 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Augmented Generator for Abstractive Summarization
Paper and Code
Aug 19, 2019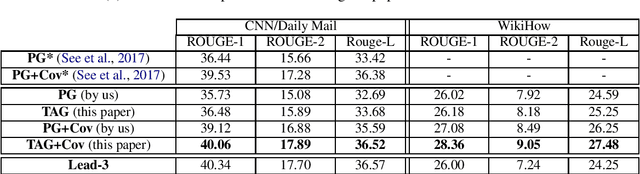
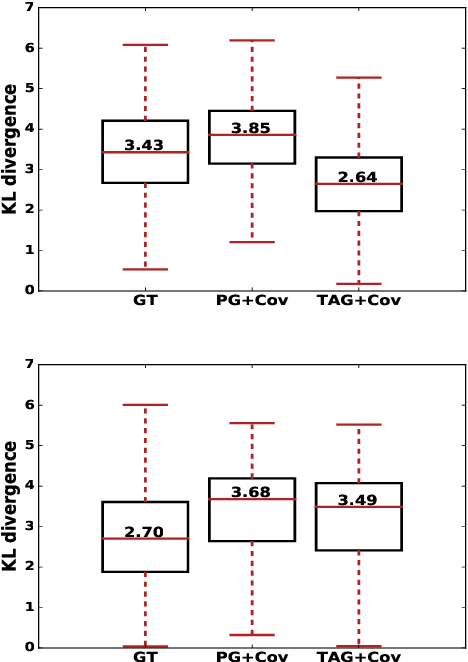


Steady progress has been made in abstractive summarization with attention-based sequence-to-sequence learning models. In this paper, we propose a new decoder where the output summary is generated by conditioning on both the input text and the latent topics of the document. The latent topics, identified by a topic model such as LDA, reveals more global semantic information that can be used to bias the decoder to generate words. In particular, they enable the decoder to have access to additional word co-occurrence statistics captured at document corpus level. We empirically validate the advantage of the proposed approach on both the CNN/Daily Mail and the WikiHow datasets. Concretely, we attain strongly improved ROUGE scores when compared to state-of-the-art models.