 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-ranking for Writer Identification and Writer Retrieval
Paper and Code
Jul 14, 2020
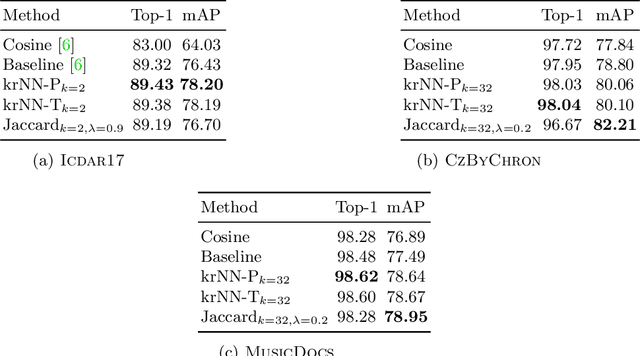

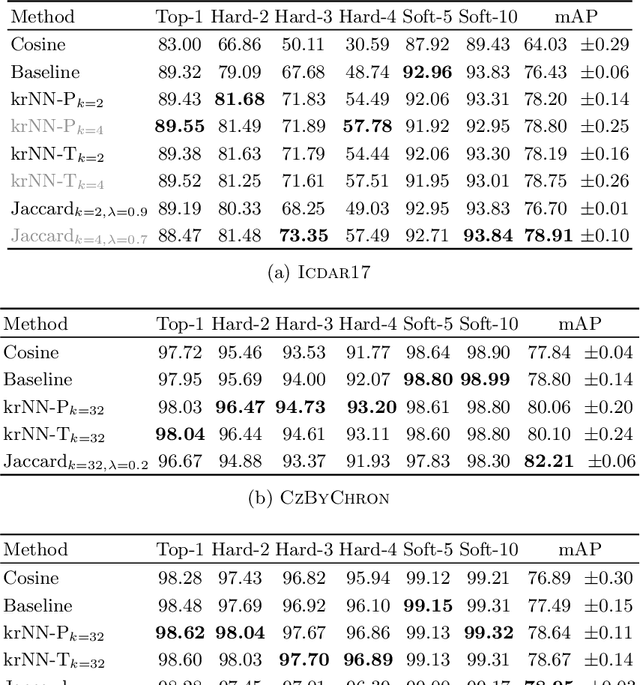
Automatic writer identification is a common problem in document analysis. State-of-the-art methods typically focus on the feature extraction step with traditional or deep-learning-based techniques. In retrieval problems, re-ranking is a commonly used technique to improve the results. Re-ranking refines an initial ranking result by using the knowledge contained in the ranked result, e. g., by exploiting nearest neighbor relations. To the best of our knowledge, re-ranking has not been used for writer identification/retrieval. A possible reason might be that publicly available benchmark datasets contain only few samples per writer which makes a re-ranking less promising. We show that a re-ranking step based on k-reciprocal nearest neighbor relationships is advantageous for writer identification, even if only a few samples per writer are available. We use these reciprocal relationships in two ways: encode them into new vectors, as originally proposed, or integrate them in terms of query-expansion. We show that both techniques outperform the baseline results in terms of mAP on three writer identification datasets.