 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperAdam: A Learnable Task-Adaptive Adam for Network Training
Paper and Code
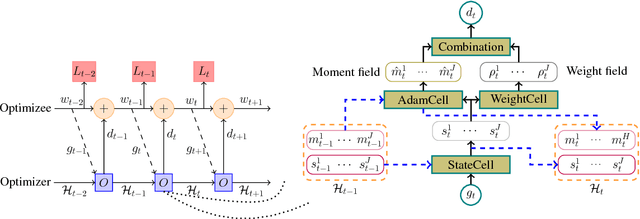

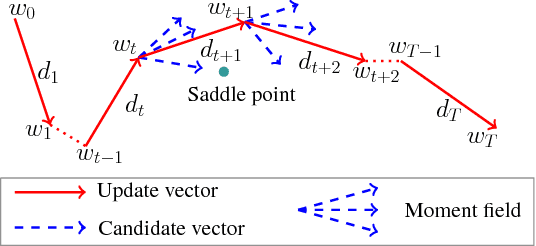

Deep neural networks are traditionally trained using human-designed stochastic optimization algorithms, such as SGD and Adam. Recently, the approach of learning to optimize network parameters has emerged as a promising research topic. However, these learned black-box optimizers sometimes do not fully utilize the experience in human-designed optimizers, therefore have limitation in generalization ability. In this paper, a new optimizer, dubbed as \textit{HyperAdam}, is proposed that combines the idea of "learning to optimize" and traditional Adam optimizer. Given a network for training, its parameter update in each iteration generated by HyperAdam is an adaptive combination of multiple updates generated by Adam with varying decay rates. The combination weights and decay rates in HyperAdam are adaptively learned depending on the task. HyperAdam is modeled as a recurrent neural network with AdamCell, WeightCell and StateCell. It is justified to be state-of-the-art for various network training, such as multilayer perceptron, CNN and LSTM.