 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingxiDiagBench: A Multi-Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis
Feb 11, 2026Mental disorders are highly prevalent worldwide, but the shortage of psychiatrists and the inherent subjectivity of interview-based diagnosis create substantial barriers to timely and consistent mental-health assessment. Progress in AI-assisted psychiatric diagnosis is constrained by the absence of benchmarks that simultaneously provide realistic patient simulation, clinician-verified diagnostic labels, and support for dynamic multi-turn consultation. We present LingxiDiagBench, a large-scale multi-agent benchmark that evaluates LLMs on both static diagnostic inference and dynamic multi-turn psychiatric consultation in Chinese. At its core is LingxiDiag-16K, a dataset of 16,000 EMR-aligned synthetic consultation dialogues designed to reproduce real clinical demographic and diagnostic distributions across 12 ICD-10 psychiatric categories. Through extensive experiments across state-of-the-art LLMs, we establish key findings: (1) although LLMs achieve high accuracy on binary depression--anxiety classification (up to 92.3%), performance deteriorates substantially for depression--anxiety comorbidity recognition (43.0%) and 12-way differential diagnosis (28.5%); (2) dynamic consultation often underperforms static evaluation, indicating that ineffective information-gathering strategies significantly impair downstream diagnostic reasoning; (3) consultation quality assessed by LLM-as-a-Judge shows only moderate correlation with diagnostic accuracy, suggesting that well-structured questioning alone does not ensure correct diagnostic decisions. We release LingxiDiag-16K and the full evaluation framework to support reproducible research at https://github.com/Lingxi-mental-health/LingxiDiagBench.
BLEURT Has Universal Translations: An Analysis of Automatic Metrics by Minimum Risk Training
Jul 10, 2023

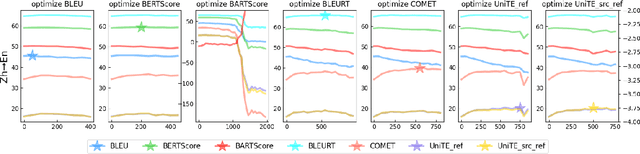
Automatic metrics play a crucial role in machine translation. Despite the widespread use of n-gram-based metrics, there has been a recent surge in the development of pre-trained model-based metrics that focus on measuring sentence semantics. However, these neural metrics, while achieving higher correlations with human evaluations, are often considered to be black boxes with potential biases that are difficult to detect. In this study, we systematically analyze and compare various mainstream and cutting-edge automatic metrics from the perspective of their guidance for training machine translation systems. Through Minimum Risk Training (MRT), we find that certain metrics exhibit robustness defects, such as the presence of universal adversarial translations in BLEURT and BARTScore. In-depth analysis suggests two main causes of these robustness deficits: distribution biases in the training datasets, and the tendency of the metric paradigm. By incorporating token-level constraints, we enhance the robustness of evaluation metrics, which in turn leads to an improvement in the performance of machine translation systems. Codes are available at \url{https://github.com/powerpuffpomelo/fairseq_mrt}.
Amortized Inference of Variational Bounds for Learning Noisy-OR
Jun 06, 2019

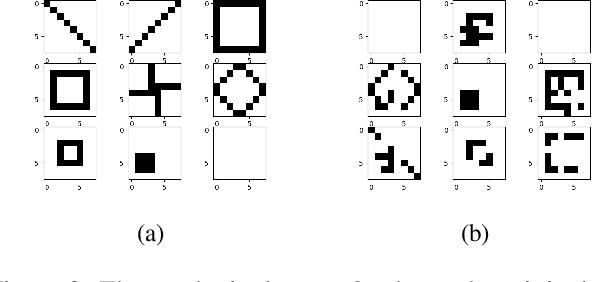
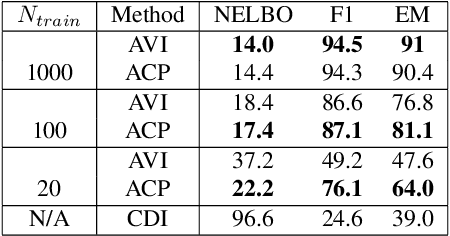
Classical approaches for approximate inference depend on cleverly designed variational distributions and bounds. Modern approaches employ amortized variational inference, which uses a neural network to approximate any posterior without leveraging the structures of the generative models. In this paper, we propose Amortized Conjugate Posterior (ACP), a hybrid approach taking advantages of both types of approaches. Specifically, we use the classical methods to derive specific forms of posterior distributions and then learn the variational parameters using amortized inference. We study the effectiveness of the proposed approach on the Noisy-OR model and compare to both the classical and the modern approaches for approximate inference and parameter learning. Our results show that ACP outperforms other methods when there is a limited amount of training data.