 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntriguing Usage of Applicability Domain: Lessons from Cheminformatics Applied to Adversarial Learning
May 02, 2021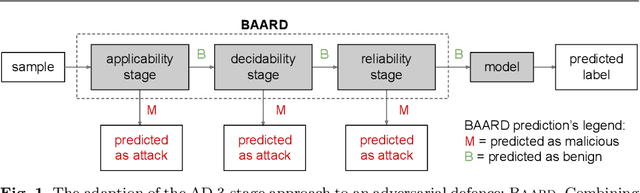
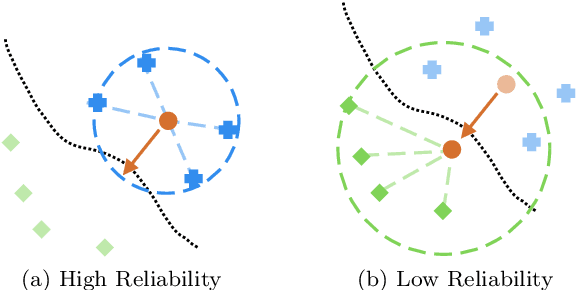
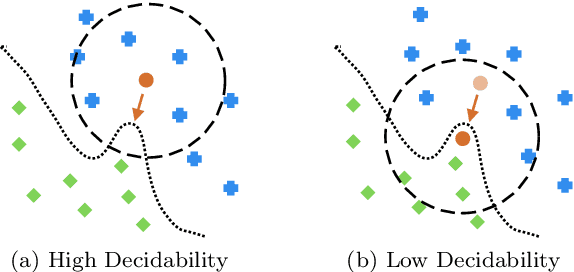
Defending machine learning models from adversarial attacks is still a challenge: none of the robust models is utterly immune to adversarial examples to date. Different defences have been proposed; however, most of them are tailored to particular ML models and adversarial attacks, therefore their effectiveness and applicability are strongly limited. A similar problem plagues cheminformatics: Quantitative Structure-Activity Relationship (QSAR) models struggle to predict biological activity for the entire chemical space because they are trained on a very limited amount of compounds with known effects. This problem is relieved with a technique called Applicability Domain (AD), which rejects the unsuitable compounds for the model. Adversarial examples are intentionally crafted inputs that exploit the blind spots which the model has not learned to classify, and adversarial defences try to make the classifier more robust by covering these blind spots. There is an apparent similarity between AD and adversarial defences. Inspired by the concept of AD, we propose a multi-stage data-driven defence that is testing for: Applicability: abnormal values, namely inputs not compliant with the intended use case of the model; Reliability: samples far from the training data; and Decidability: samples whose predictions contradict the predictions of their neighbours.It can be applied to any classification model and is not limited to specific types of adversarial attacks. With an empirical analysis, this paper demonstrates how Applicability Domain can effectively reduce the vulnerability of ML models to adversarial examples.