 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-aware Occlusion Filtering Neural Radiance Fields in the Wild
Paper and Code
Mar 05, 2023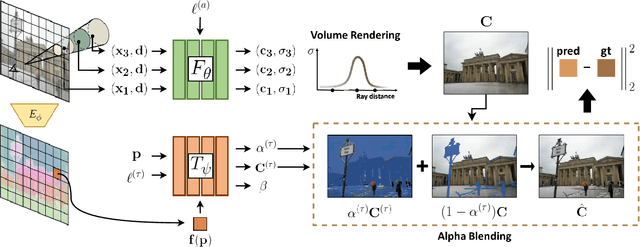
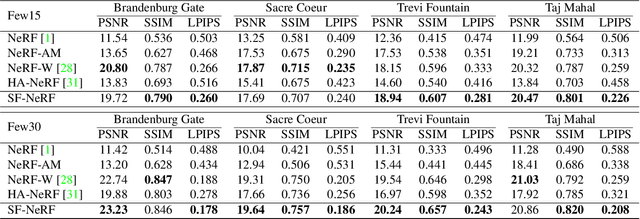

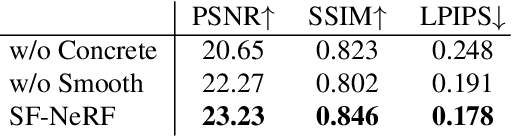
We present a learning framework for reconstructing neural scene representations from a small number of unconstrained tourist photos. Since each image contains transient occluders, decomposing the static and transient components is necessary to construct radiance fields with such in-the-wild photographs where existing methods require a lot of training data. We introduce SF-NeRF, aiming to disentangle those two components with only a few images given, which exploits semantic information without any supervision. The proposed method contains an occlusion filtering module that predicts the transient color and its opacity for each pixel, which enables the NeRF model to solely learn the static scene representation. This filtering module learns the transient phenomena guided by pixel-wise semantic features obtained by a trainable image encoder that can be trained across multiple scenes to learn the prior of transient objects. Furthermore, we present two techniques to prevent ambiguous decomposition and noisy results of the filtering module. We demonstrate that our method outperforms state-of-the-art novel view synthesis methods on Phototourism dataset in a few-shot setting.