 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChessVision -- A Dataset for Logically Coherent Multi-label Classification
Paper and Code

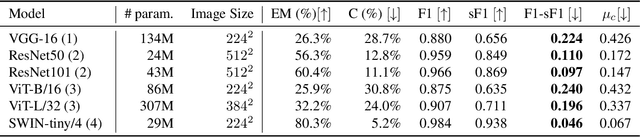

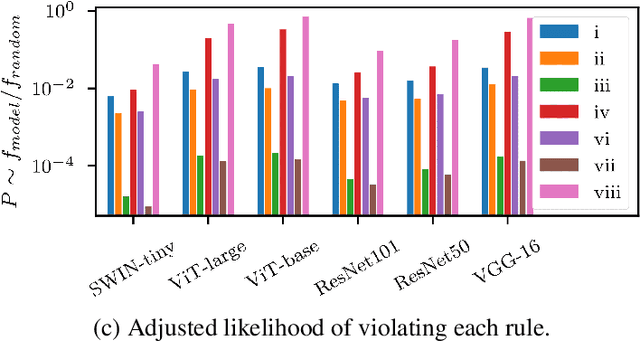
Starting with early successes in computer vision tasks, deep learning based techniques have since overtaken state of the art approaches in a multitude of domains. However, it has been demonstrated time and again that these techniques fail to capture semantic context and logical constraints, instead often relying on spurious correlations to arrive at the answer. Since application of deep learning techniques to critical scenarios are dependent on adherence to domain specific constraints, several attempts have been made to address this issue. One limitation holding back a thorough exploration of this area, is a lack of suitable datasets which feature a rich set of rules. In order to address this, we present the ChessVision Dataset, consisting of 200,000+ images of annotated chess games in progress, requiring recreation of the game state from its corresponding image. This is accompanied by a curated set of rules which constrains the set of predictions to "reasonable" game states, and are designed to probe key semantic abilities like localization and enumeration. Alongside standard metrics, additional metrics to measure performance with regards to logical consistency is presented. We analyze several popular and state of the art vision models on this task, and show that, although their performance on standard metrics are laudable, they produce a plethora of incoherent results, indicating that this dataset presents a significant challenge for future works.