 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Reinforcement and Model Predictive Control Switching for Safe Human-Robot Cooperative Navigation
Jan 23, 2026This paper addresses the challenge of human-guided navigation for mobile collaborative robots under simultaneous proximity regulation and safety constraints. We introduce Adaptive Reinforcement and Model Predictive Control Switching (ARMS), a hybrid learning-control framework that integrates a reinforcement learning follower trained with Proximal Policy Optimization (PPO) and an analytical one-step Model Predictive Control (MPC) formulated as a quadratic program safety filter. To enable robust perception under partial observability and non-stationary human motion, ARMS employs a decoupled sensing architecture with a Long Short-Term Memory (LSTM) temporal encoder for the human-robot relative state and a spatial encoder for 360-degree LiDAR scans. The core contribution is a learned adaptive neural switcher that performs context-aware soft action fusion between the two controllers, favoring conservative, constraint-aware QP-based control in low-risk regions while progressively shifting control authority to the learned follower in highly cluttered or constrained scenarios where maneuverability is critical, and reverting to the follower action when the QP becomes infeasible. Extensive evaluations against Pure Pursuit, Dynamic Window Approach (DWA), and an RL-only baseline demonstrate that ARMS achieves an 82.5 percent success rate in highly cluttered environments, outperforming DWA and RL-only approaches by 7.1 percent and 3.1 percent, respectively, while reducing average computational latency by 33 percent to 5.2 milliseconds compared to a multi-step MPC baseline. Additional simulation transfer in Gazebo and initial real-world deployment results further indicate the practicality and robustness of ARMS for safe and efficient human-robot collaboration. Source code and a demonstration video are available at https://github.com/21ning/ARMS.git.
Cooperative Hybrid Multi-Agent Pathfinding Based on Shared Exploration Maps
Mar 28, 2025Multi-Agent Pathfinding is used in areas including multi-robot formations, warehouse logistics, and intelligent vehicles. However, many environments are incomplete or frequently change, making it difficult for standard centralized planning or pure reinforcement learning to maintain both global solution quality and local flexibility. This paper introduces a hybrid framework that integrates D* Lite global search with multi-agent reinforcement learning, using a switching mechanism and a freeze-prevention strategy to handle dynamic conditions and crowded settings. We evaluate the framework in the discrete POGEMA environment and compare it with baseline methods. Experimental outcomes indicate that the proposed framework substantially improves success rate, collision rate, and path efficiency. The model is further tested on the EyeSim platform, where it maintains feasible Pathfinding under frequent changes and large-scale robot deployments.
Enhancing Screen Time Identification in Children with a Multi-View Vision Language Model and Screen Time Tracker
Oct 02, 2024



Being able to accurately monitor the screen exposure of young children is important for research on phenomena linked to screen use such as childhood obesity, physical activity, and social interaction. Most existing studies rely upon self-report or manual measures from bulky wearable sensors, thus lacking efficiency and accuracy in capturing quantitative screen exposure data. In this work, we developed a novel sensor informatics framework that utilizes egocentric images from a wearable sensor, termed the screen time tracker (STT), and a vision language model (VLM). In particular, we devised a multi-view VLM that takes multiple views from egocentric image sequences and interprets screen exposure dynamically. We validated our approach by using a dataset of children's free-living activities, demonstrating significant improvement over existing methods in plain vision language models and object detection models. Results supported the promise of this monitoring approach, which could optimize behavioral research on screen exposure in children's naturalistic settings.
CoRA: Optimizing Low-Rank Adaptation with Common Subspace of Large Language Models
Aug 31, 2024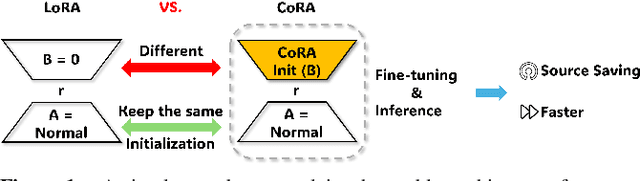
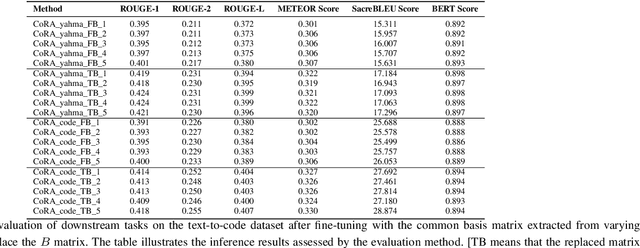
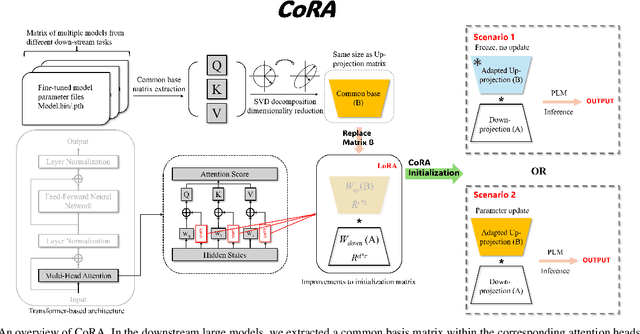
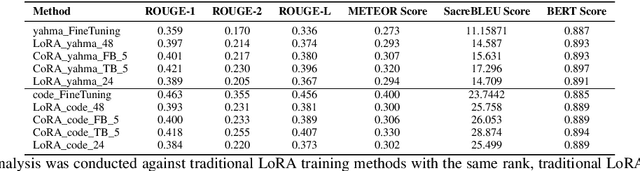
In fine-tuning large language models (LLMs), conserving computational resources while maintaining effectiveness and improving outcomes within the same computational constraints is crucial. The Low-Rank Adaptation (LoRA) strategy balances efficiency and performance in fine-tuning large models by reducing the number of trainable parameters and computational costs. However, current advancements in LoRA might be focused on its fine-tuning methodologies, with not as much exploration as might be expected into further compression of LoRA. Since most of LoRA's parameters might still be superfluous, this may lead to unnecessary wastage of computational resources. In this paper, we propose \textbf{CoRA}: leveraging shared knowledge to optimize LoRA training by substituting its matrix $B$ with a common subspace from large models. Our two-fold method includes (1) Freezing the substitute matrix $B$ to halve parameters while training matrix $A$ for specific tasks and (2) Using the substitute matrix $B$ as an enhanced initial state for the original matrix $B$, achieving improved results with the same parameters. Our experiments show that the first approach achieves the same efficacy as the original LoRA fine-tuning while being more efficient than halving parameters. At the same time, the second approach has some improvements compared to LoRA's original fine-tuning performance. They generally attest to the effectiveness of our work.