 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Cross-lingual Aspect-Based Sentiment Analysis with LLMs and Constrained Decoding for Sequence-to-Sequence Models
Aug 14, 2025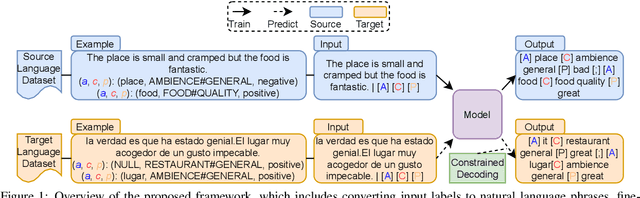


Aspect-based sentiment analysis (ABSA) has made significant strides, yet challenges remain for low-resource languages due to the predominant focus on English. Current cross-lingual ABSA studies often centre on simpler tasks and rely heavily on external translation tools. In this paper, we present a novel sequence-to-sequence method for compound ABSA tasks that eliminates the need for such tools. Our approach, which uses constrained decoding, improves cross-lingual ABSA performance by up to 10\%. This method broadens the scope of cross-lingual ABSA, enabling it to handle more complex tasks and providing a practical, efficient alternative to translation-dependent techniques. Furthermore, we compare our approach with large language models (LLMs) and show that while fine-tuned multilingual LLMs can achieve comparable results, English-centric LLMs struggle with these tasks.
Improving Generative Cross-lingual Aspect-Based Sentiment Analysis with Constrained Decoding
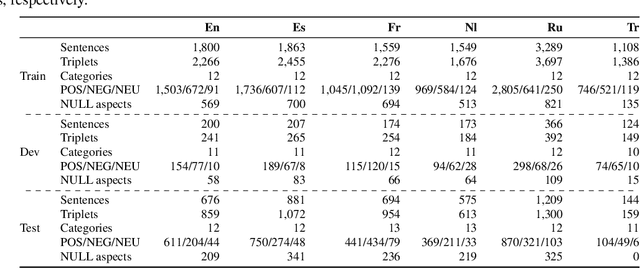
Aug 14, 2025While aspect-based sentiment analysis (ABSA) has made substantial progress, challenges remain for low-resource languages, which are often overlooked in favour of English. Current cross-lingual ABSA approaches focus on limited, less complex tasks and often rely on external translation tools. This paper introduces a novel approach using constrained decoding with sequence-to-sequence models, eliminating the need for unreliable translation tools and improving cross-lingual performance by 5\% on average for the most complex task. The proposed method also supports multi-tasking, which enables solving multiple ABSA tasks with a single model, with constrained decoding boosting results by more than 10\%. We evaluate our approach across seven languages and six ABSA tasks, surpassing state-of-the-art methods and setting new benchmarks for previously unexplored tasks. Additionally, we assess large language models (LLMs) in zero-shot, few-shot, and fine-tuning scenarios. While LLMs perform poorly in zero-shot and few-shot settings, fine-tuning achieves competitive results compared to smaller multilingual models, albeit at the cost of longer training and inference times. We provide practical recommendations for real-world applications, enhancing the understanding of cross-lingual ABSA methodologies. This study offers valuable insights into the strengths and limitations of cross-lingual ABSA approaches, advancing the state-of-the-art in this challenging research domain.
Large Language Models for Summarizing Czech Historical Documents and Beyond
Aug 14, 2025Text summarization is the task of shortening a larger body of text into a concise version while retaining its essential meaning and key information. While summarization has been significantly explored in English and other high-resource languages, Czech text summarization, particularly for historical documents, remains underexplored due to linguistic complexities and a scarcity of annotated datasets. Large language models such as Mistral and mT5 have demonstrated excellent results on many natural language processing tasks and languages. Therefore, we employ these models for Czech summarization, resulting in two key contributions: (1) achieving new state-of-the-art results on the modern Czech summarization dataset SumeCzech using these advanced models, and (2) introducing a novel dataset called Posel od \v{C}erchova for summarization of historical Czech documents with baseline results. Together, these contributions provide a great potential for advancing Czech text summarization and open new avenues for research in Czech historical text processing.
LLaMA-Based Models for Aspect-Based Sentiment Analysis
Aug 12, 2025While large language models (LLMs) show promise for various tasks, their performance in compound aspect-based sentiment analysis (ABSA) tasks lags behind fine-tuned models. However, the potential of LLMs fine-tuned for ABSA remains unexplored. This paper examines the capabilities of open-source LLMs fine-tuned for ABSA, focusing on LLaMA-based models. We evaluate the performance across four tasks and eight English datasets, finding that the fine-tuned Orca~2 model surpasses state-of-the-art results in all tasks. However, all models struggle in zero-shot and few-shot scenarios compared to fully fine-tuned ones. Additionally, we conduct error analysis to identify challenges faced by fine-tuned models.
UWB at WASSA-2024 Shared Task 2: Cross-lingual Emotion Detection
Aug 12, 2025This paper presents our system built for the WASSA-2024 Cross-lingual Emotion Detection Shared Task. The task consists of two subtasks: first, to assess an emotion label from six possible classes for a given tweet in one of five languages, and second, to predict words triggering the detected emotions in binary and numerical formats. Our proposed approach revolves around fine-tuning quantized large language models, specifically Orca~2, with low-rank adapters (LoRA) and multilingual Transformer-based models, such as XLM-R and mT5. We enhance performance through machine translation for both subtasks and trigger word switching for the second subtask. The system achieves excellent performance, ranking 1st in numerical trigger words detection, 3rd in binary trigger words detection, and 7th in emotion detection.
Prompt-Based Approach for Czech Sentiment Analysis
Aug 12, 2025This paper introduces the first prompt-based methods for aspect-based sentiment analysis and sentiment classification in Czech. We employ the sequence-to-sequence models to solve the aspect-based tasks simultaneously and demonstrate the superiority of our prompt-based approach over traditional fine-tuning. In addition, we conduct zero-shot and few-shot learning experiments for sentiment classification and show that prompting yields significantly better results with limited training examples compared to traditional fine-tuning. We also demonstrate that pre-training on data from the target domain can lead to significant improvements in a zero-shot scenario.
Large Language Models for Czech Aspect-Based Sentiment Analysis
Aug 11, 2025Aspect-based sentiment analysis (ABSA) is a fine-grained sentiment analysis task that aims to identify sentiment toward specific aspects of an entity. While large language models (LLMs) have shown strong performance in various natural language processing (NLP) tasks, their capabilities for Czech ABSA remain largely unexplored. In this work, we conduct a comprehensive evaluation of 19 LLMs of varying sizes and architectures on Czech ABSA, comparing their performance in zero-shot, few-shot, and fine-tuning scenarios. Our results show that small domain-specific models fine-tuned for ABSA outperform general-purpose LLMs in zero-shot and few-shot settings, while fine-tuned LLMs achieve state-of-the-art results. We analyze how factors such as multilingualism, model size, and recency influence performance and present an error analysis highlighting key challenges, particularly in aspect term prediction. Our findings provide insights into the suitability of LLMs for Czech ABSA and offer guidance for future research in this area.
Few-shot Cross-lingual Aspect-Based Sentiment Analysis with Sequence-to-Sequence Models
Aug 11, 2025
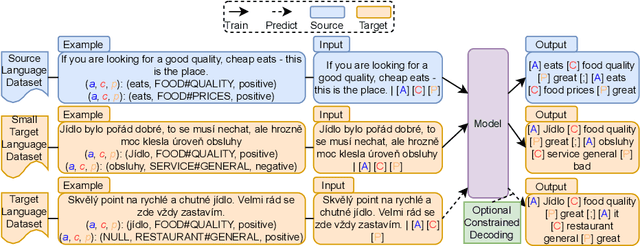
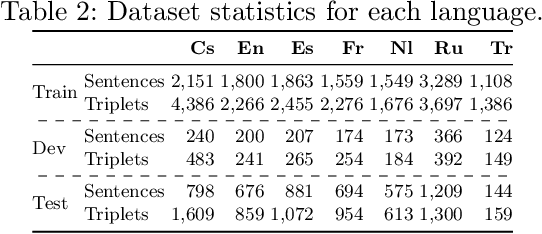
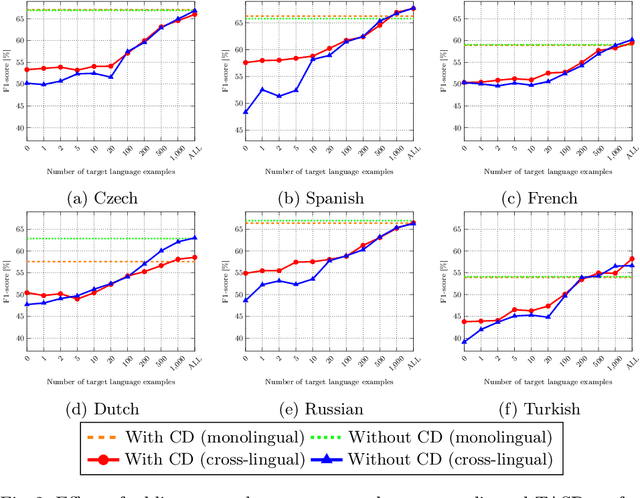
Aspect-based sentiment analysis (ABSA) has received substantial attention in English, yet challenges remain for low-resource languages due to the scarcity of labelled data. Current cross-lingual ABSA approaches often rely on external translation tools and overlook the potential benefits of incorporating a small number of target language examples into training. In this paper, we evaluate the effect of adding few-shot target language examples to the training set across four ABSA tasks, six target languages, and two sequence-to-sequence models. We show that adding as few as ten target language examples significantly improves performance over zero-shot settings and achieves a similar effect to constrained decoding in reducing prediction errors. Furthermore, we demonstrate that combining 1,000 target language examples with English data can even surpass monolingual baselines. These findings offer practical insights for improving cross-lingual ABSA in low-resource and domain-specific settings, as obtaining ten high-quality annotated examples is both feasible and highly effective.
Czech Dataset for Complex Aspect-Based Sentiment Analysis Tasks
Aug 11, 2025In this paper, we introduce a novel Czech dataset for aspect-based sentiment analysis (ABSA), which consists of 3.1K manually annotated reviews from the restaurant domain. The dataset is built upon the older Czech dataset, which contained only separate labels for the basic ABSA tasks such as aspect term extraction or aspect polarity detection. Unlike its predecessor, our new dataset is specifically designed for more complex tasks, e.g. target-aspect-category detection. These advanced tasks require a unified annotation format, seamlessly linking sentiment elements (labels) together. Our dataset follows the format of the well-known SemEval-2016 datasets. This design choice allows effortless application and evaluation in cross-lingual scenarios, ultimately fostering cross-language comparisons with equivalent counterpart datasets in other languages. The annotation process engaged two trained annotators, yielding an impressive inter-annotator agreement rate of approximately 90%. Additionally, we provide 24M reviews without annotations suitable for unsupervised learning. We present robust monolingual baseline results achieved with various Transformer-based models and insightful error analysis to supplement our contributions. Our code and dataset are freely available for non-commercial research purposes.
Linear Transformations for Cross-lingual Sentiment Analysis
Sep 15, 2022This paper deals with cross-lingual sentiment analysis in Czech, English and French languages. We perform zero-shot cross-lingual classification using five linear transformations combined with LSTM and CNN based classifiers. We compare the performance of the individual transformations, and in addition, we confront the transformation-based approach with existing state-of-the-art BERT-like models. We show that the pre-trained embeddings from the target domain are crucial to improving the cross-lingual classification results, unlike in the monolingual classification, where the effect is not so distinctive.