 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT as speechwriter for the French presidents
Nov 27, 2024



Generative AI proposes several large language models (LLMs) to automatically generate a message in response to users' requests. Such scientific breakthroughs promote new writing assistants but with some fears. The main focus of this study is to analyze the written style of one LLM called ChatGPT by comparing its generated messages with those of the recent French presidents. To achieve this, we compare end-of-the-year addresses written by Chirac, Sarkozy, Hollande, and Macron with those automatically produced by ChatGPT. We found that ChatGPT tends to overuse nouns, possessive determiners, and numbers. On the other hand, the generated speeches employ less verbs, pronouns, and adverbs and include, in mean, too standardized sentences. Considering some words, one can observe that ChatGPT tends to overuse "to must" (devoir), "to continue" or the lemma "we" (nous). Moreover, GPT underuses the auxiliary verb "to be" (^etre), or the modal verbs "to will" (vouloir) or "to have to" (falloir). In addition, when a short text is provided as example to ChatGPT, the machine can generate a short message with a style closed to the original wording. Finally, we reveal that ChatGPT style exposes distinct features compared to real presidential speeches.
Detection of tortured phrases in scientific literature
Feb 02, 2024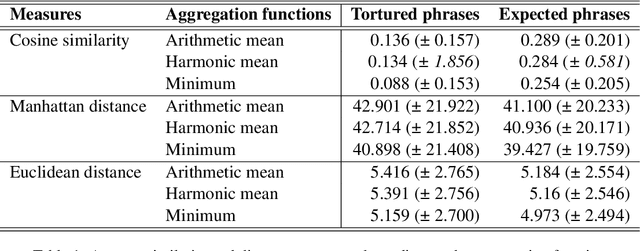
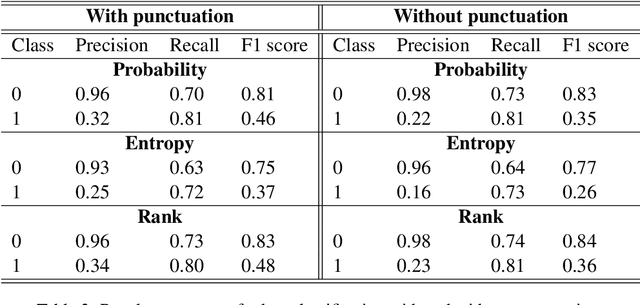
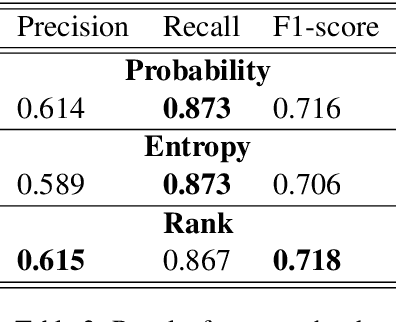
This paper presents various automatic detection methods to extract so called tortured phrases from scientific papers. These tortured phrases, e.g. flag to clamor instead of signal to noise, are the results of paraphrasing tools used to escape plagiarism detection. We built a dataset and evaluated several strategies to flag previously undocumented tortured phrases. The proposed and tested methods are based on language models and either on embeddings similarities or on predictions of masked token. We found that an approach using token prediction and that propagates the scores to the chunk level gives the best results. With a recall value of .87 and a precision value of .61, it could retrieve new tortured phrases to be submitted to domain experts for validation.
NanoNER: Named Entity Recognition for nanobiology using experts' knowledge and distant supervision
Jan 30, 2024Here we present the training and evaluation of NanoNER, a Named Entity Recognition (NER) model for Nanobiology. NER consists in the identification of specific entities in spans of unstructured texts and is often a primary task in Natural Language Processing (NLP) and Information Extraction. The aim of our model is to recognise entities previously identified by domain experts as constituting the essential knowledge of the domain. Relying on ontologies, which provide us with a domain vocabulary and taxonomy, we implemented an iterative process enabling experts to determine the entities relevant to the domain at hand. We then delve into the potential of distant supervision learning in NER, supporting how this method can increase the quantity of annotated data with minimal additional manpower. On our full corpus of 728 full-text nanobiology articles, containing more than 120k entity occurrences, NanoNER obtained a F1-score of 0.98 on the recognition of previously known entities. Our model also demonstrated its ability to discover new entities in the text, with precision scores ranging from 0.77 to 0.81. Ablation experiments further confirmed this and allowed us to assess the dependency of our approach on the external resources. It highlighted the dependency of the approach to the resource, while also confirming its ability to rediscover up to 30% of the ablated terms. This paper details the methodology employed, experimental design, and key findings, providing valuable insights and directions for future related researches on NER in specialized domain. Furthermore, since our approach require minimal manpower , we believe that it can be generalized to other specialized fields.
Investigating the detection of Tortured Phrases in Scientific Literature
Oct 24, 2022


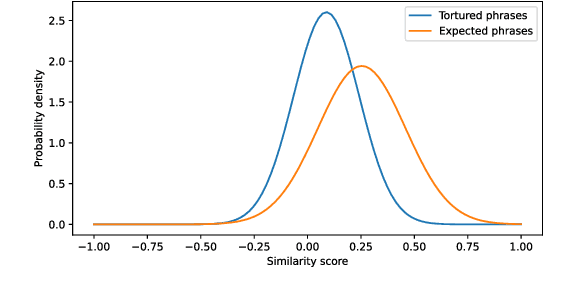
With the help of online tools, unscrupulous authors can today generate a pseudo-scientific article and attempt to publish it. Some of these tools work by replacing or paraphrasing existing texts to produce new content, but they have a tendency to generate nonsensical expressions. A recent study introduced the concept of 'tortured phrase', an unexpected odd phrase that appears instead of the fixed expression. E.g. counterfeit consciousness instead of artificial intelligence. The present study aims at investigating how tortured phrases, that are not yet listed, can be detected automatically. We conducted several experiments, including non-neural binary classification, neural binary classification and cosine similarity comparison of the phrase tokens, yielding noticeable results.
The 'Problematic Paper Screener' automatically selects suspect publications for post-publication (re)assessment
Oct 07, 2022Post publication assessment remains necessary to check erroneous or fraudulent scientific publications. We present an online platform, the 'Problematic Paper Screener' (https://www.irit.fr/~Guillaume.Cabanac/problematic-paper-screener) that leverages both automatic machine detection and human assessment to identify and flag already published problematic articles. We provide a new effective tool to curate the scientific literature.
Tortured phrases: A dubious writing style emerging in science. Evidence of critical issues affecting established journals
Jul 12, 2021

Probabilistic text generators have been used to produce fake scientific papers for more than a decade. Such nonsensical papers are easily detected by both human and machine. Now more complex AI-powered generation techniques produce texts indistinguishable from that of humans and the generation of scientific texts from a few keywords has been documented. Our study introduces the concept of tortured phrases: unexpected weird phrases in lieu of established ones, such as 'counterfeit consciousness' instead of 'artificial intelligence.' We combed the literature for tortured phrases and study one reputable journal where these concentrated en masse. Hypothesising the use of advanced language models we ran a detector on the abstracts of recent articles of this journal and on several control sets. The pairwise comparisons reveal a concentration of abstracts flagged as 'synthetic' in the journal. We also highlight irregularities in its operation, such as abrupt changes in editorial timelines. We substantiate our call for investigation by analysing several individual dubious articles, stressing questionable features: tortured writing style, citation of non-existent literature, and unacknowledged image reuse. Surprisingly, some websites offer to rewrite texts for free, generating gobbledegook full of tortured phrases. We believe some authors used rewritten texts to pad their manuscripts. We wish to raise the awareness on publications containing such questionable AI-generated or rewritten texts that passed (poor) peer review. Deception with synthetic texts threatens the integrity of the scientific literature.
Semi-Supervised Neural Text Generation by Joint Learning of Natural Language Generation and Natural Language Understanding Models
Sep 29, 2019
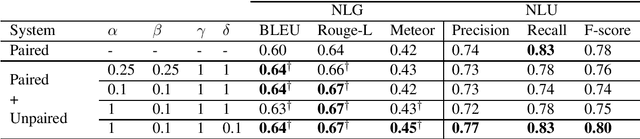
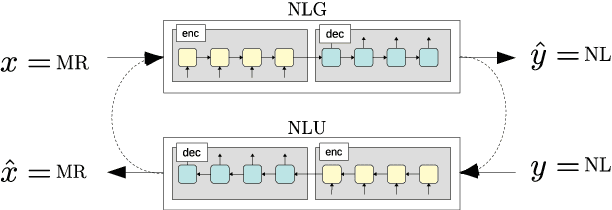
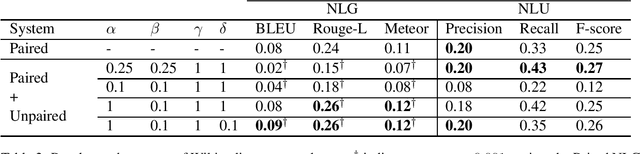
In Natural Language Generation (NLG), End-to-End (E2E) systems trained through deep learning have recently gained a strong interest. Such deep models need a large amount of carefully annotated data to reach satisfactory performance. However, acquiring such datasets for every new NLG application is a tedious and time-consuming task. In this paper, we propose a semi-supervised deep learning scheme that can learn from non-annotated data and annotated data when available. It uses an NLG and a Natural Language Understanding (NLU) sequence-to-sequence models which are learned jointly to compensate for the lack of annotation. Experiments on two benchmark datasets show that, with limited amount of annotated data, the method can achieve very competitive results while not using any pre-processing or re-scoring tricks. These findings open the way to the exploitation of non-annotated datasets which is the current bottleneck for the E2E NLG system development to new applications.