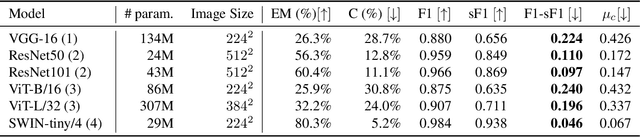

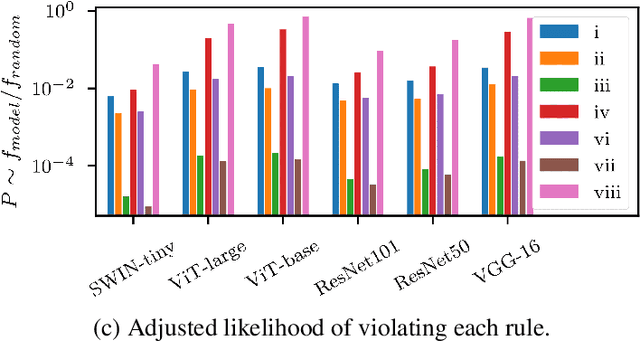
Starting with early successes in computer vision tasks, deep learning based techniques have since overtaken state of the art approaches in a multitude of domains. However, it has been demonstrated time and again that these techniques fail to capture semantic context and logical constraints, instead often relying on spurious correlations to arrive at the answer. Since application of deep learning techniques to critical scenarios are dependent on adherence to domain specific constraints, several attempts have been made to address this issue. One limitation holding back a thorough exploration of this area, is a lack of suitable datasets which feature a rich set of rules. In order to address this, we present the ChessVision Dataset, consisting of 200,000+ images of annotated chess games in progress, requiring recreation of the game state from its corresponding image. This is accompanied by a curated set of rules which constrains the set of predictions to "reasonable" game states, and are designed to probe key semantic abilities like localization and enumeration. Alongside standard metrics, additional metrics to measure performance with regards to logical consistency is presented. We analyze several popular and state of the art vision models on this task, and show that, although their performance on standard metrics are laudable, they produce a plethora of incoherent results, indicating that this dataset presents a significant challenge for future works.
DOST -- Domain Obedient Self-supervised Training for Multi Label Classification with Noisy Labels
Aug 09, 2023The enormous demand for annotated data brought forth by deep learning techniques has been accompanied by the problem of annotation noise. Although this issue has been widely discussed in machine learning literature, it has been relatively unexplored in the context of "multi-label classification" (MLC) tasks which feature more complicated kinds of noise. Additionally, when the domain in question has certain logical constraints, noisy annotations often exacerbate their violations, making such a system unacceptable to an expert. This paper studies the effect of label noise on domain rule violation incidents in the MLC task, and incorporates domain rules into our learning algorithm to mitigate the effect of noise. We propose the Domain Obedient Self-supervised Training (DOST) paradigm which not only makes deep learning models more aligned to domain rules, but also improves learning performance in key metrics and minimizes the effect of annotation noise. This novel approach uses domain guidance to detect offending annotations and deter rule-violating predictions in a self-supervised manner, thus making it more "data efficient" and domain compliant. Empirical studies, performed over two large scale multi-label classification datasets, demonstrate that our method results in improvement across the board, and often entirely counteracts the effect of noise.
Analyzing Semantic Faithfulness of Language Models via Input Intervention on Conversational Question Answering
Dec 21, 2022Transformer-based language models have been shown to be highly effective for several NLP tasks. In this paper, we consider three transformer models, BERT, RoBERTa, and XLNet, in both small and large version, and investigate how faithful their representations are with respect to the semantic content of texts. We formalize a notion of semantic faithfulness, in which the semantic content of a text should causally figure in a model's inferences in question answering. We then test this notion by observing a model's behavior on answering questions about a story after performing two novel semantic interventions -- deletion intervention and negation intervention. While transformer models achieve high performance on standard question answering tasks, we show that they fail to be semantically faithful once we perform these interventions for a significant number of cases (~50% for deletion intervention, and ~20% drop in accuracy for negation intervention). We then propose an intervention-based training regime that can mitigate the undesirable effects for deletion intervention by a significant margin (from ~50% to ~6%). We analyze the inner-workings of the models to better understand the effectiveness of intervention-based training for deletion intervention. But we show that this training does not attenuate other aspects of semantic unfaithfulness such as the models' inability to deal with negation intervention or to capture the predicate-argument structure of texts. We also test InstructGPT, via prompting, for its ability to handle the two interventions and to capture predicate-argument structure. While InstructGPT models do achieve very high performance on predicate-argument structure task, they fail to respond adequately to our deletion and negation interventions.