 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Latent Variable Networks for Session-Based Recommendation
Jun 13, 2017

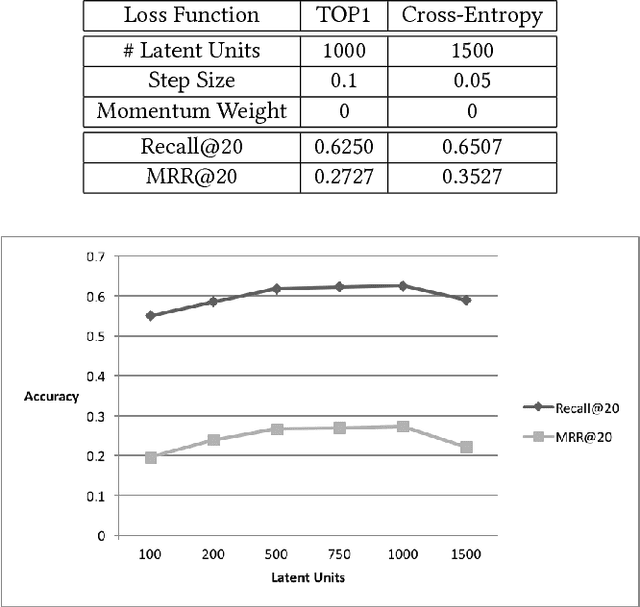

In this work, we attempt to ameliorate the impact of data sparsity in the context of session-based recommendation. Specifically, we seek to devise a machine learning mechanism capable of extracting subtle and complex underlying temporal dynamics in the observed session data, so as to inform the recommendation algorithm. To this end, we improve upon systems that utilize deep learning techniques with recurrently connected units; we do so by adopting concepts from the field of Bayesian statistics, namely variational inference. Our proposed approach consists in treating the network recurrent units as stochastic latent variables with a prior distribution imposed over them. On this basis, we proceed to infer corresponding posteriors; these can be used for prediction and recommendation generation, in a way that accounts for the uncertainty in the available sparse training data. To allow for our approach to easily scale to large real-world datasets, we perform inference under an approximate amortized variational inference (AVI) setup, whereby the learned posteriors are parameterized via (conventional) neural networks. We perform an extensive experimental evaluation of our approach using challenging benchmark datasets, and illustrate its superiority over existing state-of-the-art techniques.
Feature Subset Selection for Software Cost Modelling and Estimation
Oct 03, 2012
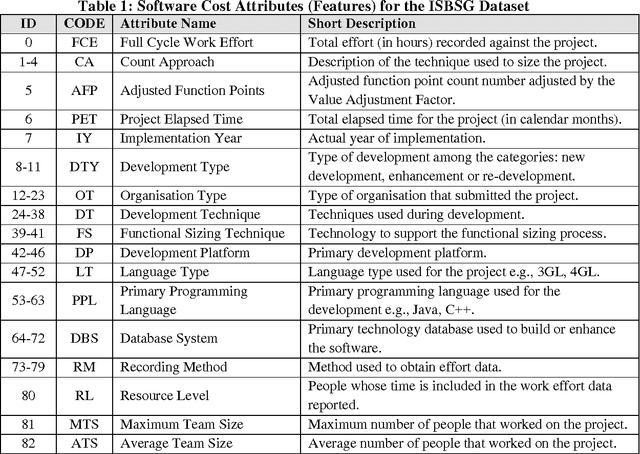
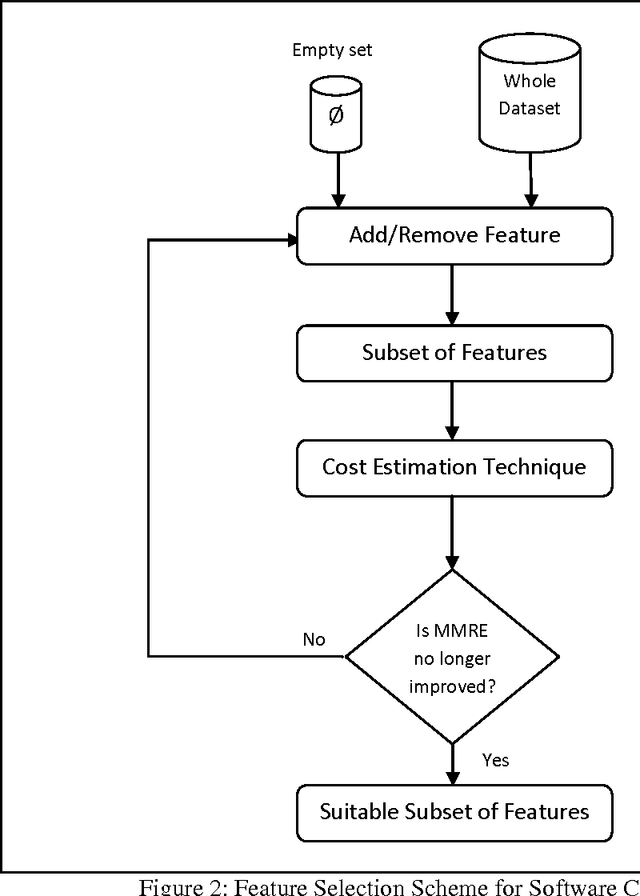
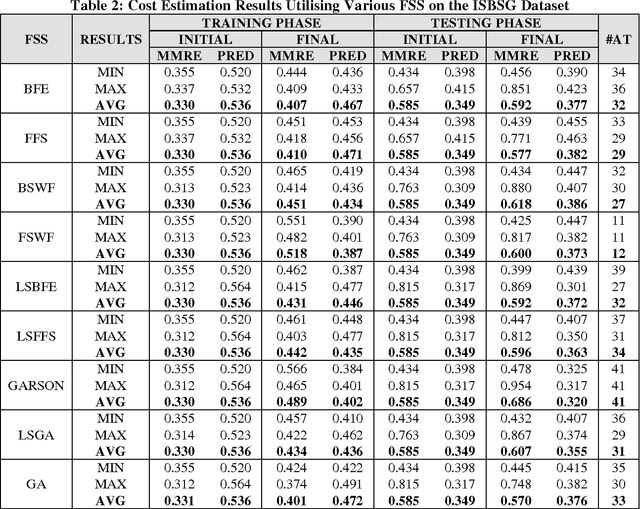
Feature selection has been recently used in the area of software engineering for improving the accuracy and robustness of software cost models. The idea behind selecting the most informative subset of features from a pool of available cost drivers stems from the hypothesis that reducing the dimensionality of datasets will significantly minimise the complexity and time required to reach to an estimation using a particular modelling technique. This work investigates the appropriateness of attributes, obtained from empirical project databases and aims to reduce the cost drivers used while preserving performance. Finding suitable subset selections that may cater improved predictions may be considered as a pre-processing step of a particular technique employed for cost estimation (filter or wrapper) or an internal (embedded) step to minimise the fitting error. This paper compares nine relatively popular feature selection methods and uses the empirical values of selected attributes recorded in the ISBSG and Desharnais datasets to estimate software development effort.
Software Effort Estimation with Ridge Regression and Evolutionary Attribute Selection
Dec 28, 2010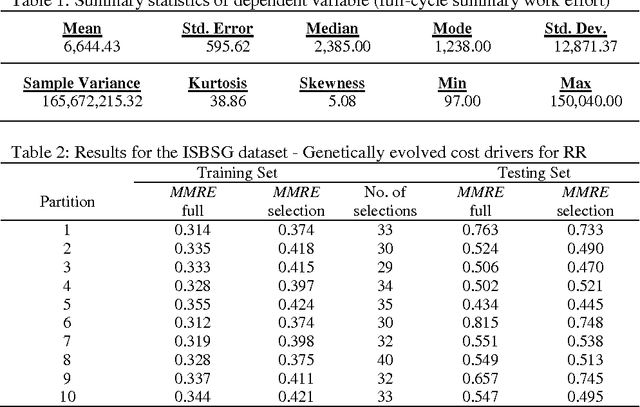
Software cost estimation is one of the prerequisite managerial activities carried out at the software development initiation stages and also repeated throughout the whole software life-cycle so that amendments to the total cost are made. In software cost estimation typically, a selection of project attributes is employed to produce effort estimations of the expected human resources to deliver a software product. However, choosing the appropriate project cost drivers in each case requires a lot of experience and knowledge on behalf of the project manager which can only be obtained through years of software engineering practice. A number of studies indicate that popular methods applied in the literature for software cost estimation, such as linear regression, are not robust enough and do not yield accurate predictions. Recently the dual variables Ridge Regression (RR) technique has been used for effort estimation yielding promising results. In this work we show that results may be further improved if an AI method is used to automatically select appropriate project cost drivers (inputs) for the technique. We propose a hybrid approach combining RR with a Genetic Algorithm, the latter evolving the subset of attributes for approximating effort more accurately. The proposed hybrid cost model has been applied on a widely known high-dimensional dataset of software project samples and the results obtained show that accuracy may be increased if redundant attributes are eliminated.