 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Enhanced Multi-View Trajectory Representation Learning: Bridging the Gap through Self-Supervised Models
Paper and Code
Oct 17, 2024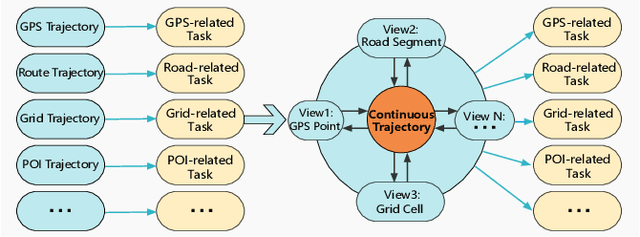
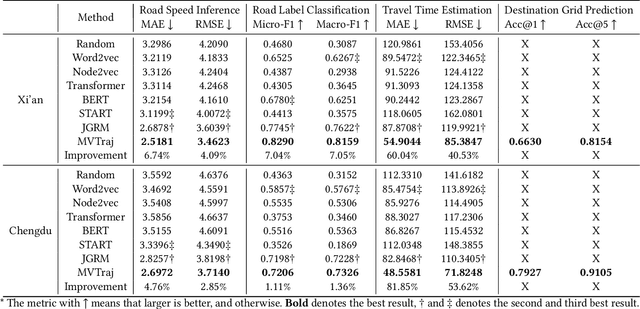
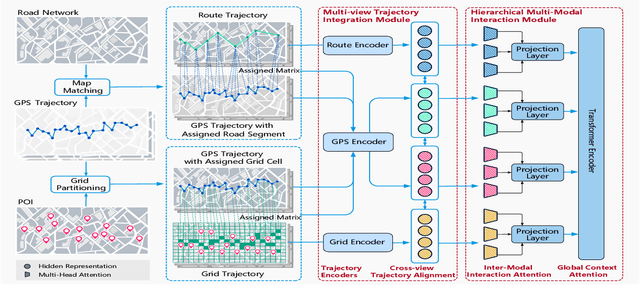

Modeling trajectory data with generic-purpose dense representations has become a prevalent paradigm for various downstream applications, such as trajectory classification, travel time estimation and similarity computation. However, existing methods typically rely on trajectories from a single spatial view, limiting their ability to capture the rich contextual information that is crucial for gaining deeper insights into movement patterns across different geospatial contexts. To this end, we propose MVTraj, a novel multi-view modeling method for trajectory representation learning. MVTraj integrates diverse contextual knowledge, from GPS to road network and points-of-interest to provide a more comprehensive understanding of trajectory data. To align the learning process across multiple views, we utilize GPS trajectories as a bridge and employ self-supervised pretext tasks to capture and distinguish movement patterns across different spatial views. Following this, we treat trajectories from different views as distinct modalities and apply a hierarchical cross-modal interaction module to fuse the representations, thereby enriching the knowledge derived from multiple sources. Extensive experiments on real-world datasets demonstrate that MVTraj significantly outperforms existing baselines in tasks associated with various spatial views, validating its effectiveness and practical utility in spatio-temporal modeling.