 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Quantization-Aware Knowledge Distillation
Paper and Code
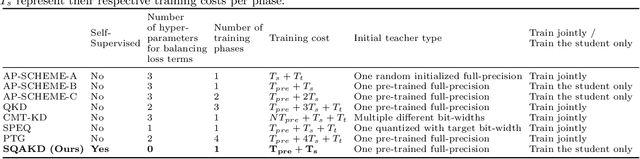
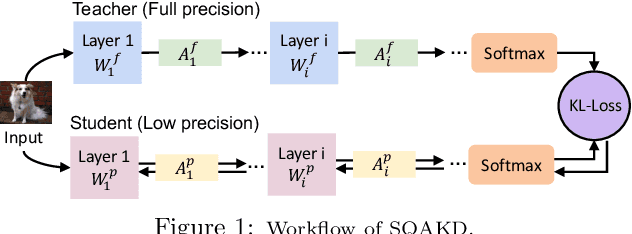
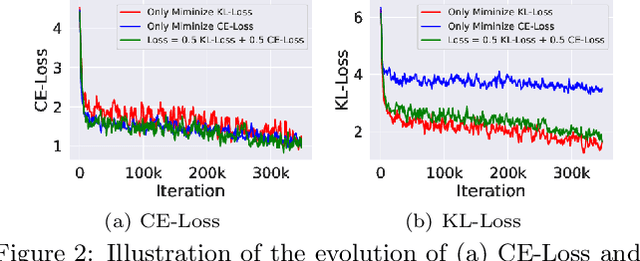

Quantization-aware training (QAT) and Knowledge Distillation (KD) are combined to achieve competitive performance in creating low-bit deep learning models. However, existing works applying KD to QAT require tedious hyper-parameter tuning to balance the weights of different loss terms, assume the availability of labeled training data, and require complex, computationally intensive training procedures for good performance. To address these limitations, this paper proposes a novel Self-Supervised Quantization-Aware Knowledge Distillation (SQAKD) framework. SQAKD first unifies the forward and backward dynamics of various quantization functions, making it flexible for incorporating various QAT works. Then it formulates QAT as a co-optimization problem that simultaneously minimizes the KL-Loss between the full-precision and low-bit models for KD and the discretization error for quantization, without supervision from labels. A comprehensive evaluation shows that SQAKD substantially outperforms the state-of-the-art QAT and KD works for a variety of model architectures. Our code is at: https://github.com/kaiqi123/SQAKD.git.