 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICM Ensemble with Novel Betting Functions for Concept Drift
Jun 22, 2024



This study builds upon our previous work by introducing a refined Inductive Conformal Martingale (ICM) approach for addressing Concept Drift (CD). Specifically, we enhance our previously proposed CAUTIOUS betting function to incorporate multiple density estimators for improving detection ability. We also combine this betting function with two base estimators that have not been previously utilized within the ICM framework: the Interpolated Histogram and Nearest Neighbor Density Estimators. We assess these extensions using both a single ICM and an ensemble of ICMs. For the latter, we conduct a comprehensive experimental investigation into the influence of the ensemble size on prediction accuracy and the number of available predictions. Our experimental results on four benchmark datasets demonstrate that the proposed approach surpasses our previous methodology in terms of performance while matching or in many cases exceeding that of three contemporary state-of-the-art techniques.
Vesicoureteral Reflux Detection with Reliable Probabilistic Outputs
Dec 18, 2023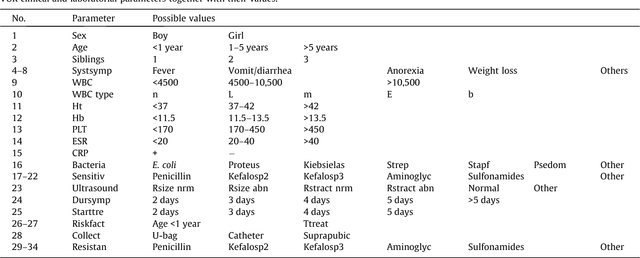

Vesicoureteral Reflux (VUR) is a pediatric disorder in which urine flows backwards from the bladder to the upper urinary tract. Its detection is of great importance as it increases the risk of a Urinary Tract Infection, which can then lead to a kidney infection since bacteria may have direct access to the kidneys. Unfortunately the detection of VUR requires a rather painful medical examination, called voiding cysteourethrogram (VCUG), that exposes the child to radiation. In an effort to avoid the exposure to radiation required by VCUG some recent studies examined the use of machine learning techniques for the detection of VUR based on data that can be obtained without exposing the child to radiation. This work takes one step further by proposing an approach that provides lower and upper bounds for the conditional probability of a given child having VUR. The important property of these bounds is that they are guaranteed (up to statistical fluctuations) to contain well-calibrated probabilities with the only requirement that observations are independent and identically distributed (i.i.d.). Therefore they are much more informative and reliable than the plain yes/no answers provided by other techniques.
Android Malware Detection with Unbiased Confidence Guarantees
Dec 17, 2023The impressive growth of smartphone devices in combination with the rising ubiquity of using mobile platforms for sensitive applications such as Internet banking, have triggered a rapid increase in mobile malware. In recent literature, many studies examine Machine Learning techniques, as the most promising approach for mobile malware detection, without however quantifying the uncertainty involved in their detections. In this paper, we address this problem by proposing a machine learning dynamic analysis approach that provides provably valid confidence guarantees in each malware detection. Moreover the particular guarantees hold for both the malicious and benign classes independently and are unaffected by any bias in the data. The proposed approach is based on a novel machine learning framework, called Conformal Prediction, combined with a random forests classifier. We examine its performance on a large-scale dataset collected by installing 1866 malicious and 4816 benign applications on a real android device. We make this collection of dynamic analysis data available to the research community. The obtained experimental results demonstrate the empirical validity, usefulness and unbiased nature of the outputs produced by the proposed approach.
Reliable Probabilistic Classification with Neural Networks
Dec 15, 2023Venn Prediction (VP) is a new machine learning framework for producing well-calibrated probabilistic predictions. In particular it provides well-calibrated lower and upper bounds for the conditional probability of an example belonging to each possible class of the problem at hand. This paper proposes five VP methods based on Neural Networks (NNs), which is one of the most widely used machine learning techniques. The proposed methods are evaluated experimentally on four benchmark datasets and the obtained results demonstrate the empirical well-calibratedness of their outputs and their superiority over the outputs of the traditional NN classifier.
Reliable Prediction Intervals with Regression Neural Networks
Dec 15, 2023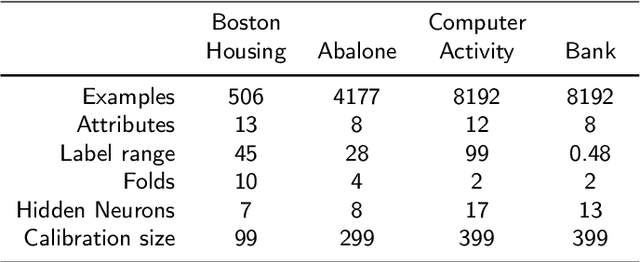

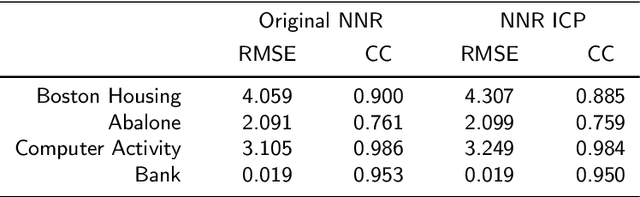

This paper proposes an extension to conventional regression Neural Networks (NNs) for replacing the point predictions they produce with prediction intervals that satisfy a required level of confidence. Our approach follows a novel machine learning framework, called Conformal Prediction (CP), for assigning reliable confidence measures to predictions without assuming anything more than that the data are independent and identically distributed (i.i.d.). We evaluate the proposed method on four benchmark datasets and on the problem of predicting Total Electron Content (TEC), which is an important parameter in trans-ionospheric links; for the latter we use a dataset of more than 60000 TEC measurements collected over a period of 11 years. Our experimental results show that the prediction intervals produced by our method are both well-calibrated and tight enough to be useful in practice.
Well-calibrated Confidence Measures for Multi-label Text Classification with a Large Number of Labels
Dec 14, 2023
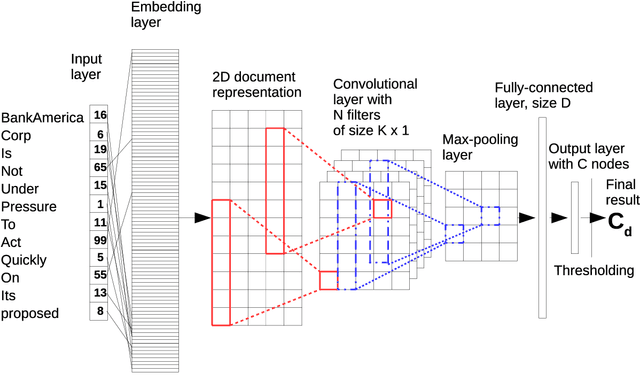
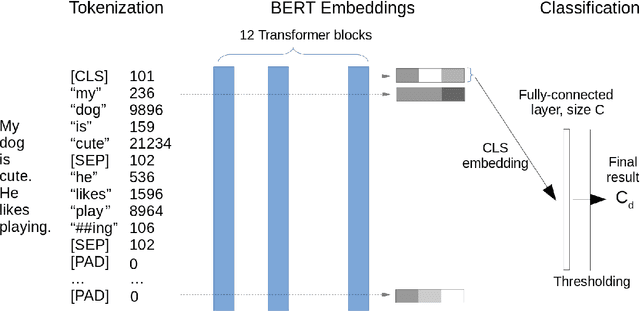
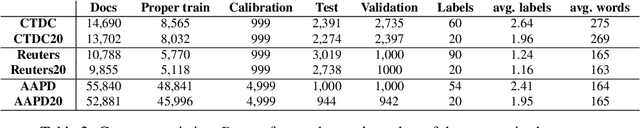
We extend our previous work on Inductive Conformal Prediction (ICP) for multi-label text classification and present a novel approach for addressing the computational inefficiency of the Label Powerset (LP) ICP, arrising when dealing with a high number of unique labels. We present experimental results using the original and the proposed efficient LP-ICP on two English and one Czech language data-sets. Specifically, we apply the LP-ICP on three deep Artificial Neural Network (ANN) classifiers of two types: one based on contextualised (bert) and two on non-contextualised (word2vec) word-embeddings. In the LP-ICP setting we assign nonconformity scores to label-sets from which the corresponding p-values and prediction-sets are determined. Our approach deals with the increased computational burden of LP by eliminating from consideration a significant number of label-sets that will surely have p-values below the specified significance level. This reduces dramatically the computational complexity of the approach while fully respecting the standard CP guarantees. Our experimental results show that the contextualised-based classifier surpasses the non-contextualised-based ones and obtains state-of-the-art performance for all data-sets examined. The good performance of the underlying classifiers is carried on to their ICP counterparts without any significant accuracy loss, but with the added benefits of ICP, i.e. the confidence information encapsulated in the prediction sets. We experimentally demonstrate that the resulting prediction sets can be tight enough to be practically useful even though the set of all possible label-sets contains more than $1e+16$ combinations. Additionally, the empirical error rates of the obtained prediction-sets confirm that our outputs are well-calibrated.
Guaranteed Coverage Prediction Intervals with Gaussian Process Regression
Oct 24, 2023Gaussian Process Regression (GPR) is a popular regression method, which unlike most Machine Learning techniques, provides estimates of uncertainty for its predictions. These uncertainty estimates however, are based on the assumption that the model is well-specified, an assumption that is violated in most practical applications, since the required knowledge is rarely available. As a result, the produced uncertainty estimates can become very misleading; for example the prediction intervals (PIs) produced for the 95\% confidence level may cover much less than 95\% of the true labels. To address this issue, this paper introduces an extension of GPR based on a Machine Learning framework called, Conformal Prediction (CP). This extension guarantees the production of PIs with the required coverage even when the model is completely misspecified. The proposed approach combines the advantages of GPR with the valid coverage guarantee of CP, while the performed experimental results demonstrate its superiority over existing methods.
A Cross-Conformal Predictor for Multi-label Classification
Nov 29, 2022Unlike the typical classification setting where each instance is associated with a single class, in multi-label learning each instance is associated with multiple classes simultaneously. Therefore the learning task in this setting is to predict the subset of classes to which each instance belongs. This work examines the application of a recently developed framework called Conformal Prediction (CP) to the multi-label learning setting. CP complements the predictions of machine learning algorithms with reliable measures of confidence. As a result the proposed approach instead of just predicting the most likely subset of classes for a new unseen instance, also indicates the likelihood of each predicted subset being correct. This additional information is especially valuable in the multi-label setting where the overall uncertainty is extremely high.
* 10 Pages
Regression Conformal Prediction with Nearest Neighbours
Jan 16, 2014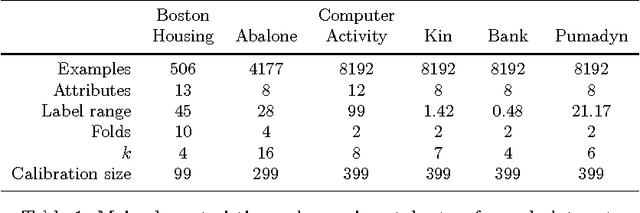
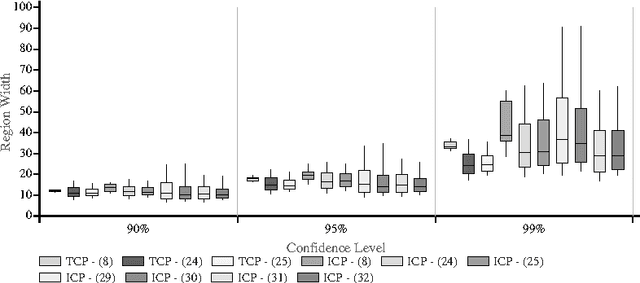
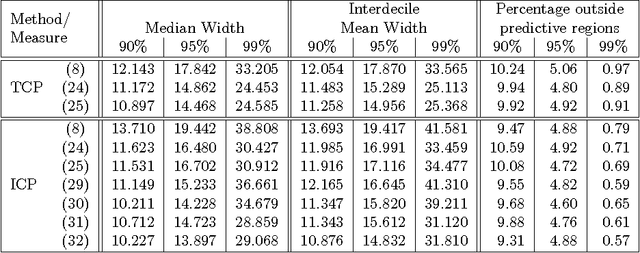
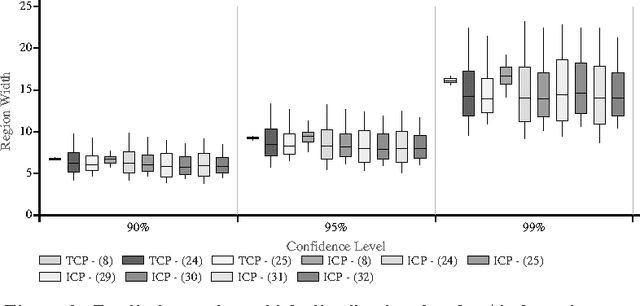
In this paper we apply Conformal Prediction (CP) to the k-Nearest Neighbours Regression (k-NNR) algorithm and propose ways of extending the typical nonconformity measure used for regression so far. Unlike traditional regression methods which produce point predictions, Conformal Predictors output predictive regions that satisfy a given confidence level. The regions produced by any Conformal Predictor are automatically valid, however their tightness and therefore usefulness depends on the nonconformity measure used by each CP. In effect a nonconformity measure evaluates how strange a given example is compared to a set of other examples based on some traditional machine learning algorithm. We define six novel nonconformity measures based on the k-Nearest Neighbours Regression algorithm and develop the corresponding CPs following both the original (transductive) and the inductive CP approaches. A comparison of the predictive regions produced by our measures with those of the typical regression measure suggests that a major improvement in terms of predictive region tightness is achieved by the new measures.
Feature Subset Selection for Software Cost Modelling and Estimation
Oct 03, 2012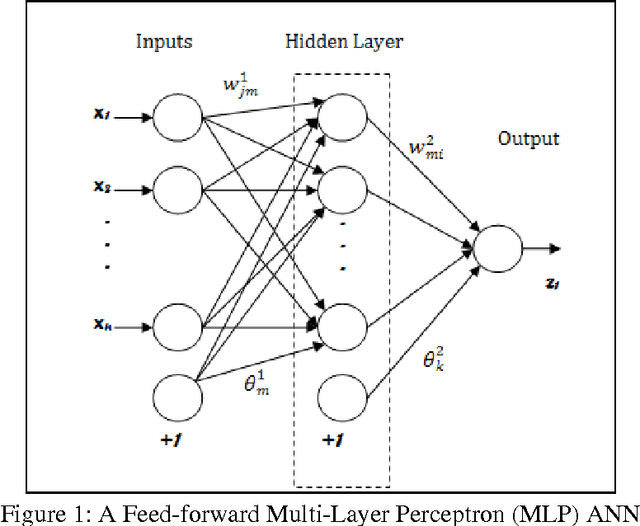
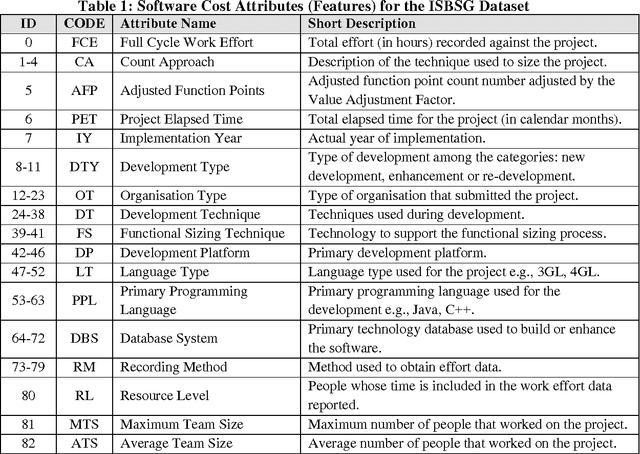
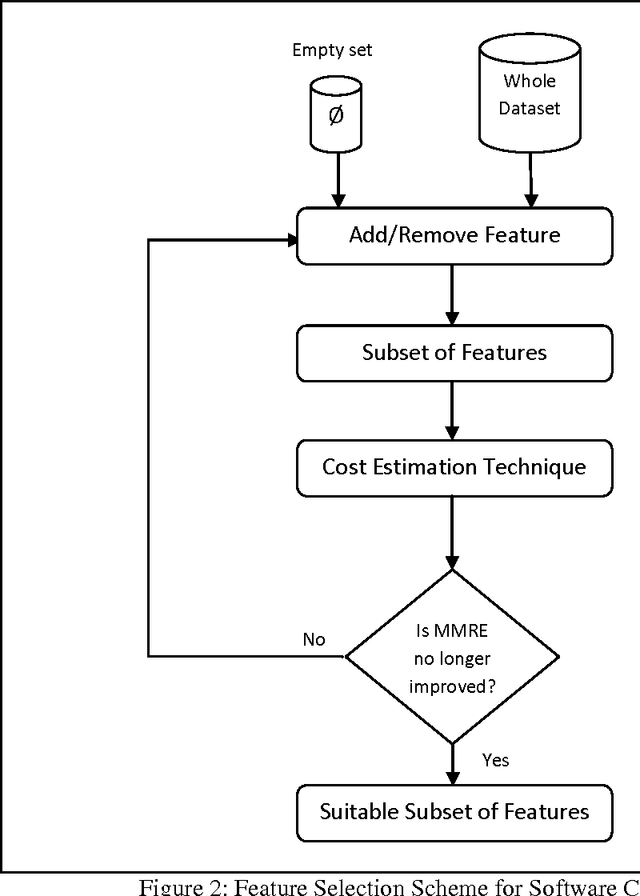
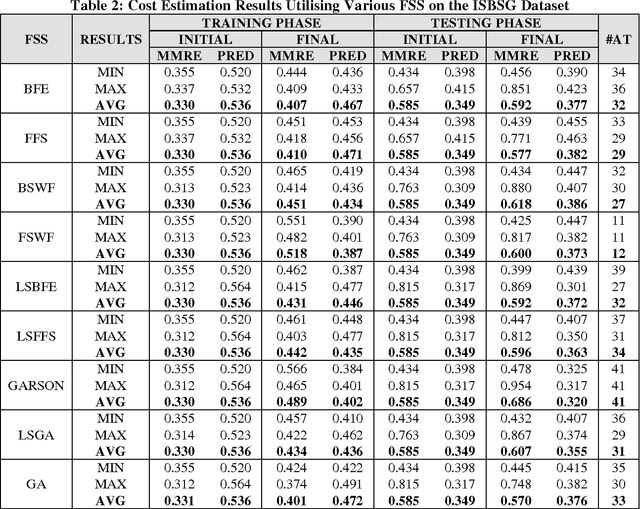
Feature selection has been recently used in the area of software engineering for improving the accuracy and robustness of software cost models. The idea behind selecting the most informative subset of features from a pool of available cost drivers stems from the hypothesis that reducing the dimensionality of datasets will significantly minimise the complexity and time required to reach to an estimation using a particular modelling technique. This work investigates the appropriateness of attributes, obtained from empirical project databases and aims to reduce the cost drivers used while preserving performance. Finding suitable subset selections that may cater improved predictions may be considered as a pre-processing step of a particular technique employed for cost estimation (filter or wrapper) or an internal (embedded) step to minimise the fitting error. This paper compares nine relatively popular feature selection methods and uses the empirical values of selected attributes recorded in the ISBSG and Desharnais datasets to estimate software development effort.