 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi,KIA: A Speech Emotion Recognition Dataset for Wake-Up Words
Nov 07, 2022
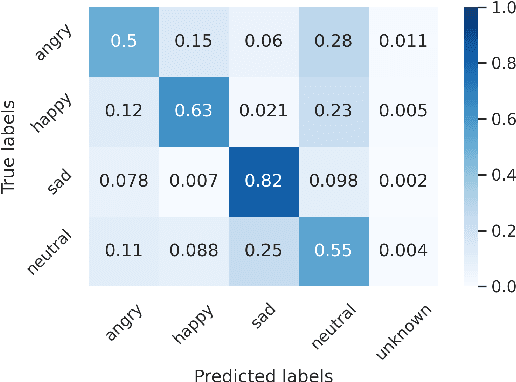
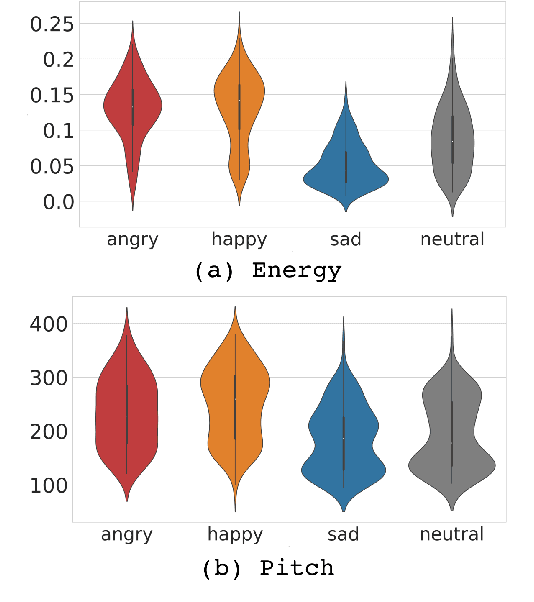
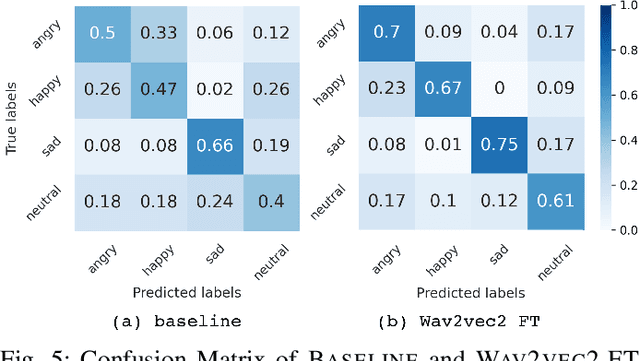
Wake-up words (WUW) is a short sentence used to activate a speech recognition system to receive the user's speech input. WUW utterances include not only the lexical information for waking up the system but also non-lexical information such as speaker identity or emotion. In particular, recognizing the user's emotional state may elaborate the voice communication. However, there is few dataset where the emotional state of the WUW utterances is labeled. In this paper, we introduce Hi, KIA, a new WUW dataset which consists of 488 Korean accent emotional utterances collected from four male and four female speakers and each of utterances is labeled with four emotional states including anger, happy, sad, or neutral. We present the step-by-step procedure to build the dataset, covering scenario selection, post-processing, and human validation for label agreement. Also, we provide two classification models for WUW speech emotion recognition using the dataset. One is based on traditional hand-craft features and the other is a transfer-learning approach using a pre-trained neural network. These classification models could be used as benchmarks in further research.