 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization of Tree Ensembles
Paper and Code
May 30, 2017
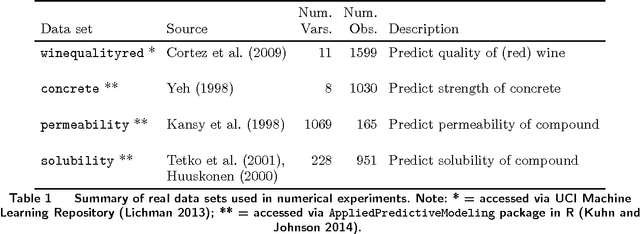
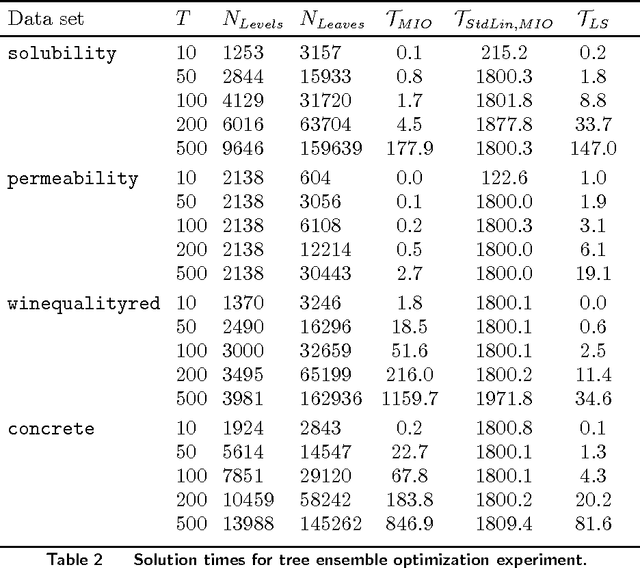

Tree ensemble models such as random forests and boosted trees are among the most widely used and practically successful predictive models in applied machine learning and business analytics. Although such models have been used to make predictions based on exogenous, uncontrollable independent variables, they are increasingly being used to make predictions where the independent variables are controllable and are also decision variables. In this paper, we study the problem of tree ensemble optimization: given a tree ensemble that predicts some dependent variable using controllable independent variables, how should we set these variables so as to maximize the predicted value? We formulate the problem as a mixed-integer optimization problem. We theoretically examine the strength of our formulation, provide a hierarchy of approximate formulations with bounds on approximation quality and exploit the structure of the problem to develop two large-scale solution methods, one based on Benders decomposition and one based on iteratively generating tree split constraints. We test our methodology on real data sets, including two case studies in drug design and customized pricing, and show that our methodology can efficiently solve large-scale instances to near or full optimality, and outperforms solutions obtained by heuristic approaches. In our drug design case, we show how our approach can identify compounds that efficiently trade-off predicted performance and novelty with respect to existing, known compounds. In our customized pricing case, we show how our approach can efficiently determine optimal store-level prices under a random forest model that delivers excellent predictive accuracy.