 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Food Recommendation using Clustering and Self-supervised Learning
Jun 27, 2024



Food recommendation systems serve as pivotal components in the realm of digital lifestyle services, designed to assist users in discovering recipes and food items that resonate with their unique dietary predilections. Typically, multi-modal descriptions offer an exhaustive profile for each recipe, thereby ensuring recommendations that are both personalized and accurate. Our preliminary investigation of two datasets indicates that pre-trained multi-modal dense representations might precipitate a deterioration in performance compared to ID features when encapsulating interactive relationships. This observation implies that ID features possess a relative superiority in modeling interactive collaborative signals. Consequently, contemporary cutting-edge methodologies augment ID features with multi-modal information as supplementary features, overlooking the latent semantic relations between recipes. To rectify this, we present CLUSSL, a novel food recommendation framework that employs clustering and self-supervised learning. Specifically, CLUSSL formulates a modality-specific graph tailored to each modality with discrete/continuous features, thereby transforming semantic features into structural representation. Furthermore, CLUSSL procures recipe representations pertinent to different modalities via graph convolutional operations. A self-supervised learning objective is proposed to foster independence between recipe representations derived from different unimodal graphs. Comprehensive experiments on real-world datasets substantiate that CLUSSL consistently surpasses state-of-the-art recommendation benchmarks in performance.
Unsupervised Representation Learning for Time Series: A Review
Aug 03, 2023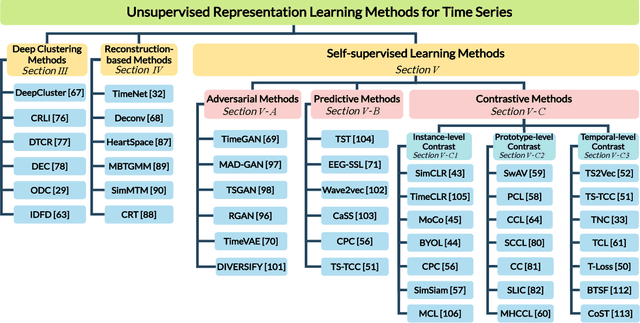
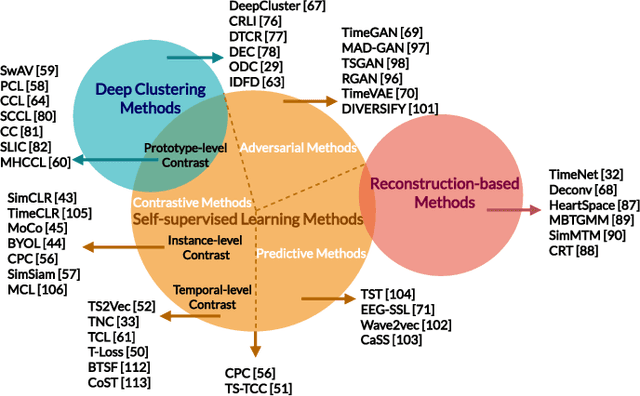
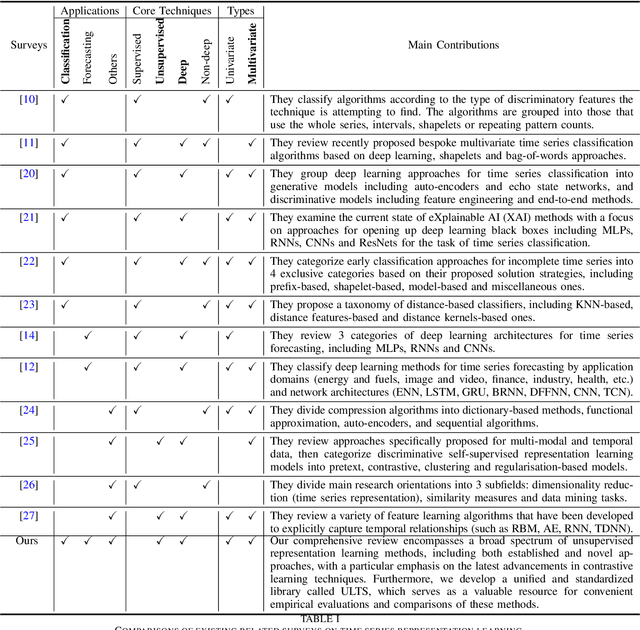

Unsupervised representation learning approaches aim to learn discriminative feature representations from unlabeled data, without the requirement of annotating every sample. Enabling unsupervised representation learning is extremely crucial for time series data, due to its unique annotation bottleneck caused by its complex characteristics and lack of visual cues compared with other data modalities. In recent years, unsupervised representation learning techniques have advanced rapidly in various domains. However, there is a lack of systematic analysis of unsupervised representation learning approaches for time series. To fill the gap, we conduct a comprehensive literature review of existing rapidly evolving unsupervised representation learning approaches for time series. Moreover, we also develop a unified and standardized library, named ULTS (i.e., Unsupervised Learning for Time Series), to facilitate fast implementations and unified evaluations on various models. With ULTS, we empirically evaluate state-of-the-art approaches, especially the rapidly evolving contrastive learning methods, on 9 diverse real-world datasets. We further discuss practical considerations as well as open research challenges on unsupervised representation learning for time series to facilitate future research in this field.
MHCCL: Masked Hierarchical Cluster-wise Contrastive Learning for Multivariate Time Series
Dec 02, 2022Learning semantic-rich representations from raw unlabeled time series data is critical for downstream tasks such as classification and forecasting. Contrastive learning has recently shown its promising representation learning capability in the absence of expert annotations. However, existing contrastive approaches generally treat each instance independently, which leads to false negative pairs that share the same semantics. To tackle this problem, we propose MHCCL, a Masked Hierarchical Cluster-wise Contrastive Learning model, which exploits semantic information obtained from the hierarchical structure consisting of multiple latent partitions for multivariate time series. Motivated by the observation that fine-grained clustering preserves higher purity while coarse-grained one reflects higher-level semantics, we propose a novel downward masking strategy to filter out fake negatives and supplement positives by incorporating the multi-granularity information from the clustering hierarchy. In addition, a novel upward masking strategy is designed in MHCCL to remove outliers of clusters at each partition to refine prototypes, which helps speed up the hierarchical clustering process and improves the clustering quality. We conduct experimental evaluations on seven widely-used multivariate time series datasets. The results demonstrate the superiority of MHCCL over the state-of-the-art approaches for unsupervised time series representation learning.