 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Policy Optimization for Optimal Stopping
Mar 25, 2022



Optimal stopping is the problem of determining when to stop a stochastic system in order to maximize reward, which is of practical importance in domains such as finance, operations management and healthcare. Existing methods for high-dimensional optimal stopping that are popular in practice produce deterministic linear policies -- policies that deterministically stop based on the sign of a weighted sum of basis functions -- but are not guaranteed to find the optimal policy within this policy class given a fixed basis function architecture. In this paper, we propose a new methodology for optimal stopping based on randomized linear policies, which choose to stop with a probability that is determined by a weighted sum of basis functions. We motivate these policies by establishing that under mild conditions, given a fixed basis function architecture, optimizing over randomized linear policies is equivalent to optimizing over deterministic linear policies. We formulate the problem of learning randomized linear policies from data as a smooth non-convex sample average approximation (SAA) problem. We theoretically prove the almost sure convergence of our randomized policy SAA problem and establish bounds on the out-of-sample performance of randomized policies obtained from our SAA problem based on Rademacher complexity. We also show that the SAA problem is in general NP-Hard, and consequently develop a practical heuristic for solving our randomized policy problem. Through numerical experiments on a benchmark family of option pricing problem instances, we show that our approach can substantially outperform state-of-the-art methods.
Decision Forest: A Nonparametric Approach to Modeling Irrational Choice
Apr 25, 2019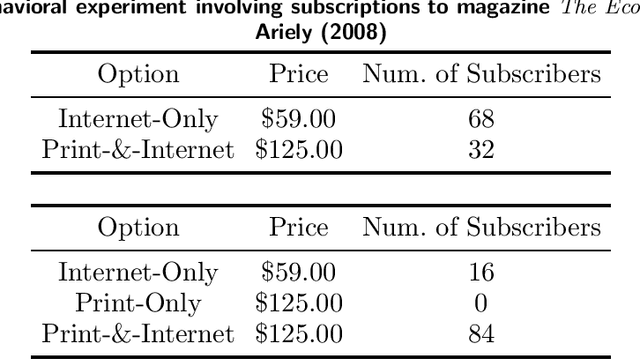
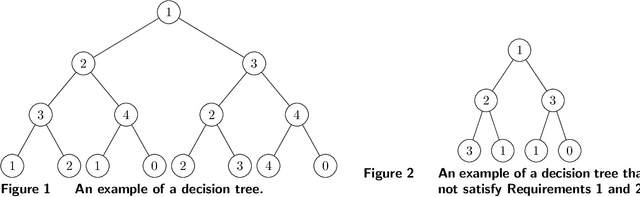
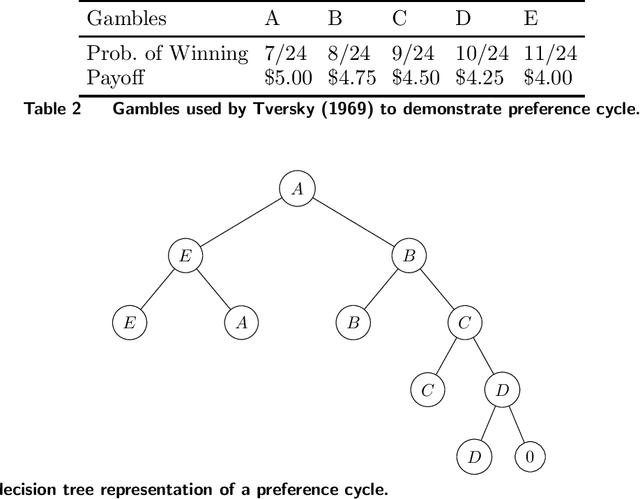
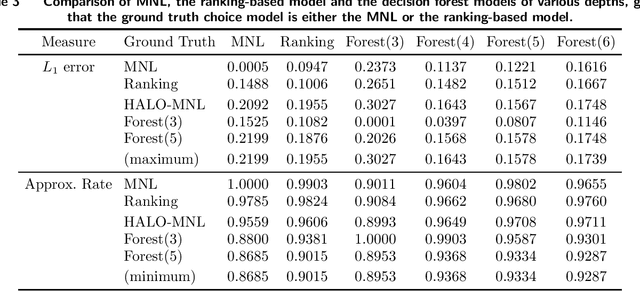
Customer behavior is often assumed to follow weak rationality, which implies that adding a product to an assortment will not increase the choice probability of another product in that assortment. However, an increasing amount of research has revealed that customers are not necessarily rational when making decisions. In this paper, we study a new nonparametric choice model that relaxes this assumption and can model a wider range of customer behavior, such as decoy effects between products. In this model, each customer type is associated with a binary decision tree, which represents a decision process for making a purchase based on checking for the existence of specific products in the assortment. Together with a probability distribution over customer types, we show that the resulting model -- a decision forest -- is able to represent any customer choice model, including models that are inconsistent with weak rationality. We theoretically characterize the depth of the forest needed to fit a data set of historical assortments and prove that asymptotically, a forest whose depth scales logarithmically in the number of assortments is sufficient to fit most data sets. We also propose an efficient algorithm for estimating such models from data, based on combining randomization and optimization. Using synthetic data and real transaction data exhibiting non-rational behavior, we show that the model outperforms the multinomial logit and ranking-based models in out-of-sample predictive ability.
Interpretable Optimal Stopping
Dec 18, 2018



Optimal stopping is the problem of deciding when to stop a stochastic system to obtain the greatest reward, arising in numerous application areas such as finance, healthcare and marketing. State-of-the-art methods for high-dimensional optimal stopping involve approximating the value function or the continuation value, and then using that approximation within a greedy policy. Although such policies can perform very well, they are generally not guaranteed to be interpretable; that is, a decision maker may not be able to easily see the link between the current system state and the policy's action. In this paper, we propose a new approach to optimal stopping, wherein the policy is represented as a binary tree, in the spirit of naturally interpretable tree models commonly used in machine learning. We formulate the problem of learning such policies from observed trajectories of the stochastic system as a sample average approximation (SAA) problem. We prove that the SAA problem converges under mild conditions as the sample size increases, but that computationally even immediate simplifications of the SAA problem are theoretically intractable. We thus propose a tractable heuristic for approximately solving the SAA problem, by greedily constructing the tree from the top down. We demonstrate the value of our approach by applying it to the canonical problem of option pricing, using both synthetic instances and instances calibrated with real S&P 500 data. Our method obtains policies that (1) outperform state-of-the-art non-interpretable methods, based on simulation-regression and martingale duality, and (2) possess a remarkably simple and intuitive structure.
Optimization of Tree Ensembles
May 30, 2017
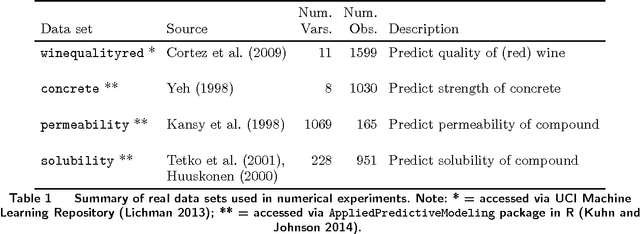
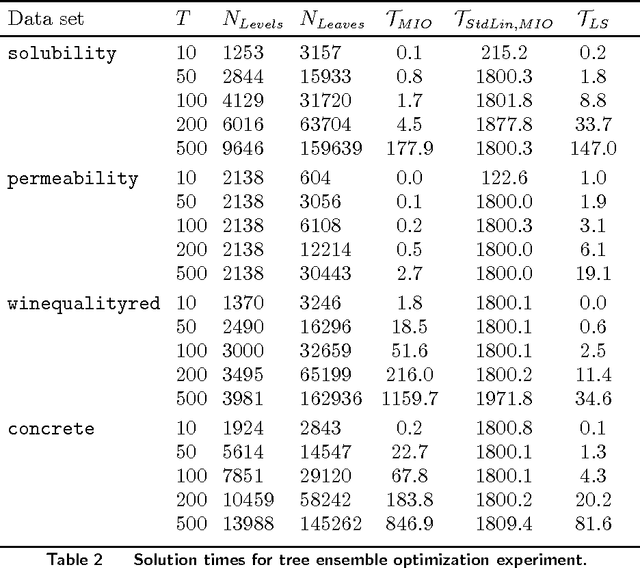

Tree ensemble models such as random forests and boosted trees are among the most widely used and practically successful predictive models in applied machine learning and business analytics. Although such models have been used to make predictions based on exogenous, uncontrollable independent variables, they are increasingly being used to make predictions where the independent variables are controllable and are also decision variables. In this paper, we study the problem of tree ensemble optimization: given a tree ensemble that predicts some dependent variable using controllable independent variables, how should we set these variables so as to maximize the predicted value? We formulate the problem as a mixed-integer optimization problem. We theoretically examine the strength of our formulation, provide a hierarchy of approximate formulations with bounds on approximation quality and exploit the structure of the problem to develop two large-scale solution methods, one based on Benders decomposition and one based on iteratively generating tree split constraints. We test our methodology on real data sets, including two case studies in drug design and customized pricing, and show that our methodology can efficiently solve large-scale instances to near or full optimality, and outperforms solutions obtained by heuristic approaches. In our drug design case, we show how our approach can identify compounds that efficiently trade-off predicted performance and novelty with respect to existing, known compounds. In our customized pricing case, we show how our approach can efficiently determine optimal store-level prices under a random forest model that delivers excellent predictive accuracy.
A Comparison of Monte Carlo Tree Search and Mathematical Optimization for Large Scale Dynamic Resource Allocation
May 21, 2014

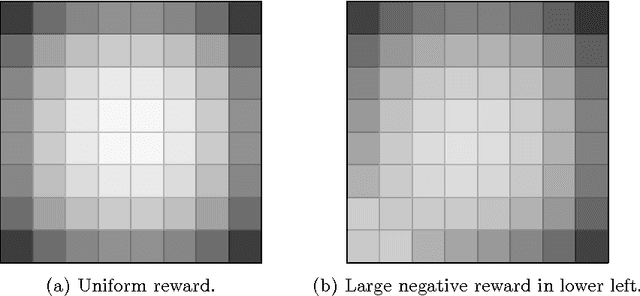
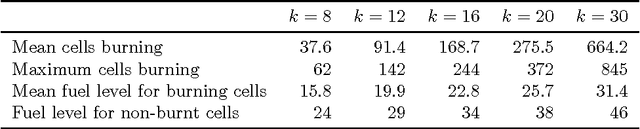
Dynamic resource allocation (DRA) problems are an important class of dynamic stochastic optimization problems that arise in a variety of important real-world applications. DRA problems are notoriously difficult to solve to optimality since they frequently combine stochastic elements with intractably large state and action spaces. Although the artificial intelligence and operations research communities have independently proposed two successful frameworks for solving dynamic stochastic optimization problems---Monte Carlo tree search (MCTS) and mathematical optimization (MO), respectively---the relative merits of these two approaches are not well understood. In this paper, we adapt both MCTS and MO to a problem inspired by tactical wildfire and management and undertake an extensive computational study comparing the two methods on large scale instances in terms of both the state and the action spaces. We show that both methods are able to greatly improve on a baseline, problem-specific heuristic. On smaller instances, the MCTS and MO approaches perform comparably, but the MO approach outperforms MCTS as the size of the problem increases for a fixed computational budget.