 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Subset Selection for Software Cost Modelling and Estimation
Paper and Code
Oct 03, 2012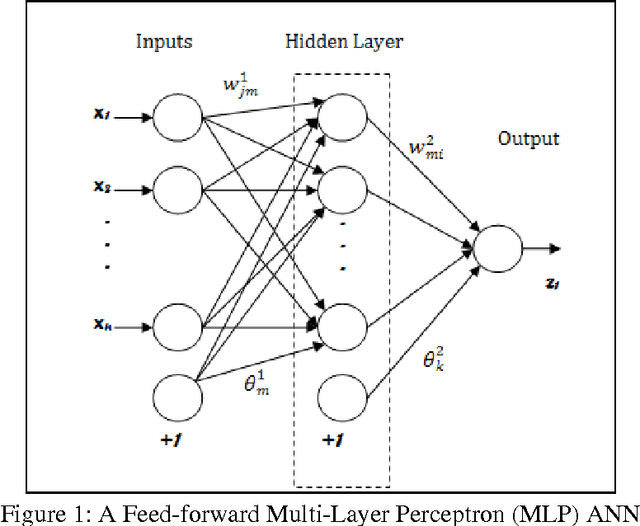
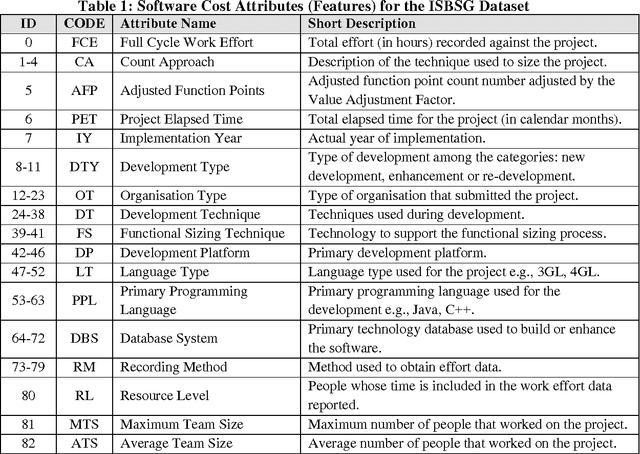
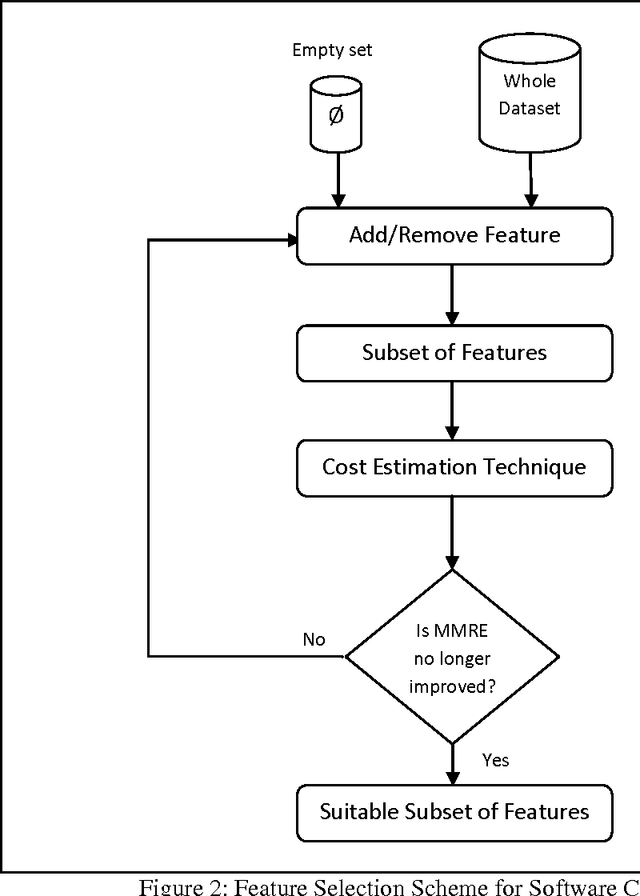
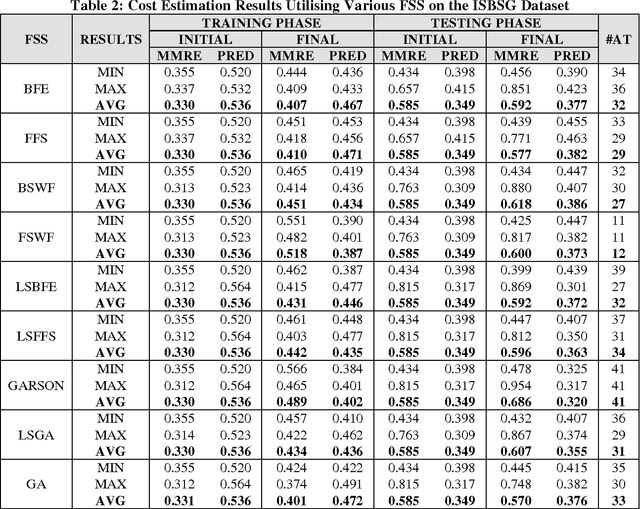
Feature selection has been recently used in the area of software engineering for improving the accuracy and robustness of software cost models. The idea behind selecting the most informative subset of features from a pool of available cost drivers stems from the hypothesis that reducing the dimensionality of datasets will significantly minimise the complexity and time required to reach to an estimation using a particular modelling technique. This work investigates the appropriateness of attributes, obtained from empirical project databases and aims to reduce the cost drivers used while preserving performance. Finding suitable subset selections that may cater improved predictions may be considered as a pre-processing step of a particular technique employed for cost estimation (filter or wrapper) or an internal (embedded) step to minimise the fitting error. This paper compares nine relatively popular feature selection methods and uses the empirical values of selected attributes recorded in the ISBSG and Desharnais datasets to estimate software development effort.