 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignificant Low-dimensional Spectral-temporal Features for Seizure Detection
Feb 13, 2022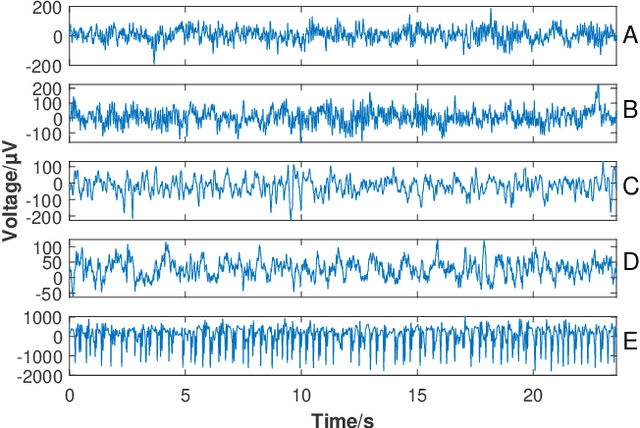
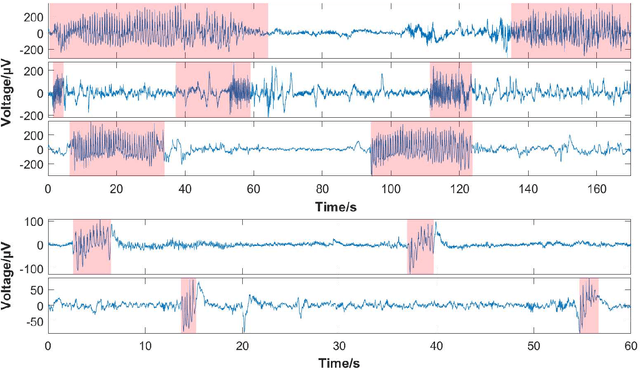

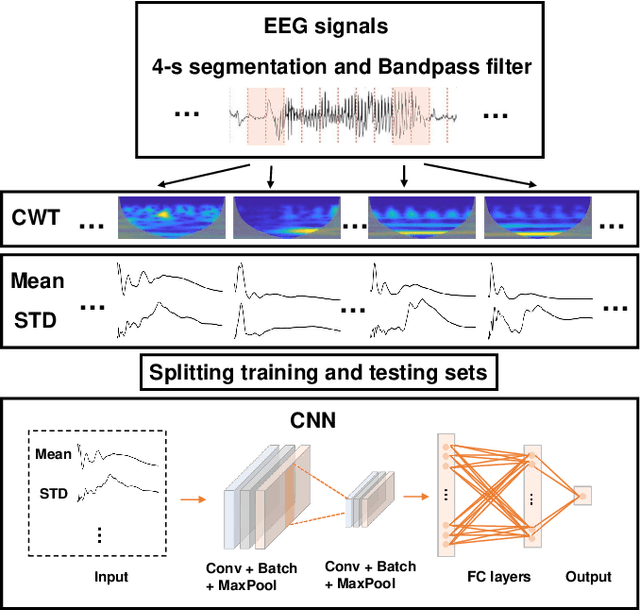
Seizure onset detection in electroencephalography (EEG) signals is a challenging task due to the non-stereotyped seizure activities as well as their stochastic and non-stationary characteristics in nature. Joint spectral-temporal features are believed to contain sufficient and powerful feature information for absence seizure detection. However, the resulting high-dimensional features involve redundant information and require heavy computational load. Here, we discover significant low-dimensional spectral-temporal features in terms of mean-standard deviation of wavelet transform coefficient (MS-WTC), based on which a novel absence seizure detection framework is developed. The EEG signals are transformed into the spectral-temporal domain, with their low-dimensional features fed into a convolutional neural network. Superior detection performance is achieved on the widely-used benchmark dataset as well as a clinical dataset from the Chinese 301 Hospital. For the former, seven classification tasks were evaluated with the accuracy from 99.8% to 100.0%, while for the latter, the method achieved a mean accuracy of 94.7%, overwhelming other methods with low-dimensional temporal and spectral features. Experimental results on two seizure datasets demonstrate reliability, efficiency and stability of our proposed MS-WTC method, validating the significance of the extracted low-dimensional spectral-temporal features.
ViR:the Vision Reservoir
Dec 29, 2021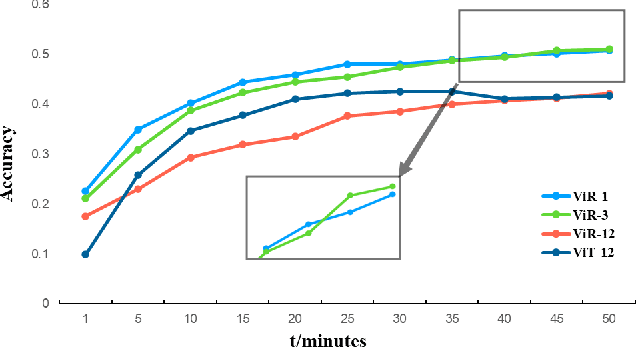
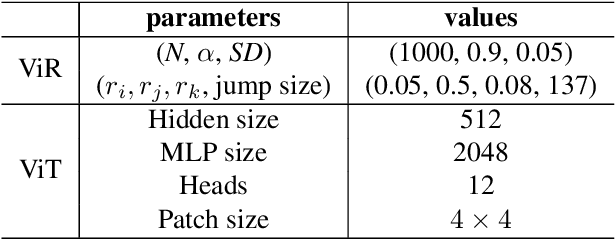

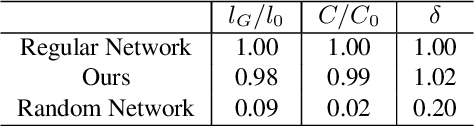
The most recent year has witnessed the success of applying the Vision Transformer (ViT) for image classification. However, there are still evidences indicating that ViT often suffers following two aspects, i) the high computation and the memory burden from applying the multiple Transformer layers for pre-training on a large-scale dataset, ii) the over-fitting when training on small datasets from scratch. To address these problems, a novel method, namely, Vision Reservoir computing (ViR), is proposed here for image classification, as a parallel to ViT. By splitting each image into a sequence of tokens with fixed length, the ViR constructs a pure reservoir with a nearly fully connected topology to replace the Transformer module in ViT. Two kinds of deep ViR models are subsequently proposed to enhance the network performance. Comparative experiments between the ViR and the ViT are carried out on several image classification benchmarks. Without any pre-training process, the ViR outperforms the ViT in terms of both model and computational complexity. Specifically, the number of parameters of the ViR is about 15% even 5% of the ViT, and the memory footprint is about 20% to 40% of the ViT. The superiority of the ViR performance is explained by Small-World characteristics, Lyapunov exponents, and memory capacity.