 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Networks for Czech Multi-label Document Classification
Paper and Code
Jan 18, 2017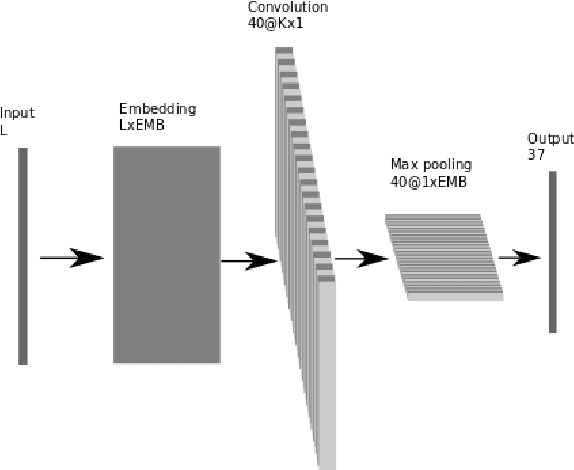

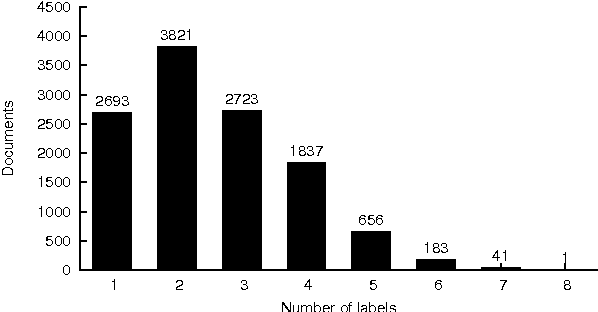
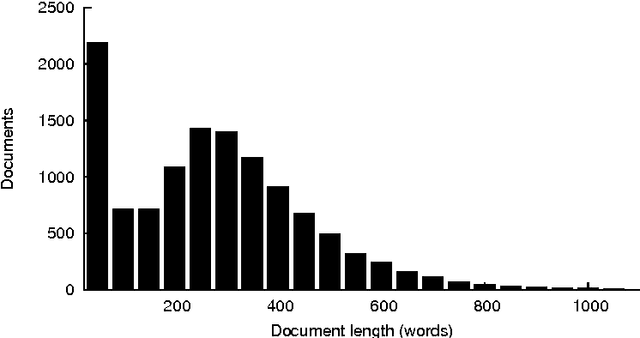
This paper is focused on automatic multi-label document classification of Czech text documents. The current approaches usually use some pre-processing which can have negative impact (loss of information, additional implementation work, etc). Therefore, we would like to omit it and use deep neural networks that learn from simple features. This choice was motivated by their successful usage in many other machine learning fields. Two different networks are compared: the first one is a standard multi-layer perceptron, while the second one is a popular convolutional network. The experiments on a Czech newspaper corpus show that both networks significantly outperform baseline method which uses a rich set of features with maximum entropy classifier. We have also shown that convolutional network gives the best results.