 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Summarizing Czech Historical Documents and Beyond
Aug 14, 2025Text summarization is the task of shortening a larger body of text into a concise version while retaining its essential meaning and key information. While summarization has been significantly explored in English and other high-resource languages, Czech text summarization, particularly for historical documents, remains underexplored due to linguistic complexities and a scarcity of annotated datasets. Large language models such as Mistral and mT5 have demonstrated excellent results on many natural language processing tasks and languages. Therefore, we employ these models for Czech summarization, resulting in two key contributions: (1) achieving new state-of-the-art results on the modern Czech summarization dataset SumeCzech using these advanced models, and (2) introducing a novel dataset called Posel od \v{C}erchova for summarization of historical Czech documents with baseline results. Together, these contributions provide a great potential for advancing Czech text summarization and open new avenues for research in Czech historical text processing.
Well-calibrated Confidence Measures for Multi-label Text Classification with a Large Number of Labels
Dec 14, 2023
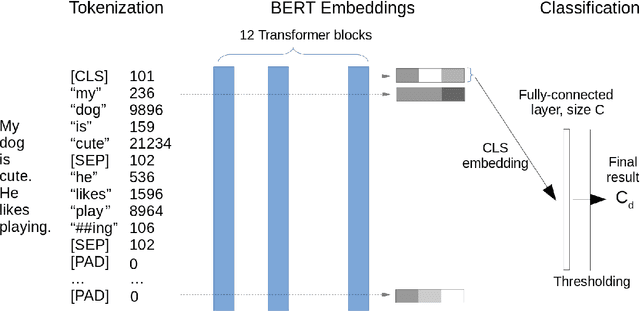
We extend our previous work on Inductive Conformal Prediction (ICP) for multi-label text classification and present a novel approach for addressing the computational inefficiency of the Label Powerset (LP) ICP, arrising when dealing with a high number of unique labels. We present experimental results using the original and the proposed efficient LP-ICP on two English and one Czech language data-sets. Specifically, we apply the LP-ICP on three deep Artificial Neural Network (ANN) classifiers of two types: one based on contextualised (bert) and two on non-contextualised (word2vec) word-embeddings. In the LP-ICP setting we assign nonconformity scores to label-sets from which the corresponding p-values and prediction-sets are determined. Our approach deals with the increased computational burden of LP by eliminating from consideration a significant number of label-sets that will surely have p-values below the specified significance level. This reduces dramatically the computational complexity of the approach while fully respecting the standard CP guarantees. Our experimental results show that the contextualised-based classifier surpasses the non-contextualised-based ones and obtains state-of-the-art performance for all data-sets examined. The good performance of the underlying classifiers is carried on to their ICP counterparts without any significant accuracy loss, but with the added benefits of ICP, i.e. the confidence information encapsulated in the prediction sets. We experimentally demonstrate that the resulting prediction sets can be tight enough to be practically useful even though the set of all possible label-sets contains more than $1e+16$ combinations. Additionally, the empirical error rates of the obtained prediction-sets confirm that our outputs are well-calibrated.
ICDAR 2021 Competition on Historical Map Segmentation
May 27, 2021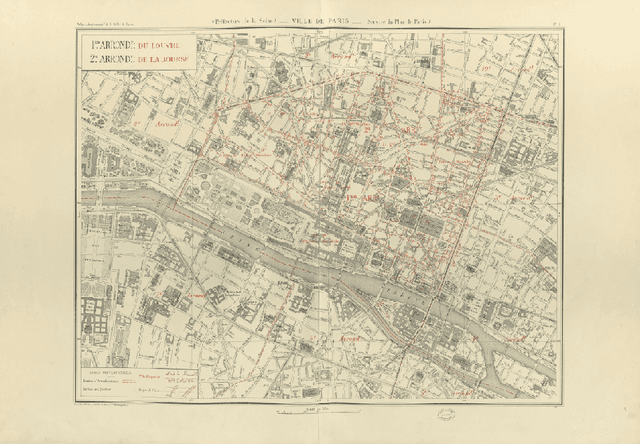
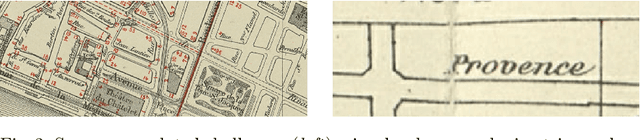
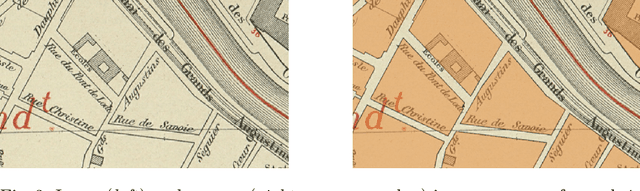
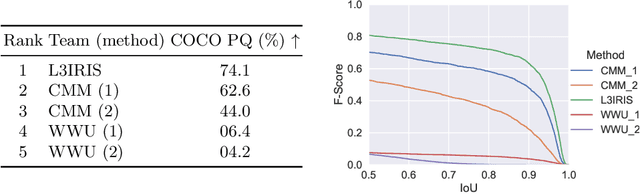
This paper presents the final results of the ICDAR 2021 Competition on Historical Map Segmentation (MapSeg), encouraging research on a series of historical atlases of Paris, France, drawn at 1/5000 scale between 1894 and 1937. The competition featured three tasks, awarded separately. Task~1 consists in detecting building blocks and was won by the L3IRIS team using a DenseNet-121 network trained in a weakly supervised fashion. This task is evaluated on 3 large images containing hundreds of shapes to detect. Task~2 consists in segmenting map content from the larger map sheet, and was won by the UWB team using a U-Net-like FCN combined with a binarization method to increase detection edge accuracy. Task~3 consists in locating intersection points of geo-referencing lines, and was also won by the UWB team who used a dedicated pipeline combining binarization, line detection with Hough transform, candidate filtering, and template matching for intersection refinement. Tasks~2 and~3 are evaluated on 95 map sheets with complex content. Dataset, evaluation tools and results are available under permissive licensing at \url{https://icdar21-mapseg.github.io/}.
On the Effects of Using word2vec Representations in Neural Networks for Dialogue Act Recognition
Oct 22, 2020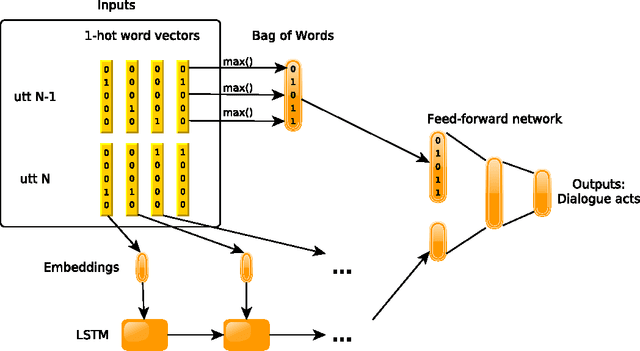


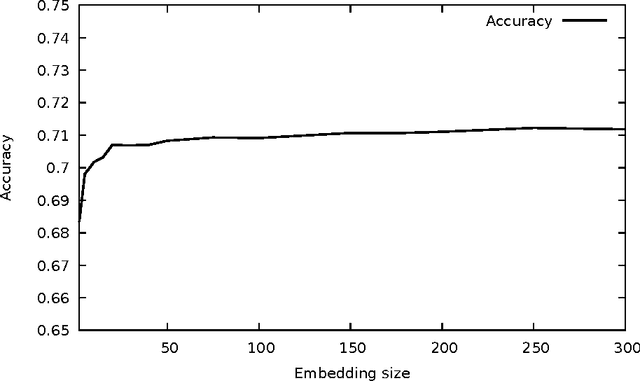
Dialogue act recognition is an important component of a large number of natural language processing pipelines. Many research works have been carried out in this area, but relatively few investigate deep neural networks and word embeddings. This is surprising, given that both of these techniques have proven exceptionally good in most other language-related domains. We propose in this work a new deep neural network that explores recurrent models to capture word sequences within sentences, and further study the impact of pretrained word embeddings. We validate this model on three languages: English, French and Czech. The performance of the proposed approach is consistent across these languages and it is comparable to the state-of-the-art results in English. More importantly, we confirm that deep neural networks indeed outperform a Maximum Entropy classifier, which was expected. However , and this is more surprising, we also found that standard word2vec em-beddings do not seem to bring valuable information for this task and the proposed model, whatever the size of the training corpus is. We thus further analyse the resulting embeddings and conclude that a possible explanation may be related to the mismatch between the type of lexical-semantic information captured by the word2vec embeddings, and the kind of relations between words that is the most useful for the dialogue act recognition task.
Re-ranking for Writer Identification and Writer Retrieval
Jul 14, 2020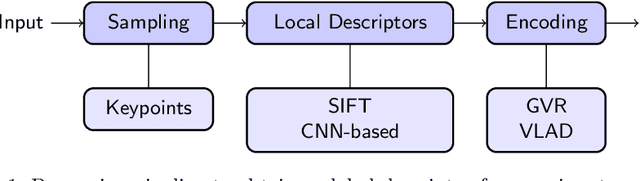
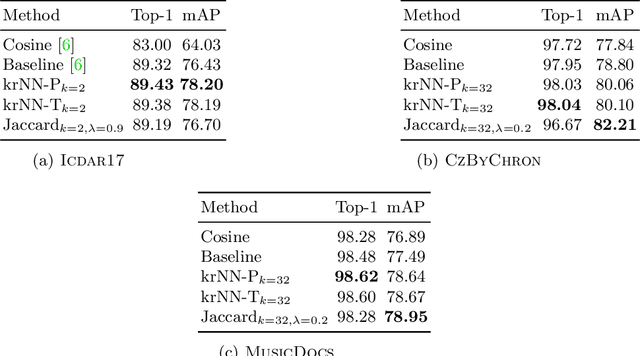

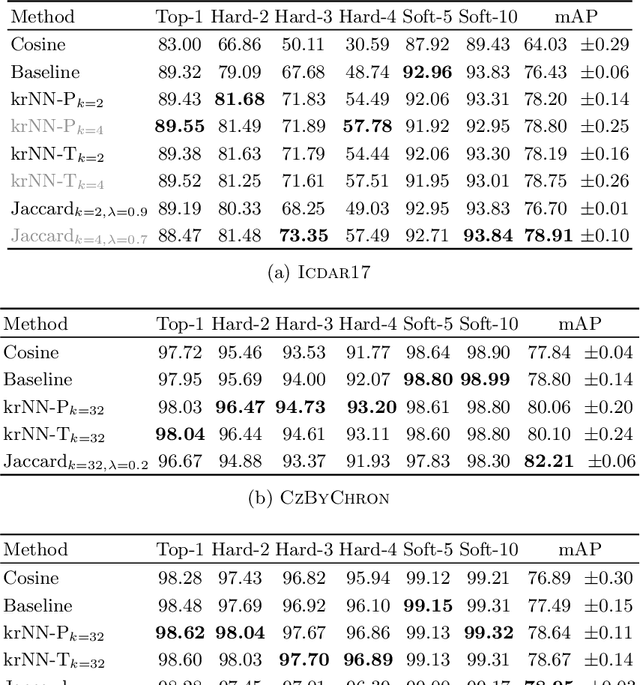
Automatic writer identification is a common problem in document analysis. State-of-the-art methods typically focus on the feature extraction step with traditional or deep-learning-based techniques. In retrieval problems, re-ranking is a commonly used technique to improve the results. Re-ranking refines an initial ranking result by using the knowledge contained in the ranked result, e. g., by exploiting nearest neighbor relations. To the best of our knowledge, re-ranking has not been used for writer identification/retrieval. A possible reason might be that publicly available benchmark datasets contain only few samples per writer which makes a re-ranking less promising. We show that a re-ranking step based on k-reciprocal nearest neighbor relationships is advantageous for writer identification, even if only a few samples per writer are available. We use these reciprocal relationships in two ways: encode them into new vectors, as originally proposed, or integrate them in terms of query-expansion. We show that both techniques outperform the baseline results in terms of mAP on three writer identification datasets.
Cross-lingual Transfer Learning for Dialogue Act Recognition
May 19, 2020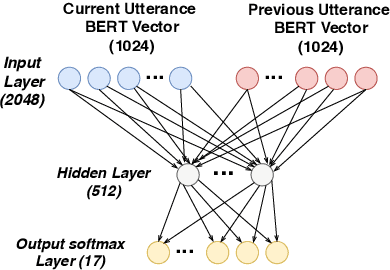
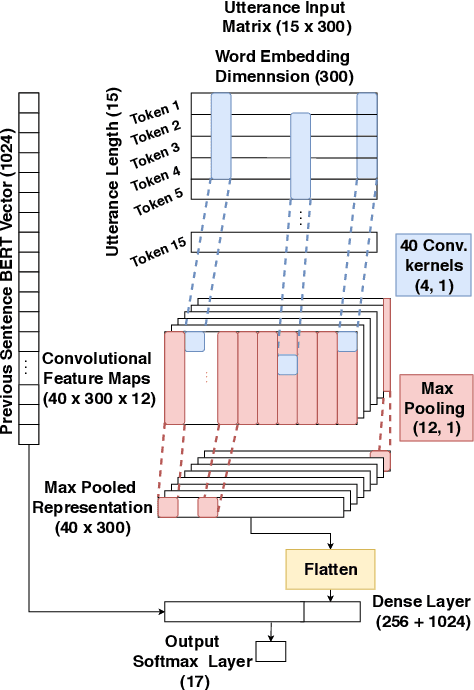

This paper deals with cross-lingual transfer learning for dialogue act (DA) recognition. Besides generic contextual information gathered from pre-trained BERT embeddings, our objective is to transfer models trained on a standard English DA corpus to two other languages, German and French, and to potentially very different types of dialogue with different dialogue acts than the standard well-known DA corpora. The proposed approach thus studies the applicability of automatic DA recognition to specific tasks that may not benefit from a large enough number of manual annotations. A key component of our architecture is the automatic translation module, which limitations are addressed by stacking both foreign and translated words sequences into the same model. We further compare both CNN and multi-head self-attention to compute the speaker turn embeddings and show that in low-resource situations, the best results are obtained by combining all sources of transferred information.
Multi-lingual Dialogue Act Recognition with Deep Learning Methods
Apr 11, 2019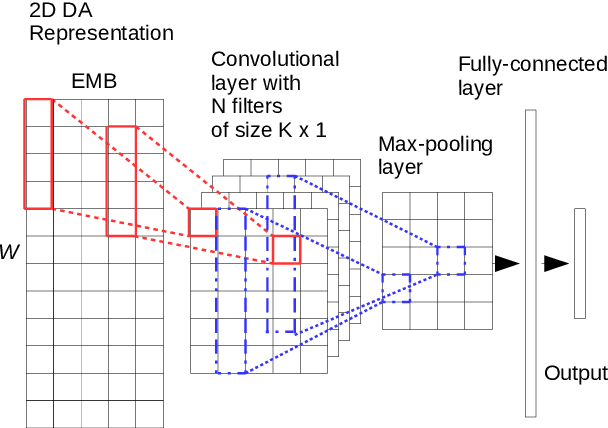
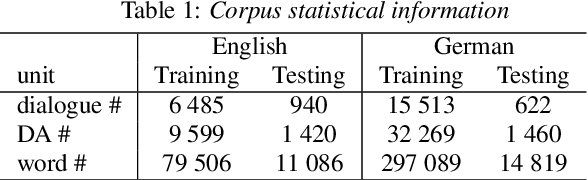
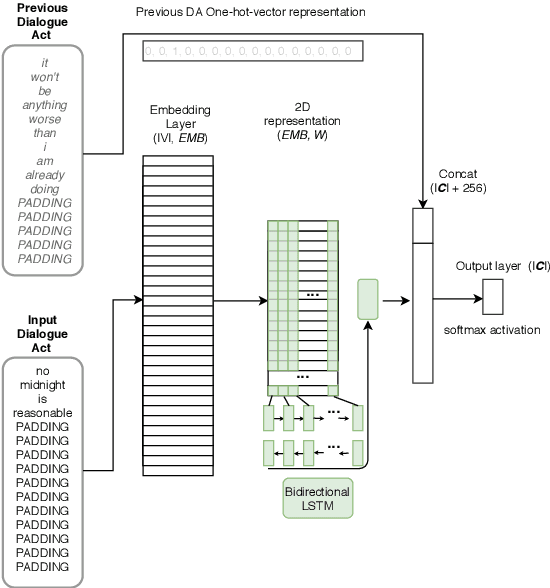
This paper deals with multi-lingual dialogue act (DA) recognition. The proposed approaches are based on deep neural networks and use word2vec embeddings for word representation. Two multi-lingual models are proposed for this task. The first approach uses one general model trained on the embeddings from all available languages. The second method trains the model on a single pivot language and a linear transformation method is used to project other languages onto the pivot language. The popular convolutional neural network and LSTM architectures with different set-ups are used as classifiers. To the best of our knowledge this is the first attempt at multi-lingual DA recognition using neural networks. The multi-lingual models are validated experimentally on two languages from the Verbmobil corpus.
Czech Text Document Corpus v 2.0
Jan 30, 2018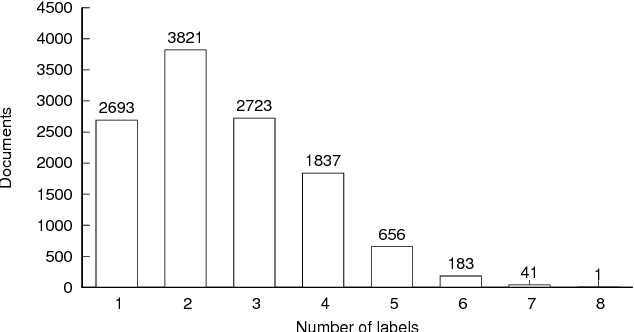
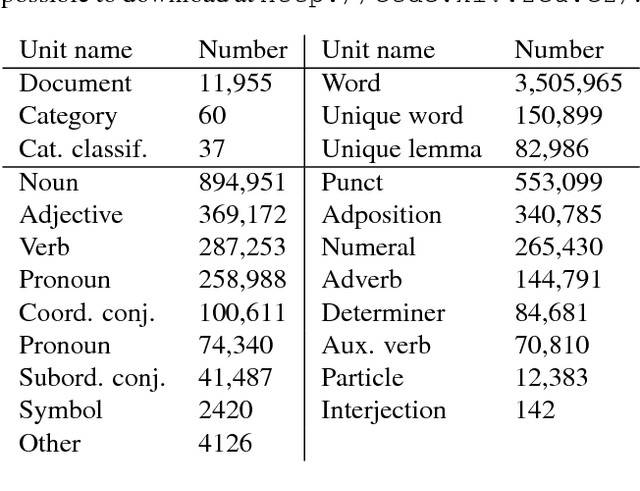
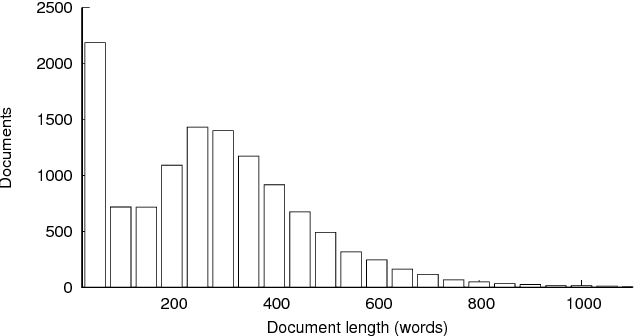

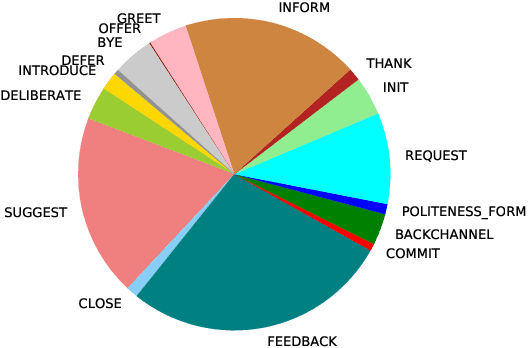
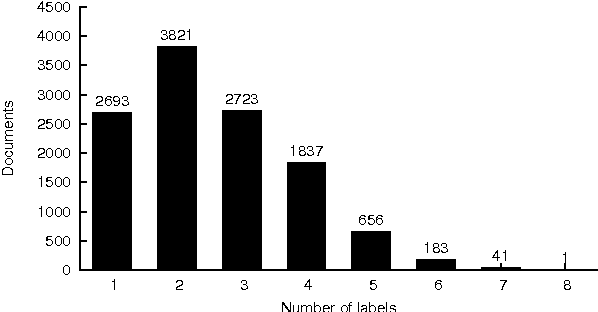
This paper introduces "Czech Text Document Corpus v 2.0", a collection of text documents for automatic document classification in Czech language. It is composed of the text documents provided by the Czech News Agency and is freely available for research purposes at http://ctdc.kiv.zcu.cz/. This corpus was created in order to facilitate a straightforward comparison of the document classification approaches on Czech data. It is particularly dedicated to evaluation of multi-label document classification approaches, because one document is usually labelled with more than one label. Besides the information about the document classes, the corpus is also annotated at the morphological layer. This paper further shows the results of selected state-of-the-art methods on this corpus to offer the possibility of an easy comparison with these approaches.
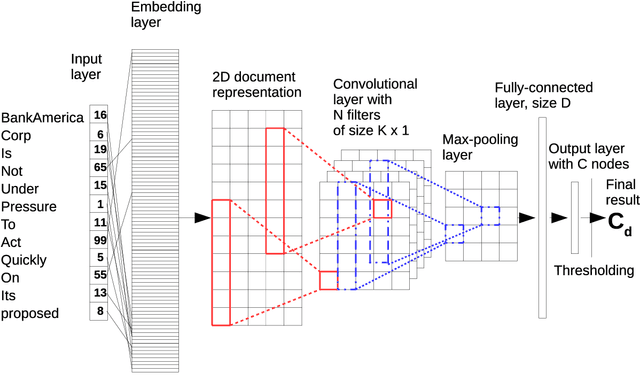
Deep Neural Networks for Czech Multi-label Document Classification
Jan 18, 2017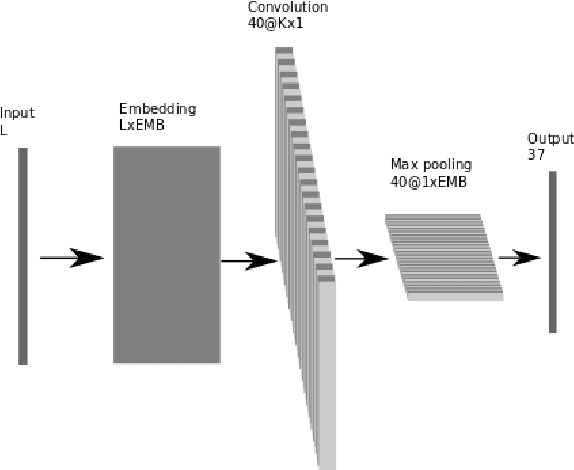

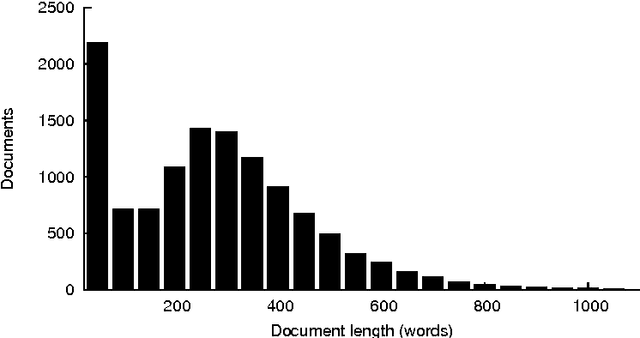
This paper is focused on automatic multi-label document classification of Czech text documents. The current approaches usually use some pre-processing which can have negative impact (loss of information, additional implementation work, etc). Therefore, we would like to omit it and use deep neural networks that learn from simple features. This choice was motivated by their successful usage in many other machine learning fields. Two different networks are compared: the first one is a standard multi-layer perceptron, while the second one is a popular convolutional network. The experiments on a Czech newspaper corpus show that both networks significantly outperform baseline method which uses a rich set of features with maximum entropy classifier. We have also shown that convolutional network gives the best results.