 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMieDB-100k: A Comprehensive Dataset for Medical Image Editing
Feb 10, 2026The scarcity of high-quality data remains a primary bottleneck in adapting multimodal generative models for medical image editing. Existing medical image editing datasets often suffer from limited diversity, neglect of medical image understanding and inability to balance quality with scalability. To address these gaps, we propose MieDB-100k, a large-scale, high-quality and diverse dataset for text-guided medical image editing. It categorizes editing tasks into perspectives of Perception, Modification and Transformation, considering both understanding and generation abilities. We construct MieDB-100k via a data curation pipeline leveraging both modality-specific expert models and rule-based data synthetic methods, followed by rigorous manual inspection to ensure clinical fidelity. Extensive experiments demonstrate that model trained with MieDB-100k consistently outperform both open-source and proprietary models while exhibiting strong generalization ability. We anticipate that this dataset will serve as a cornerstone for future advancements in specialized medical image editing.
EarthCrafter: Scalable 3D Earth Generation via Dual-Sparse Latent Diffusion
Jul 23, 2025Despite the remarkable developments achieved by recent 3D generation works, scaling these methods to geographic extents, such as modeling thousands of square kilometers of Earth's surface, remains an open challenge. We address this through a dual innovation in data infrastructure and model architecture. First, we introduce Aerial-Earth3D, the largest 3D aerial dataset to date, consisting of 50k curated scenes (each measuring 600m x 600m) captured across the U.S. mainland, comprising 45M multi-view Google Earth frames. Each scene provides pose-annotated multi-view images, depth maps, normals, semantic segmentation, and camera poses, with explicit quality control to ensure terrain diversity. Building on this foundation, we propose EarthCrafter, a tailored framework for large-scale 3D Earth generation via sparse-decoupled latent diffusion. Our architecture separates structural and textural generation: 1) Dual sparse 3D-VAEs compress high-resolution geometric voxels and textural 2D Gaussian Splats (2DGS) into compact latent spaces, largely alleviating the costly computation suffering from vast geographic scales while preserving critical information. 2) We propose condition-aware flow matching models trained on mixed inputs (semantics, images, or neither) to flexibly model latent geometry and texture features independently. Extensive experiments demonstrate that EarthCrafter performs substantially better in extremely large-scale generation. The framework further supports versatile applications, from semantic-guided urban layout generation to unconditional terrain synthesis, while maintaining geographic plausibility through our rich data priors from Aerial-Earth3D. Our project page is available at https://whiteinblue.github.io/earthcrafter/
AnyLogo: Symbiotic Subject-Driven Diffusion System with Gemini Status
Sep 26, 2024

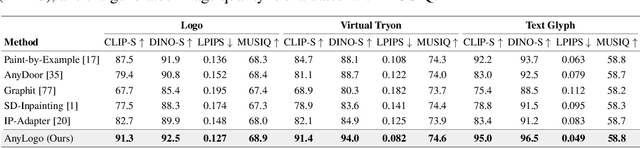
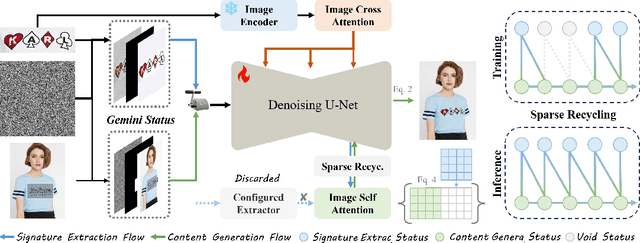
Diffusion models have made compelling progress on facilitating high-throughput daily production. Nevertheless, the appealing customized requirements are remain suffered from instance-level finetuning for authentic fidelity. Prior zero-shot customization works achieve the semantic consistence through the condensed injection of identity features, while addressing detailed low-level signatures through complex model configurations and subject-specific fabrications, which significantly break the statistical coherence within the overall system and limit the applicability across various scenarios. To facilitate the generic signature concentration with rectified efficiency, we present \textbf{AnyLogo}, a zero-shot region customizer with remarkable detail consistency, building upon the symbiotic diffusion system with eliminated cumbersome designs. Streamlined as vanilla image generation, we discern that the rigorous signature extraction and creative content generation are promisingly compatible and can be systematically recycled within a single denoising model. In place of the external configurations, the gemini status of the denoising model promote the reinforced subject transmission efficiency and disentangled semantic-signature space with continuous signature decoration. Moreover, the sparse recycling paradigm is adopted to prevent the duplicated risk with compressed transmission quota for diversified signature stimulation. Extensive experiments on constructed logo-level benchmarks demonstrate the effectiveness and practicability of our methods.
VCD-Texture: Variance Alignment based 3D-2D Co-Denoising for Text-Guided Texturing
Jul 05, 2024
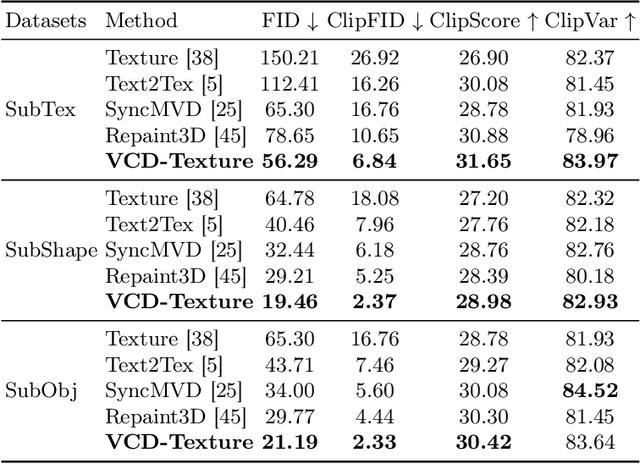
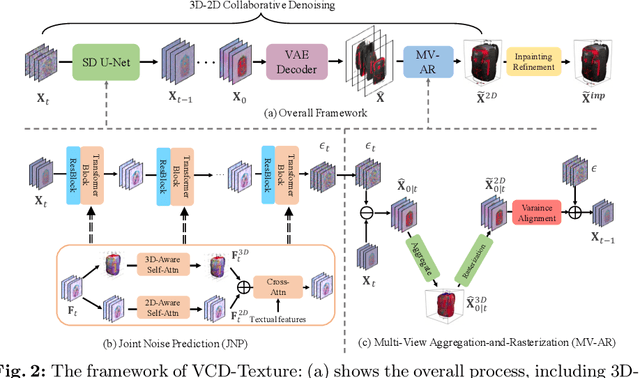
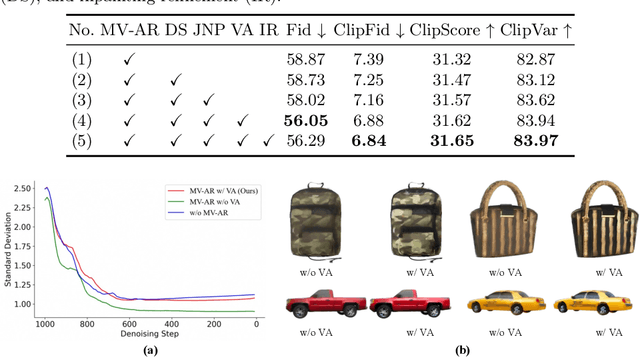
Recent research on texture synthesis for 3D shapes benefits a lot from dramatically developed 2D text-to-image diffusion models, including inpainting-based and optimization-based approaches. However, these methods ignore the modal gap between the 2D diffusion model and 3D objects, which primarily render 3D objects into 2D images and texture each image separately. In this paper, we revisit the texture synthesis and propose a Variance alignment based 3D-2D Collaborative Denoising framework, dubbed VCD-Texture, to address these issues. Formally, we first unify both 2D and 3D latent feature learning in diffusion self-attention modules with re-projected 3D attention receptive fields. Subsequently, the denoised multi-view 2D latent features are aggregated into 3D space and then rasterized back to formulate more consistent 2D predictions. However, the rasterization process suffers from an intractable variance bias, which is theoretically addressed by the proposed variance alignment, achieving high-fidelity texture synthesis. Moreover, we present an inpainting refinement to further improve the details with conflicting regions. Notably, there is not a publicly available benchmark to evaluate texture synthesis, which hinders its development. Thus we construct a new evaluation set built upon three open-source 3D datasets and propose to use four metrics to thoroughly validate the texturing performance. Comprehensive experiments demonstrate that VCD-Texture achieves superior performance against other counterparts.
A Transformer-based Network for Deformable Medical Image Registration
Feb 24, 2022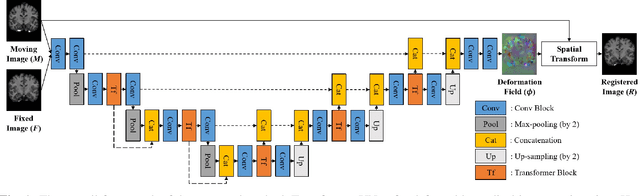
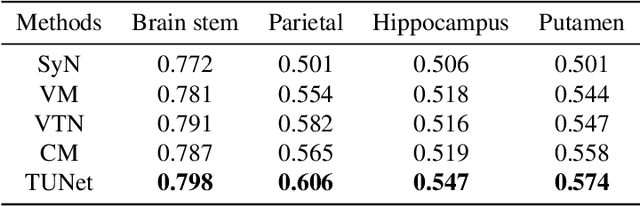
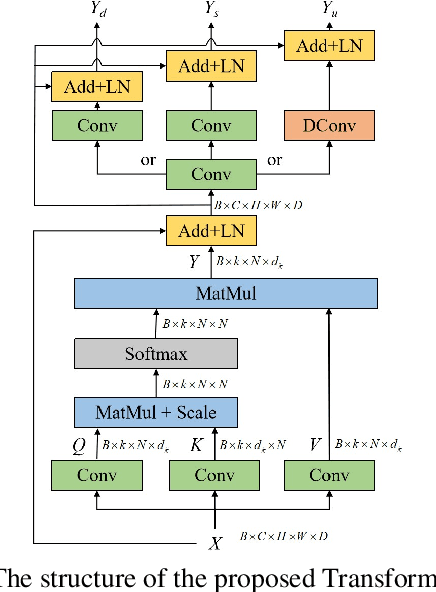
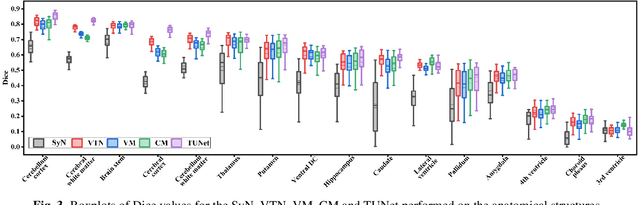
Deformable medical image registration plays an important role in clinical diagnosis and treatment. Recently, the deep learning (DL) based image registration methods have been widely investigated and showed excellent performance in computational speed. However, these methods cannot provide enough registration accuracy because of insufficient ability in representing both the global and local features of the moving and fixed images. To address this issue, this paper has proposed the transformer based image registration method. This method uses the distinctive transformer to extract the global and local image features for generating the deformation fields, based on which the registered image is produced in an unsupervised way. Our method can improve the registration accuracy effectively by means of self-attention mechanism and bi-level information flow. Experimental results on such brain MR image datasets as LPBA40 and OASIS-1 demonstrate that compared with several traditional and DL based registration methods, our method provides higher registration accuracy in terms of dice values.
* 5 pages, 4 figures, 18 conferences
RSDet++: Point-based Modulated Loss for More Accurate Rotated Object Detection
Sep 24, 2021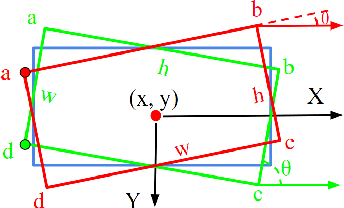
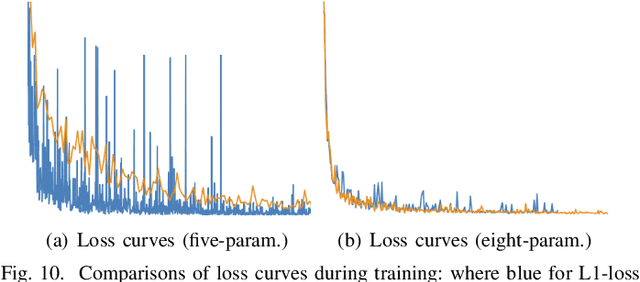

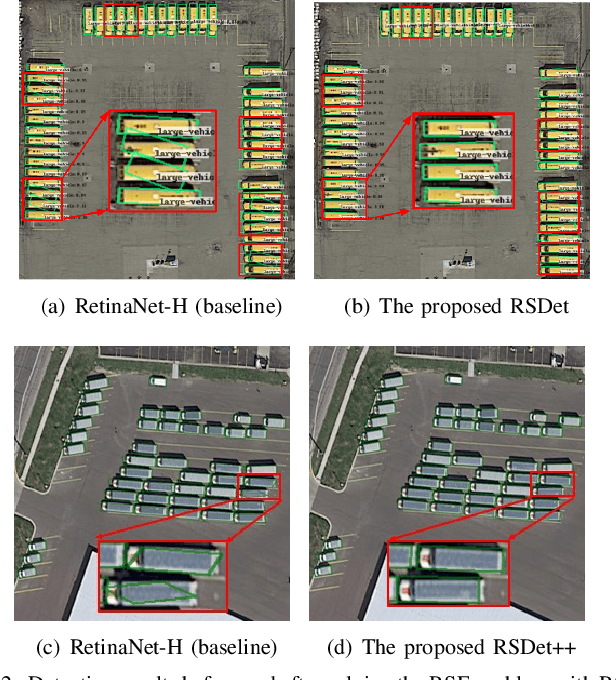
We classify the discontinuity of loss in both five-param and eight-param rotated object detection methods as rotation sensitivity error (RSE) which will result in performance degeneration. We introduce a novel modulated rotation loss to alleviate the problem and propose a rotation sensitivity detection network (RSDet) which is consists of an eight-param single-stage rotated object detector and the modulated rotation loss. Our proposed RSDet has several advantages: 1) it reformulates the rotated object detection problem as predicting the corners of objects while most previous methods employ a five-para-based regression method with different measurement units. 2) modulated rotation loss achieves consistent improvement on both five-param and eight-param rotated object detection methods by solving the discontinuity of loss. To further improve the accuracy of our method on objects smaller than 10 pixels, we introduce a novel RSDet++ which is consists of a point-based anchor-free rotated object detector and a modulated rotation loss. Extensive experiments demonstrate the effectiveness of both RSDet and RSDet++, which achieve competitive results on rotated object detection in the challenging benchmarks DOTA1.0, DOTA1.5, and DOTA2.0. We hope the proposed method can provide a new perspective for designing algorithms to solve rotated object detection and pay more attention to tiny objects. The codes and models are available at: https://github.com/yangxue0827/RotationDetection.
Learning Modulated Loss for Rotated Object Detection
Dec 20, 2019

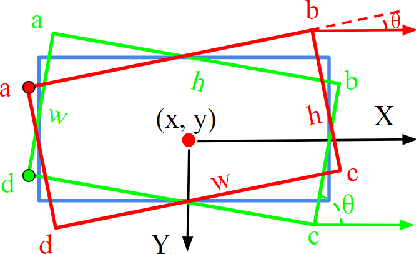

Popular rotated detection methods usually use five parameters (coordinates of the central point, width, height, and rotation angle) to describe the rotated bounding box and l1-loss as the loss function. In this paper, we argue that the aforementioned integration can cause training instability and performance degeneration, due to the loss discontinuity resulted from the inherent periodicity of angles and the associated sudden exchange of width and height. This problem is further pronounced given the regression inconsistency among five parameters with different measurement units. We refer to the above issues as rotation sensitivity error (RSE) and propose a modulated rotation loss to dismiss the loss discontinuity. Our new loss is combined with the eight-parameter regression to further solve the problem of inconsistent parameter regression. Experiments show the state-of-art performances of our method on the public aerial image benchmark DOTA and UCAS-AOD. Its generalization abilities are also verified on ICDAR2015, HRSC2016, and FDDB. Qualitative improvements can be seen in Fig 1, and the source code will be released with the publication of the paper.