 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRACAS: A FRench Annotated Corpus of Attribution relations in newS
Sep 19, 2023



Quotation extraction is a widely useful task both from a sociological and from a Natural Language Processing perspective. However, very little data is available to study this task in languages other than English. In this paper, we present a manually annotated corpus of 1676 newswire texts in French for quotation extraction and source attribution. We first describe the composition of our corpus and the choices that were made in selecting the data. We then detail the annotation guidelines and annotation process, as well as a few statistics about the final corpus and the obtained balance between quote types (direct, indirect and mixed, which are particularly challenging). We end by detailing our inter-annotator agreement between the 8 annotators who worked on manual labelling, which is substantially high for such a difficult linguistic phenomenon.
GenderedNews: Une approche computationnelle des écarts de représentation des genres dans la presse française
Mar 07, 2022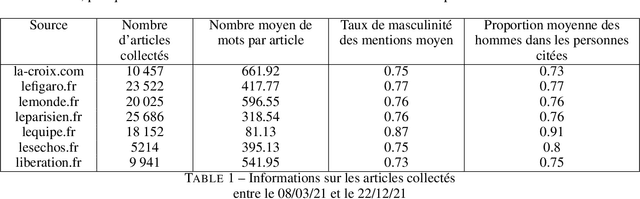


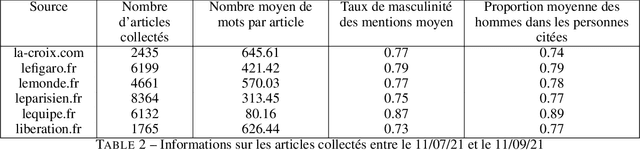
In this article, we present {\it GenderedNews} (\url{https://gendered-news.imag.fr}), an online dashboard which gives weekly measures of gender imbalance in French online press. We use Natural Language Processing (NLP) methods to quantify gender inequalities in the media, in the wake of global projects like the Global Media Monitoring Project. Such projects are instrumental in highlighting gender imbalance in the media and its very slow evolution. However, their generalisation is limited by their sampling and cost in terms of time, data and staff. Automation allows us to offer complementary measures to quantify inequalities in gender representation. We understand representation as the presence and distribution of men and women mentioned and quoted in the news -- as opposed to representation as stereotypification. In this paper, we first review different means adopted by previous studies on gender inequality in the media : qualitative content analysis, quantitative content analysis and computational methods. We then detail the methods adopted by {\it GenderedNews} and the two metrics implemented: the masculinity rate of mentions and the proportion of men quoted in online news. We describe the data collected daily (seven main titles of French online news media) and the methodology behind our metrics, as well as a few visualisations. We finally propose to illustrate possible analysis of our data by conducting an in-depth observation of a sample of two months of our database.