 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Large-scale Dataset Compression: Shifting Focus From Labels to Images
Feb 10, 2025



Dataset distillation and dataset pruning are two prominent techniques for compressing datasets to improve computational and storage efficiency. Despite their overlapping objectives, these approaches are rarely compared directly. Even within each field, the evaluation protocols are inconsistent across various methods, which complicates fair comparisons and hinders reproducibility. Considering these limitations, we introduce in this paper a benchmark that equitably evaluates methodologies across both distillation and pruning literatures. Notably, our benchmark reveals that in the mainstream dataset distillation setting for large-scale datasets, which heavily rely on soft labels from pre-trained models, even randomly selected subsets can achieve surprisingly competitive performance. This finding suggests that an overemphasis on soft labels may be diverting attention from the intrinsic value of the image data, while also imposing additional burdens in terms of generation, storage, and application. To address these issues, we propose a new framework for dataset compression, termed Prune, Combine, and Augment (PCA), which focuses on leveraging image data exclusively, relies solely on hard labels for evaluation, and achieves state-of-the-art performance in this setup. By shifting the emphasis back to the images, our benchmark and PCA framework pave the way for more balanced and accessible techniques in dataset compression research. Our code is available at: https://github.com/ArmandXiao/Rethinking-Dataset-Compression
Are Large-scale Soft Labels Necessary for Large-scale Dataset Distillation?
Oct 21, 2024



In ImageNet-condensation, the storage for auxiliary soft labels exceeds that of the condensed dataset by over 30 times. However, are large-scale soft labels necessary for large-scale dataset distillation? In this paper, we first discover that the high within-class similarity in condensed datasets necessitates the use of large-scale soft labels. This high within-class similarity can be attributed to the fact that previous methods use samples from different classes to construct a single batch for batch normalization (BN) matching. To reduce the within-class similarity, we introduce class-wise supervision during the image synthesizing process by batching the samples within classes, instead of across classes. As a result, we can increase within-class diversity and reduce the size of required soft labels. A key benefit of improved image diversity is that soft label compression can be achieved through simple random pruning, eliminating the need for complex rule-based strategies. Experiments validate our discoveries. For example, when condensing ImageNet-1K to 200 images per class, our approach compresses the required soft labels from 113 GB to 2.8 GB (40x compression) with a 2.6% performance gain. Code is available at: https://github.com/he-y/soft-label-pruning-for-dataset-distillation
Multisize Dataset Condensation
Mar 10, 2024

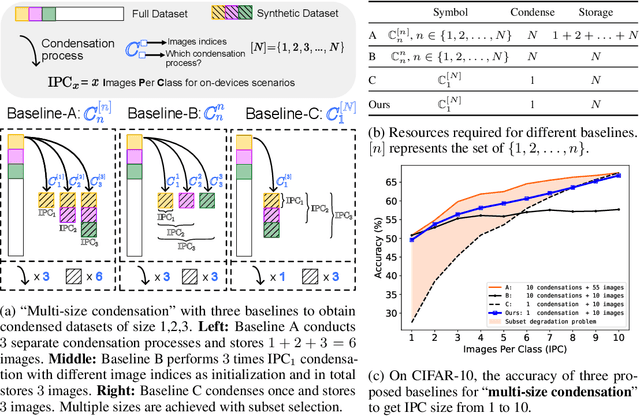

While dataset condensation effectively enhances training efficiency, its application in on-device scenarios brings unique challenges. 1) Due to the fluctuating computational resources of these devices, there's a demand for a flexible dataset size that diverges from a predefined size. 2) The limited computational power on devices often prevents additional condensation operations. These two challenges connect to the "subset degradation problem" in traditional dataset condensation: a subset from a larger condensed dataset is often unrepresentative compared to directly condensing the whole dataset to that smaller size. In this paper, we propose Multisize Dataset Condensation (MDC) by compressing N condensation processes into a single condensation process to obtain datasets with multiple sizes. Specifically, we introduce an "adaptive subset loss" on top of the basic condensation loss to mitigate the "subset degradation problem". Our MDC method offers several benefits: 1) No additional condensation process is required; 2) reduced storage requirement by reusing condensed images. Experiments validate our findings on networks including ConvNet, ResNet and DenseNet, and datasets including SVHN, CIFAR-10, CIFAR-100 and ImageNet. For example, we achieved 6.40% average accuracy gains on condensing CIFAR-10 to ten images per class. Code is available at: https://github.com/he-y/Multisize-Dataset-Condensation.
You Only Condense Once: Two Rules for Pruning Condensed Datasets
Oct 21, 2023

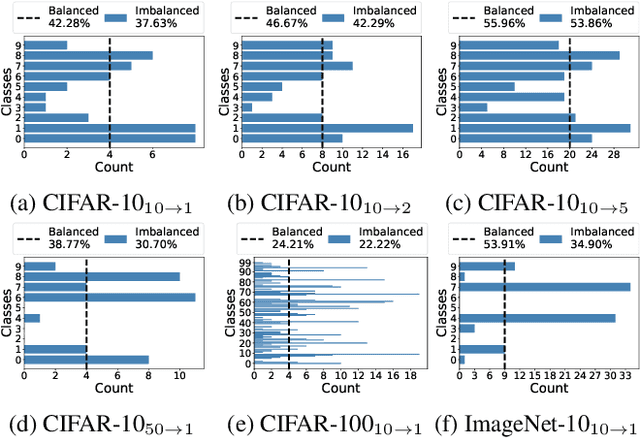

Dataset condensation is a crucial tool for enhancing training efficiency by reducing the size of the training dataset, particularly in on-device scenarios. However, these scenarios have two significant challenges: 1) the varying computational resources available on the devices require a dataset size different from the pre-defined condensed dataset, and 2) the limited computational resources often preclude the possibility of conducting additional condensation processes. We introduce You Only Condense Once (YOCO) to overcome these limitations. On top of one condensed dataset, YOCO produces smaller condensed datasets with two embarrassingly simple dataset pruning rules: Low LBPE Score and Balanced Construction. YOCO offers two key advantages: 1) it can flexibly resize the dataset to fit varying computational constraints, and 2) it eliminates the need for extra condensation processes, which can be computationally prohibitive. Experiments validate our findings on networks including ConvNet, ResNet and DenseNet, and datasets including CIFAR-10, CIFAR-100 and ImageNet. For example, our YOCO surpassed various dataset condensation and dataset pruning methods on CIFAR-10 with ten Images Per Class (IPC), achieving 6.98-8.89% and 6.31-23.92% accuracy gains, respectively. The code is available at: https://github.com/he-y/you-only-condense-once.
Structured Pruning for Deep Convolutional Neural Networks: A survey
Mar 01, 2023
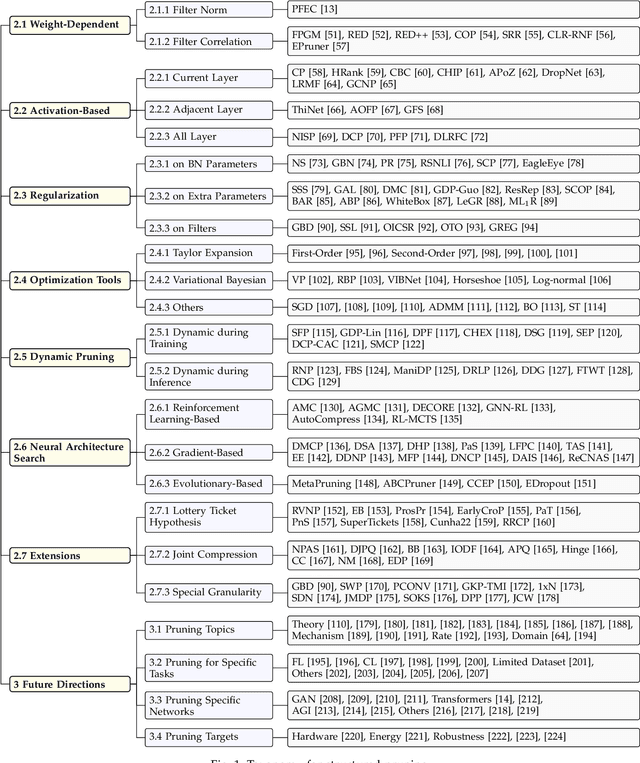


The remarkable performance of deep Convolutional neural networks (CNNs) is generally attributed to their deeper and wider architectures, which can come with significant computational costs. Pruning neural networks has thus gained interest since it effectively lowers storage and computational costs. In contrast to weight pruning, which results in unstructured models, structured pruning provides the benefit of realistic acceleration by producing models that are friendly to hardware implementation. The special requirements of structured pruning have led to the discovery of numerous new challenges and the development of innovative solutions. This article surveys the recent progress towards structured pruning of deep CNNs. We summarize and compare the state-of-the-art structured pruning techniques with respect to filter ranking methods, regularization methods, dynamic execution, neural architecture search, the lottery ticket hypothesis, and the applications of pruning. While discussing structured pruning algorithms, we briefly introduce the unstructured pruning counterpart to emphasize their differences. Furthermore, we provide insights into potential research opportunities in the field of structured pruning. A curated list of neural network pruning papers can be found at https://github.com/he-y/Awesome-Pruning