 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation-equivariant Image Quantizer for Bi-directional Image-Text Generation
Paper and Code
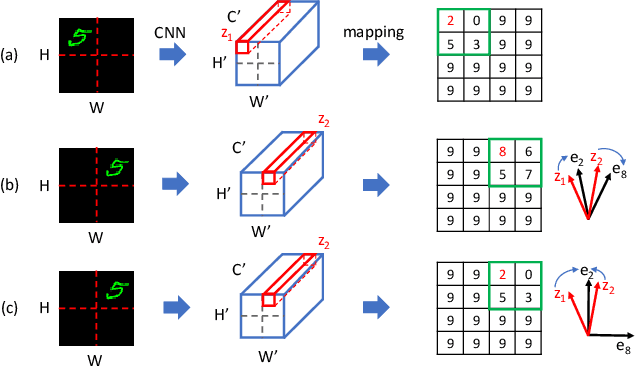
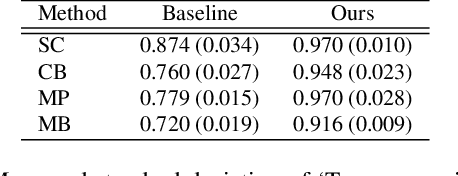
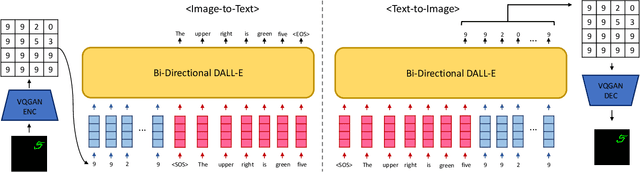

Recently, vector-quantized image modeling has demonstrated impressive performance on generation tasks such as text-to-image generation. However, we discover that the current image quantizers do not satisfy translation equivariance in the quantized space due to aliasing, degrading performance in the downstream text-to-image generation and image-to-text generation, even in simple experimental setups. Instead of focusing on anti-aliasing, we take a direct approach to encourage translation equivariance in the quantized space. In particular, we explore a desirable property of image quantizers, called 'Translation Equivariance in the Quantized Space' and propose a simple but effective way to achieve translation equivariance by regularizing orthogonality in the codebook embedding vectors. Using this method, we improve accuracy by +22% in text-to-image generation and +26% in image-to-text generation, outperforming the VQGAN.