 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning for Handwritten Text Line Recognition
Paper and Code
Dec 05, 2013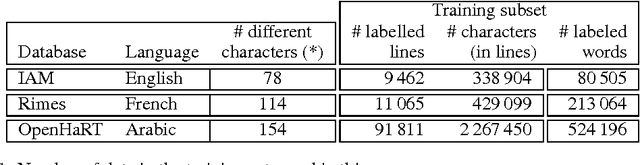
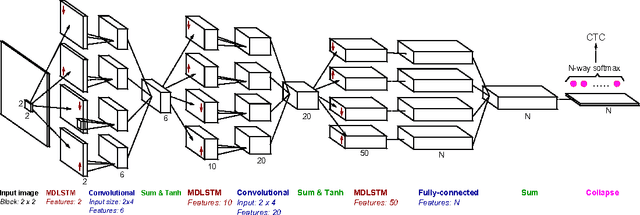
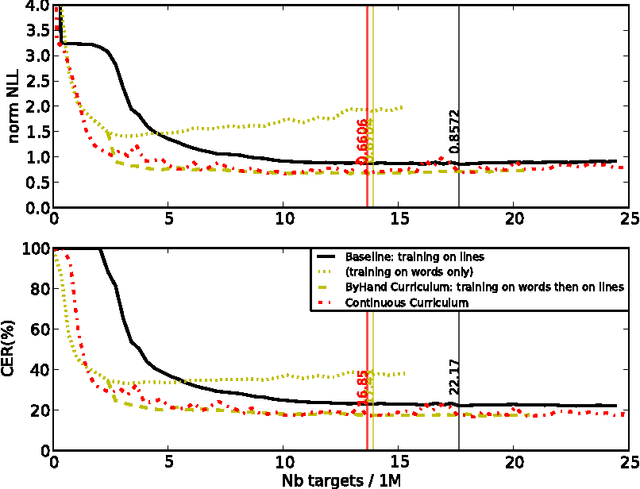
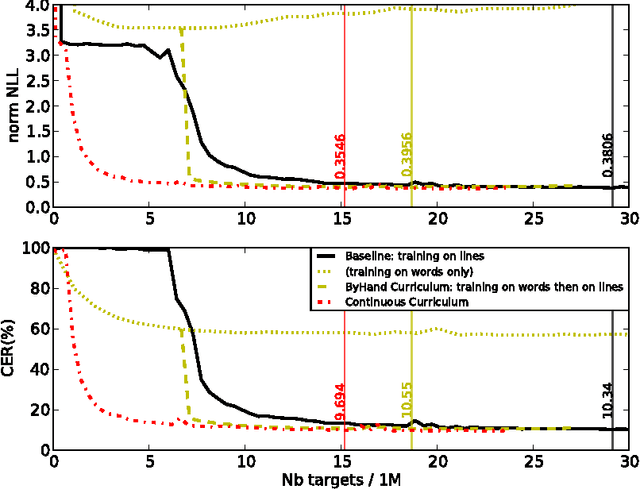
Recurrent Neural Networks (RNN) have recently achieved the best performance in off-line Handwriting Text Recognition. At the same time, learning RNN by gradient descent leads to slow convergence, and training times are particularly long when the training database consists of full lines of text. In this paper, we propose an easy way to accelerate stochastic gradient descent in this set-up, and in the general context of learning to recognize sequences. The principle is called Curriculum Learning, or shaping. The idea is to first learn to recognize short sequences before training on all available training sequences. Experiments on three different handwritten text databases (Rimes, IAM, OpenHaRT) show that a simple implementation of this strategy can significantly speed up the training of RNN for Text Recognition, and even significantly improve performance in some cases.