 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational decomposition autoencoding improves disentanglement of latent representations
Jan 11, 2026Understanding the structure of complex, nonstationary, high-dimensional time-evolving signals is a central challenge in scientific data analysis. In many domains, such as speech and biomedical signal processing, the ability to learn disentangled and interpretable representations is critical for uncovering latent generative mechanisms. Traditional approaches to unsupervised representation learning, including variational autoencoders (VAEs), often struggle to capture the temporal and spectral diversity inherent in such data. Here we introduce variational decomposition autoencoding (VDA), a framework that extends VAEs by incorporating a strong structural bias toward signal decomposition. VDA is instantiated through variational decomposition autoencoders (DecVAEs), i.e., encoder-only neural networks that combine a signal decomposition model, a contrastive self-supervised task, and variational prior approximation to learn multiple latent subspaces aligned with time-frequency characteristics. We demonstrate the effectiveness of DecVAEs on simulated data and three publicly available scientific datasets, spanning speech recognition, dysarthria severity evaluation, and emotional speech classification. Our results demonstrate that DecVAEs surpass state-of-the-art VAE-based methods in terms of disentanglement quality, generalization across tasks, and the interpretability of latent encodings. These findings suggest that decomposition-aware architectures can serve as robust tools for extracting structured representations from dynamic signals, with potential applications in clinical diagnostics, human-computer interaction, and adaptive neurotechnologies.
CochCeps-Augment: A Novel Self-Supervised Contrastive Learning Using Cochlear Cepstrum-based Masking for Speech Emotion Recognition
Feb 10, 2024

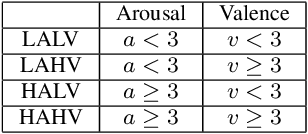

Self-supervised learning (SSL) for automated speech recognition in terms of its emotional content, can be heavily degraded by the presence noise, affecting the efficiency of modeling the intricate temporal and spectral informative structures of speech. Recently, SSL on large speech datasets, as well as new audio-specific SSL proxy tasks, such as, temporal and frequency masking, have emerged, yielding superior performance compared to classic approaches drawn from the image augmentation domain. Our proposed contribution builds upon this successful paradigm by introducing CochCeps-Augment, a novel bio-inspired masking augmentation task for self-supervised contrastive learning of speech representations. Specifically, we utilize the newly introduced bio-inspired cochlear cepstrogram (CCGRAM) to derive noise robust representations of input speech, that are then further refined through a self-supervised learning scheme. The latter employs SimCLR to generate contrastive views of a CCGRAM through masking of its angle and quefrency dimensions. Our experimental approach and validations on the emotion recognition K-EmoCon benchmark dataset, for the first time via a speaker-independent approach, features unsupervised pre-training, linear probing and fine-tuning. Our results potentiate CochCeps-Augment to serve as a standard tool in speech emotion recognition analysis, showing the added value of incorporating bio-inspired masking as an informative augmentation task for self-supervision. Our code for implementing CochCeps-Augment will be made available at: https://github.com/GiannisZgs/CochCepsAugment.
Memento: Facilitating Effortless, Efficient, and Reliable ML Experiments
Apr 17, 2023Running complex sets of machine learning experiments is challenging and time-consuming due to the lack of a unified framework. This leaves researchers forced to spend time implementing necessary features such as parallelization, caching, and checkpointing themselves instead of focussing on their project. To simplify the process, in this paper, we introduce Memento, a Python package that is designed to aid researchers and data scientists in the efficient management and execution of computationally intensive experiments. Memento has the capacity to streamline any experimental pipeline by providing a straightforward configuration matrix and the ability to concurrently run experiments across multiple threads. A demonstration of Memento is available at: https://wickerlab.org/publication/memento.