 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOWQ: Lessons learned from activation outliers for weight quantization in large language models
Jun 13, 2023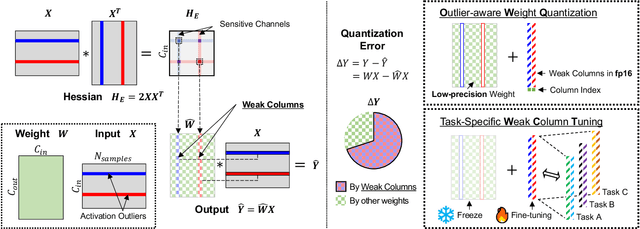
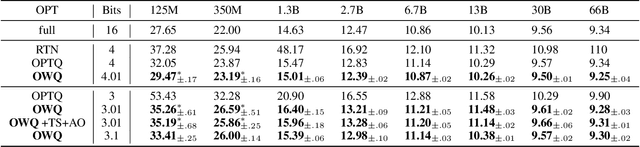
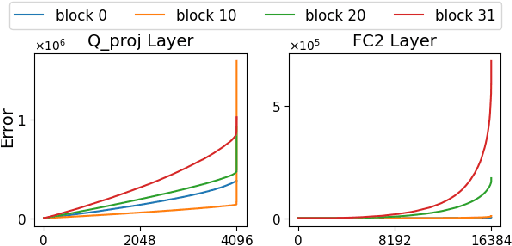
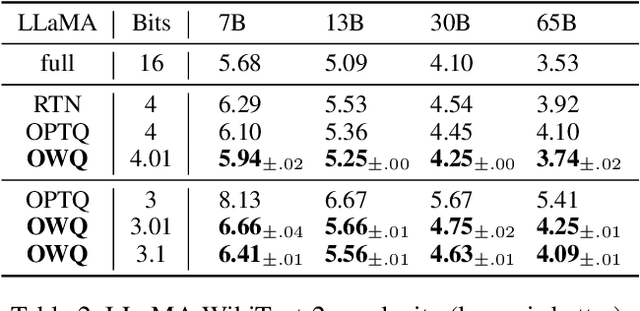
Large language models (LLMs) with hundreds of billions of parameters show impressive results across various language tasks using simple prompt tuning and few-shot examples, without the need for task-specific fine-tuning. However, their enormous size requires multiple server-grade GPUs even for inference, creating a significant cost barrier. To address this limitation, we introduce a novel post-training quantization method for weights with minimal quality degradation. While activation outliers are known to be problematic in activation quantization, our theoretical analysis suggests that we can identify factors contributing to weight quantization errors by considering activation outliers. We propose an innovative PTQ scheme called outlier-aware weight quantization (OWQ), which identifies vulnerable weights and allocates high-precision to them. Our extensive experiments demonstrate that the 3.01-bit models produced by OWQ exhibit comparable quality to the 4-bit models generated by OPTQ.